六个小时的比赛时间还是太短了,流量分析可惜了,看了下其实并不难,但是一个人看几十万条的大流量分析还是太吃力了......
好在社工算是ak了,多少拉了点分:) 完了这下成开盒大王了
Writeup部分
溯源与取证
别的大师傅做的,这里就写复现里了Orz
数据社工
1
要找的是居住地和公司,根据其他任务已经知道了公司,要找的只有居住地,根据手机号等很容易在打车数据里面找到相关经纬度,从而在地图数据中找到小区。
img
img
img
img
华润国际E区:闵行区星辰信息技术园
2
要求找公司名称,通过任务3知道了手机号,在快递单中查找知道了是什么博林科技的
img
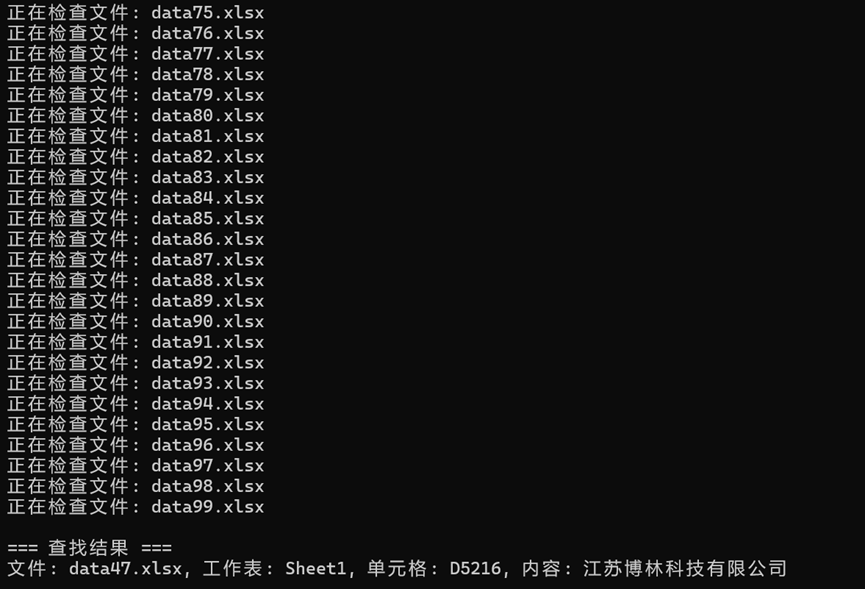
写个python脚本在工商登记数据里找博林
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import openpyxlimport osdef find_string_in_multiple_excels (folder_path, target_string ): try : results = [] for i in range (100 ): file_name = f"data{i} .xlsx" file_path = os.path.join(folder_path, file_name) if not os.path.exists(file_path): print (f"文件不存在: {file_path} " ) continue print (f"正在检查文件: {file_name} " ) workbook = openpyxl.load_workbook(file_path) for sheet_name in workbook.sheetnames: sheet = workbook[sheet_name] for row in sheet.iter_rows(): for cell in row: if cell.value and target_string in str (cell.value): result = { "文件名" : file_name, "工作表" : sheet_name, "单元格位置" : cell.coordinate, "单元格内容" : cell.value } results.append(result) print (f"找到匹配项 - 文件: {file_name} , 工作表: {sheet_name} , 单元格: {cell.coordinate} , 内容: {cell.value} " ) if not results: print ("未找到匹配的字符串。" ) else : print ("\n=== 查找结果 ===" ) for res in results: print (f"文件: {res['文件名' ]} , 工作表: {res['工作表' ]} , 单元格: {res['单元格位置' ]} , 内容: {res['单元格内容' ]} " ) except Exception as e: print (f"发生错误: {e} " ) if __name__ == "__main__" : folder_path = input ("请输入包含 Excel 文件的文件夹路径: " ).strip() search_string = input ("请输入要查找的字符串: " ).strip() find_string_in_multiple_excels(folder_path, search_string)
img
江苏博林科技有限公司
3
要找手机号,已知姓名,去爬取的网页中找
img
13891889377
4
要找身份证号,已知手机号,仍然去爬取的网页中找
img
61050119980416547X
5
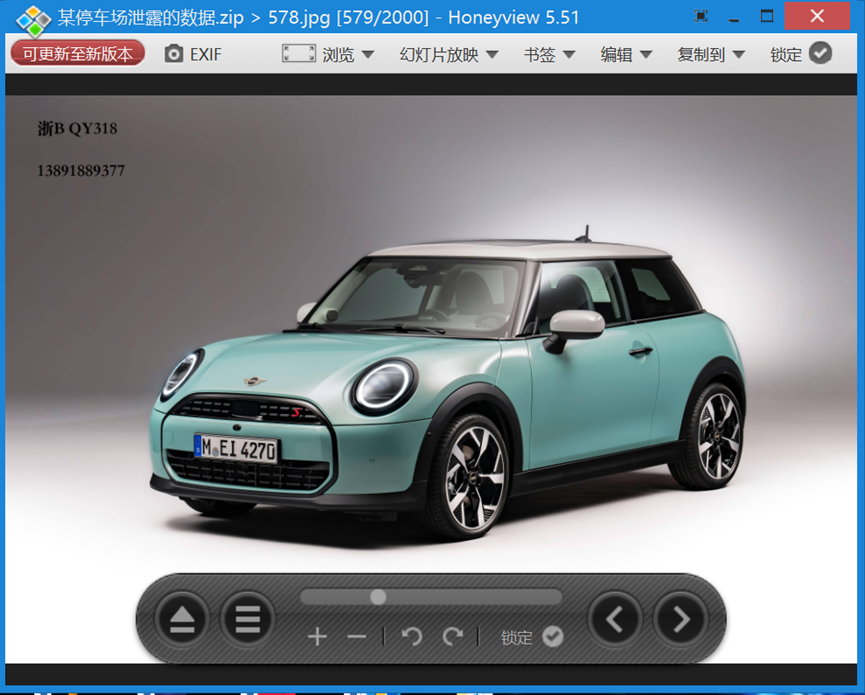
要车牌号,已知手机号,去停车场数据中找,手动硬找,总能找到:)
578.jpg
img
浙B QY318
数据攻防
1
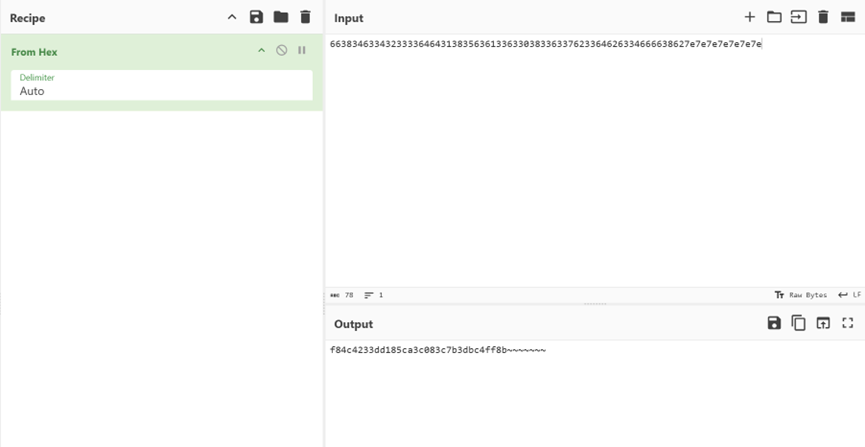
分析流量发现后面有大量的部分是在进行布尔盲注,把注入得到的结果还原出来就好
img
img
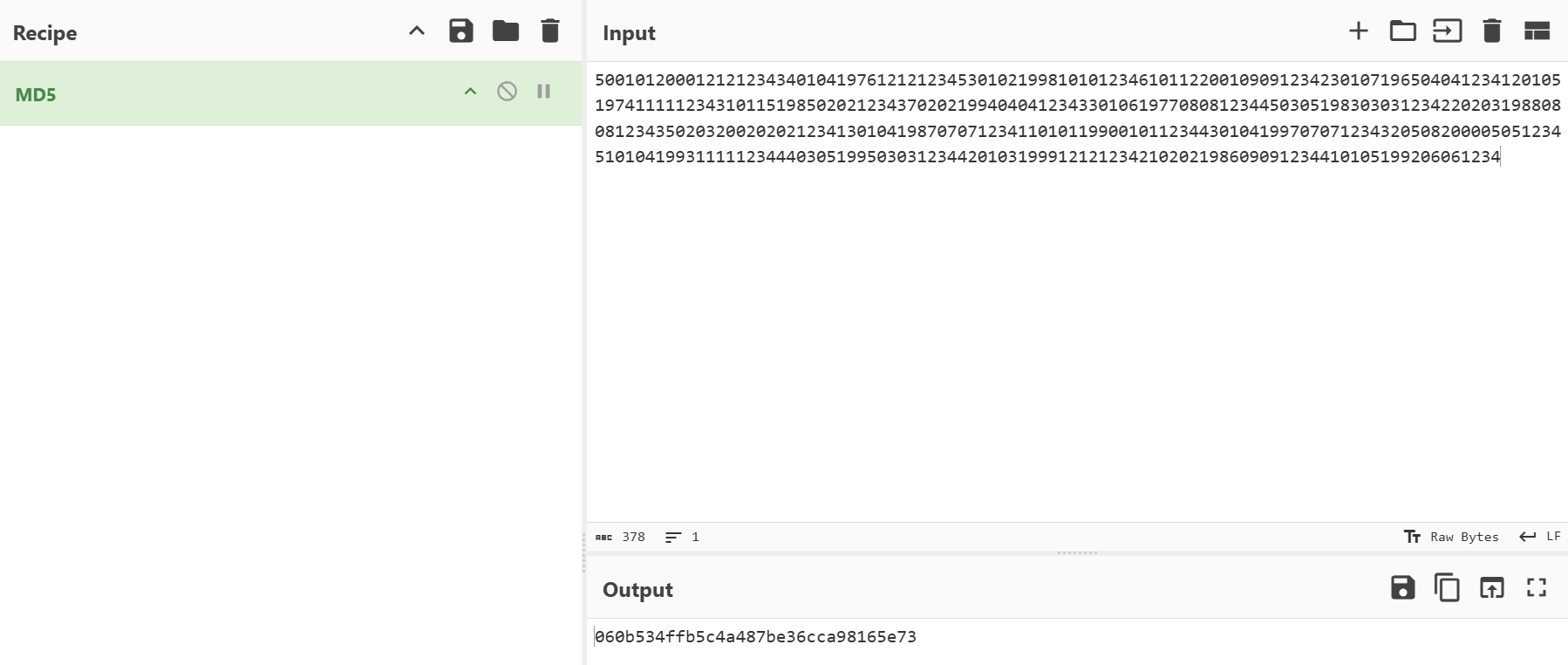
f84c4233dd185ca3c083c7b3dbc4ff8b
数据跨境
完全没来得及看。。。
复现部分
溯源与取证
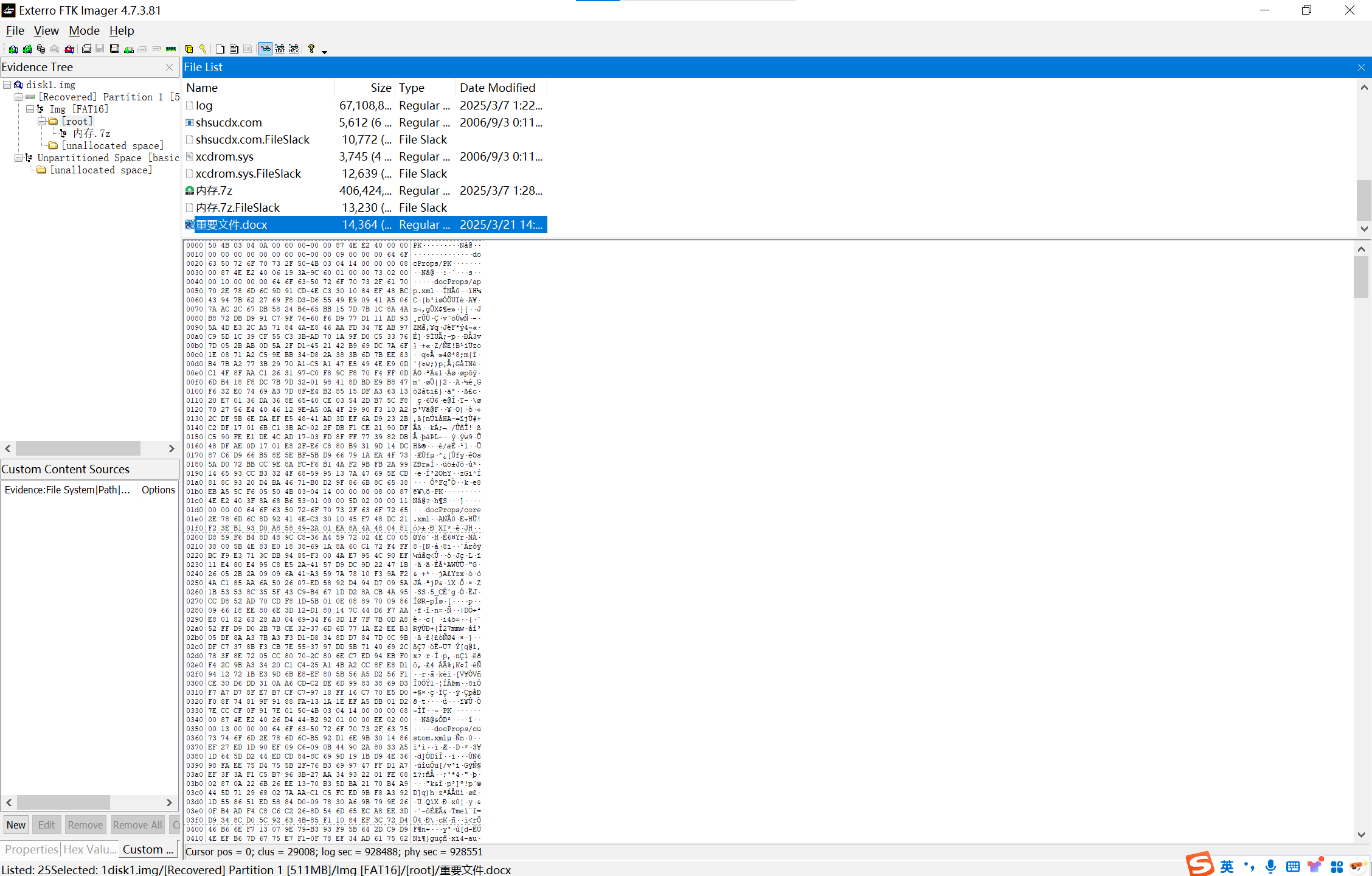
1
用ftk挂载就能看到docx文档
img
提取出来打开以后不难发现有一段白色文字,改下颜色就行
img
2
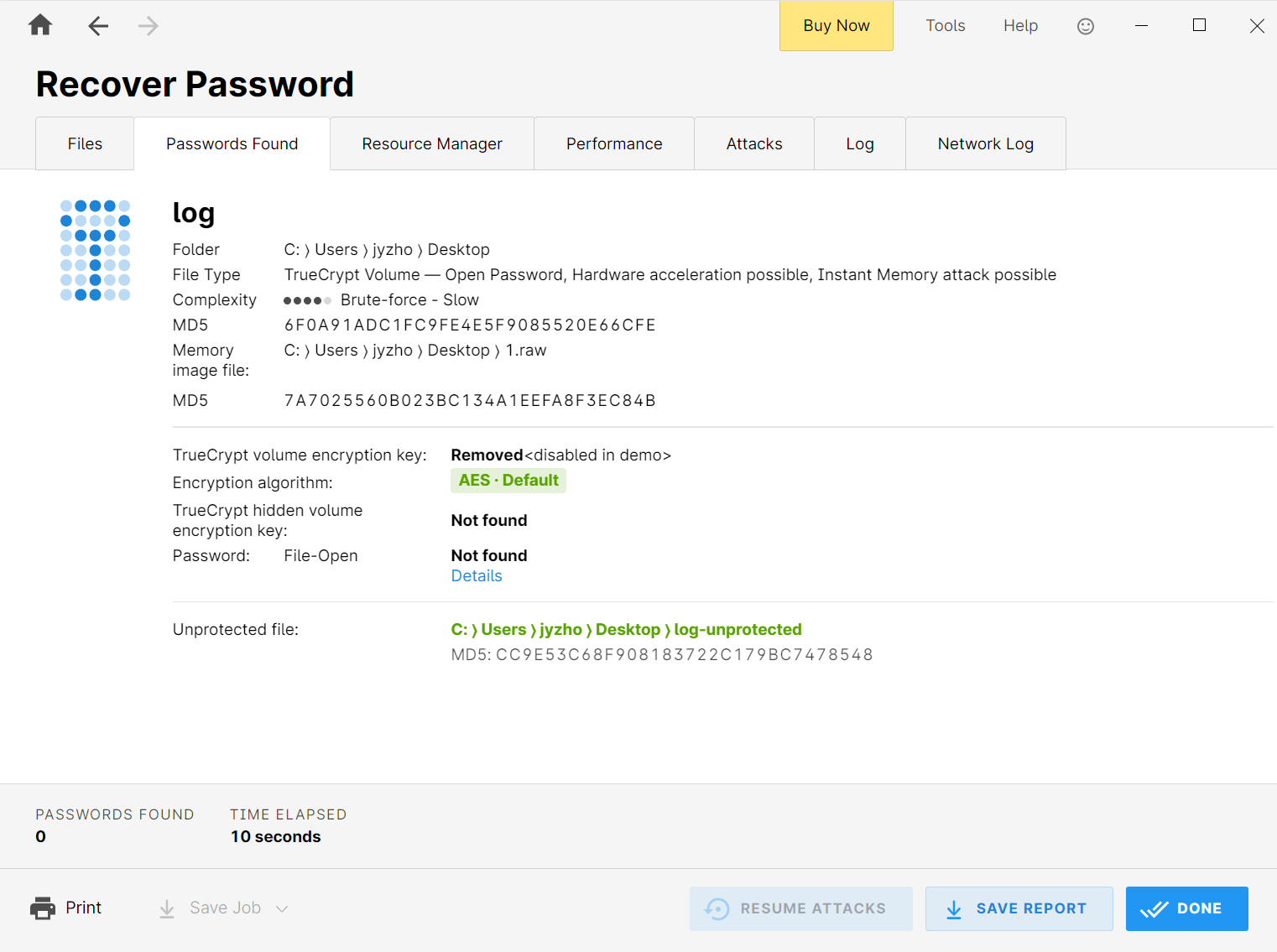
上面可以看到img里还有个内存.7z,导出以后解压发现是个windows内存镜像。另外还有个log,应该就是题目所说的加密磁盘。通过vol等分析不难发现是truecrypt加密的,用passware
kit恢复一下。
img
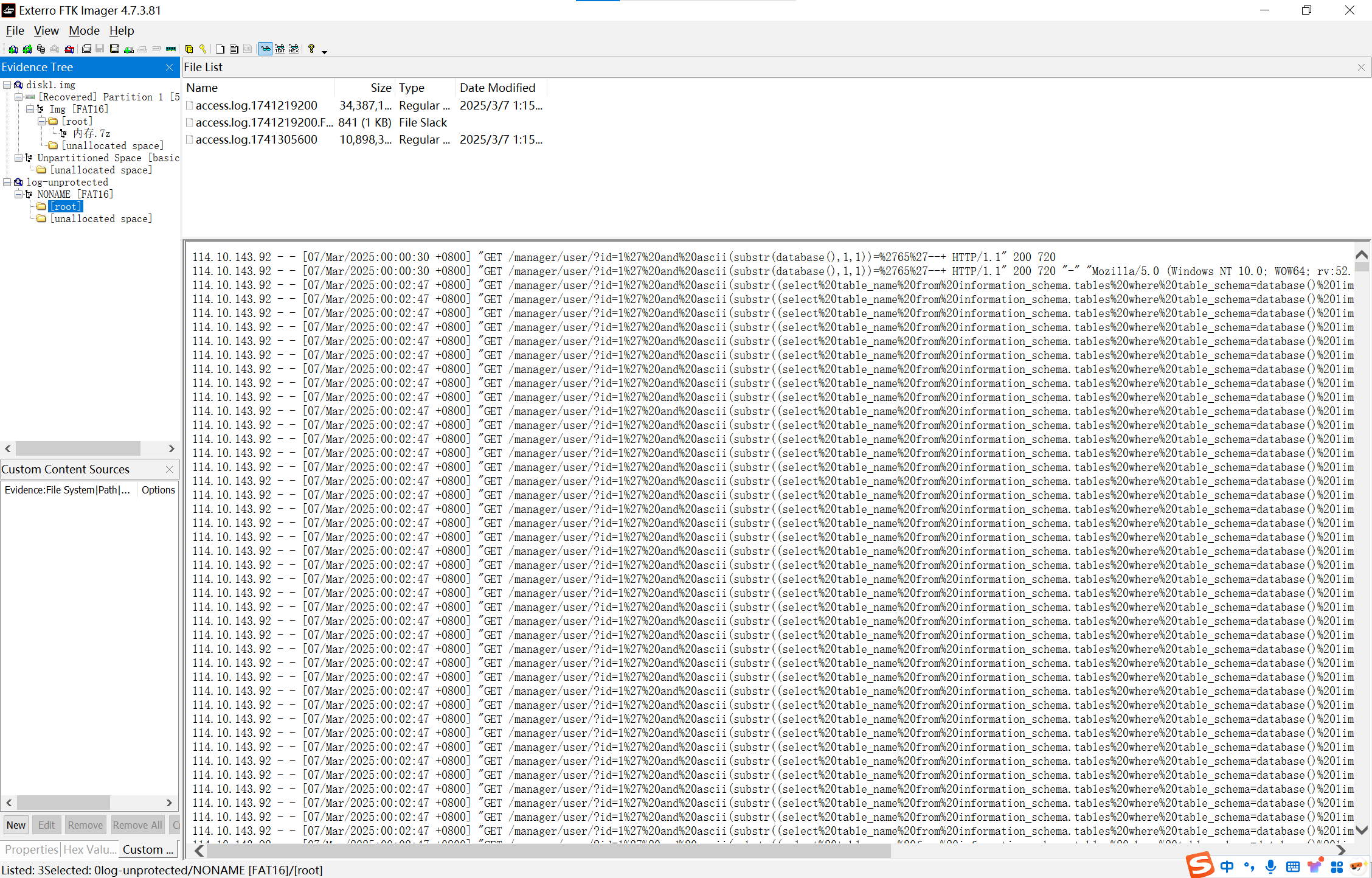
挂载到ftk上就可以看到日志文件,以及我们需要的ip
img
114.10.143.92
3
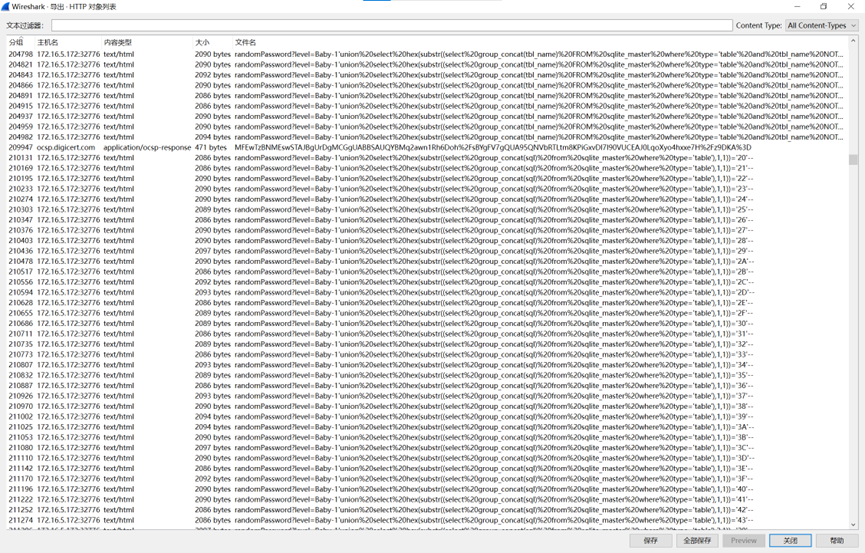
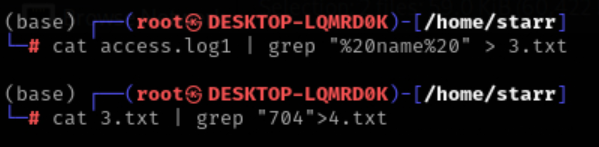
又是一大堆的布尔盲注的日志
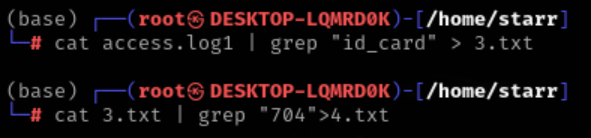
通过观察,先初步筛选一下有用的日志,找到查询id_card且返回包长度为704的
img
再找到查询name且返回包长度为704的
img
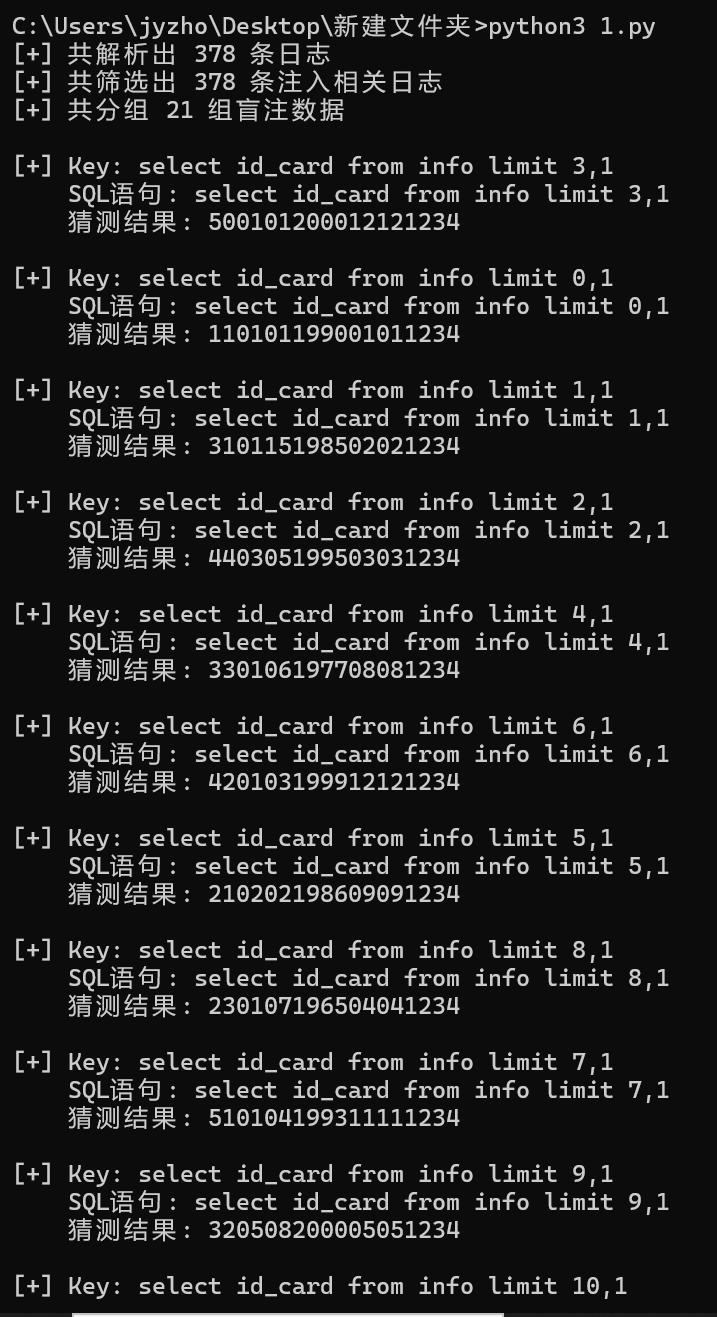
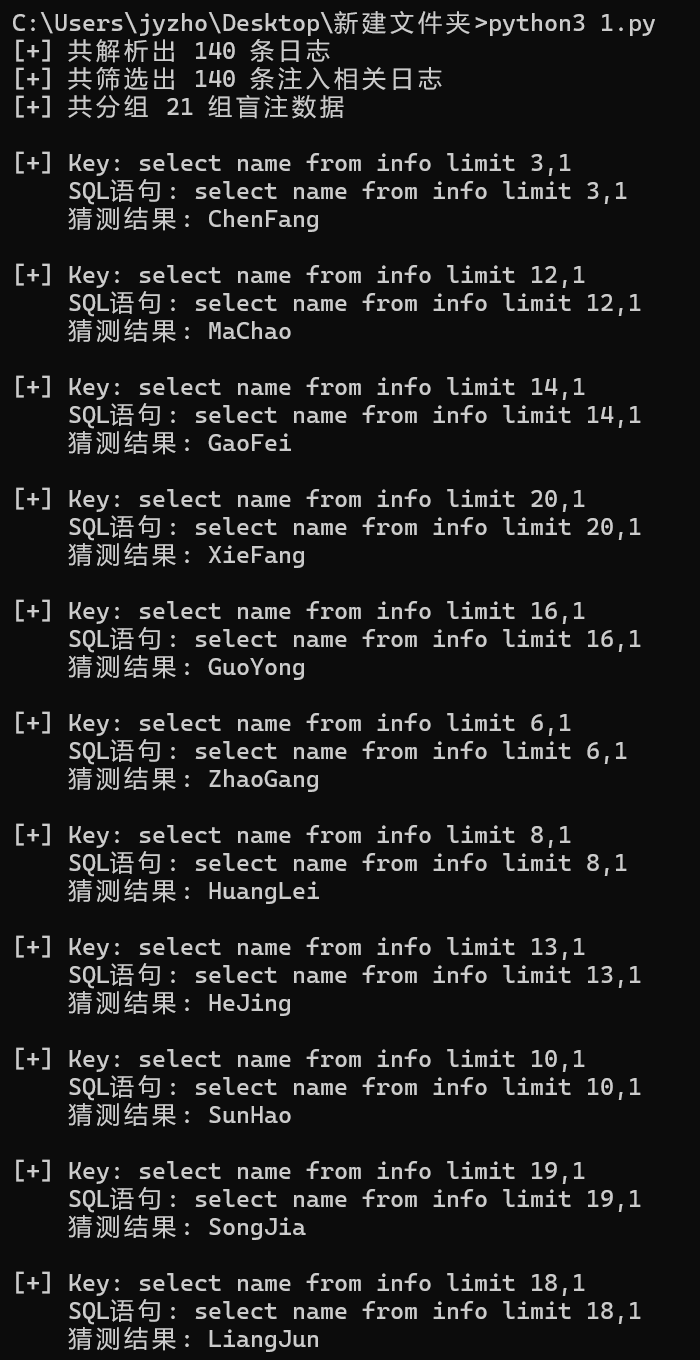
写脚本还原攻击者得到的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 import refrom urllib.parse import unquotefrom collections import defaultdictfrom typing import Dict , List , Optional LOG_PATTERN = re.compile ( r'(?P<client_ip>\d+\.\d+\.\d+\.\d+)\s-\s-\s' r'\[(?P<timestamp>.*?)\]\s' r'"(?P<method>\w+)\s(?P<path>[^\s]+)\sHTTP/1.1"\s' r'(?P<status>\d+)\s(?P<size>\d+)\s' r'"(?P<referrer>.*?)"\s' r'"(?P<user_agent>.*?)"' ) SQL_INJ_PATTERN = re.compile (r"substr\(\((.*?)\),(\d+),\d+\)\)=(\d+)" ) def parse_logs (file_path: str ) -> List [Dict [str , any ]]: """解析日志文件并返回结构化数据""" logs = [] try : with open (file_path, 'r' , encoding='utf-8' ) as f: for line in f: match = LOG_PATTERN.match (line.strip()) if match : log = match .groupdict() log['status' ] = int (log['status' ]) log['size' ] = int (log['size' ]) log['path' ] = unquote(log['path' ]) logs.append(log) except FileNotFoundError: print (f"[-] 文件 {file_path} 未找到" ) return [] except Exception as e: print (f"[-] 解析日志时发生错误: {e} " ) return [] print (f"[+] 共解析出 {len (logs)} 条日志" ) return logs def filter_injection_logs (logs: List [Dict [str , any ]] ) -> List [Dict [str , any ]]: """筛选可能包含 SQL 注入的日志""" filtered = [ log for log in logs if log['path' ].startswith('/manager/user/?' ) and '--' in log['path' ] ] print (f"[+] 共筛选出 {len (filtered)} 条注入相关日志" ) return filtered def extract_blind_sql_data (logs: List [Dict [str , any ]] ) -> Dict [str , Dict [str , any ]]: """提取盲注数据并分组""" grouped = defaultdict(lambda : {'sql' : '' , 'chars' : {}}) for log in logs: match = SQL_INJ_PATTERN.search(log['path' ]) if match : sql_expr, pos, ascii_val = match .groups() pos, ascii_val = int (pos), int (ascii_val) key = sql_expr if not grouped[key]['sql' ]: grouped[key]['sql' ] = sql_expr grouped[key]['chars' ][pos] = ascii_val print (f"[+] 共分组 {len (grouped)} 组盲注数据" ) return dict (grouped) def reconstruct_data (grouped: Dict [str , Dict [str , any ]] ) -> None : """重建并输出盲注猜测结果""" for key, info in grouped.items(): sql = info['sql' ] chars = info['chars' ] if not chars: print (f"\n[+] Key: {key} " ) print (f" SQL语句: {sql} " ) print (" 猜测结果: 无数据" ) continue max_pos = max (chars.keys()) result = '' .join(chr (chars.get(i, ord ('?' ))) for i in range (1 , max_pos + 1 )) print (f"\n[+] Key: {key} " ) print (f" SQL语句: {sql} " ) print (f" 猜测结果: {result} " ) def main (file_path: str = '4.txt' ): """主函数""" logs = parse_logs(file_path) if not logs: return injection_logs = filter_injection_logs(logs) if not injection_logs: print ("[-] 未找到符合条件的注入日志" ) return blind_sql_data = extract_blind_sql_data(injection_logs) if not blind_sql_data: print ("[-] 未提取到盲注数据" ) return reconstruct_data(blind_sql_data) if __name__ == "__main__" : main()
img
img
按照要求将身份证号按姓名首字母升序排序
1 500101200012121234340104197612121234530102199810101234610112200109091234230107196504041234120105197411111234310115198502021234370202199404041234330106197708081234450305198303031234220203198808081234350203200202021234130104198707071234110101199001011234430104199707071234320508200005051234510104199311111234440305199503031234420103199912121234210202198609091234410105199206061234
img
数据社工
见writeup部分
数据攻防
2
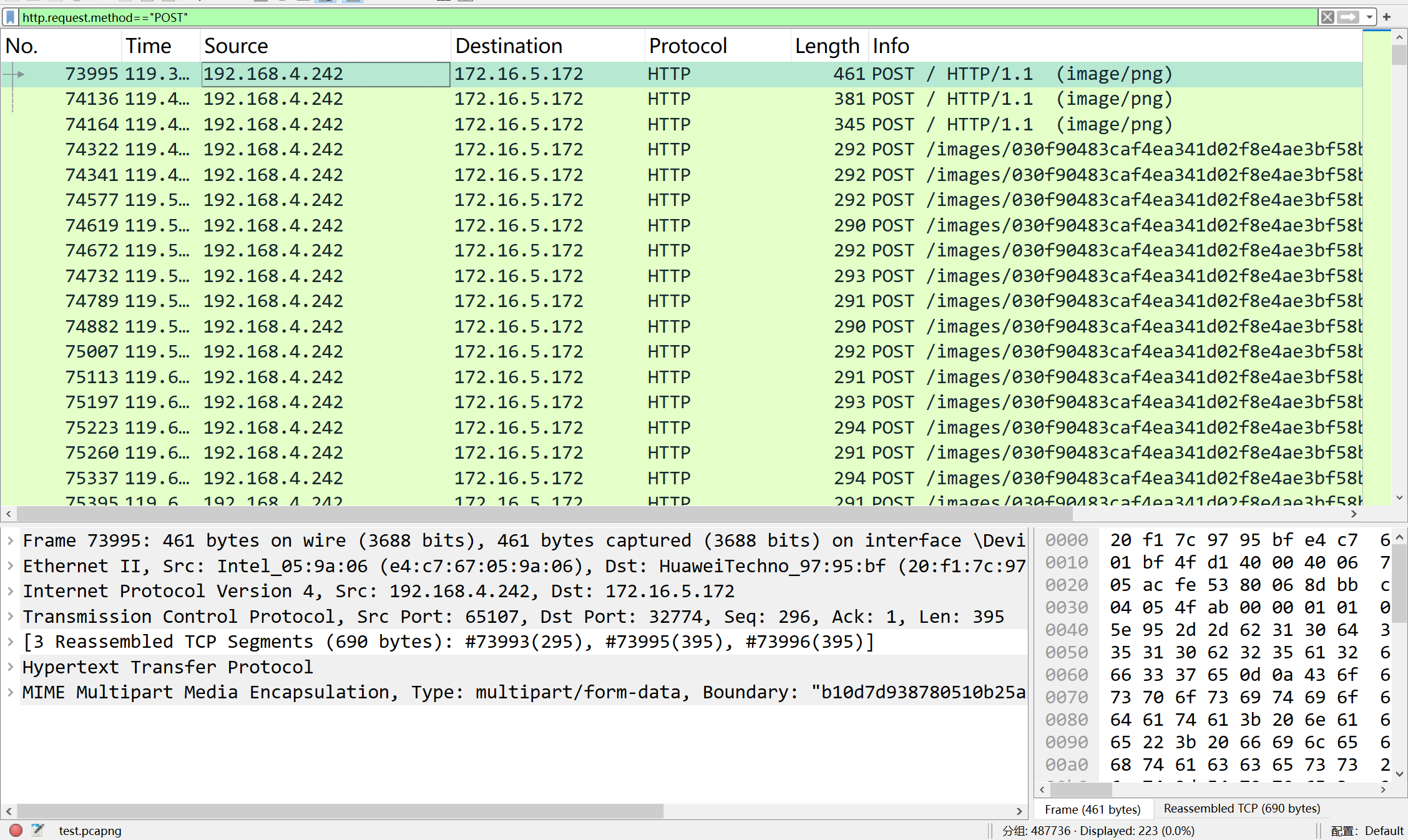
过滤POST请求流量
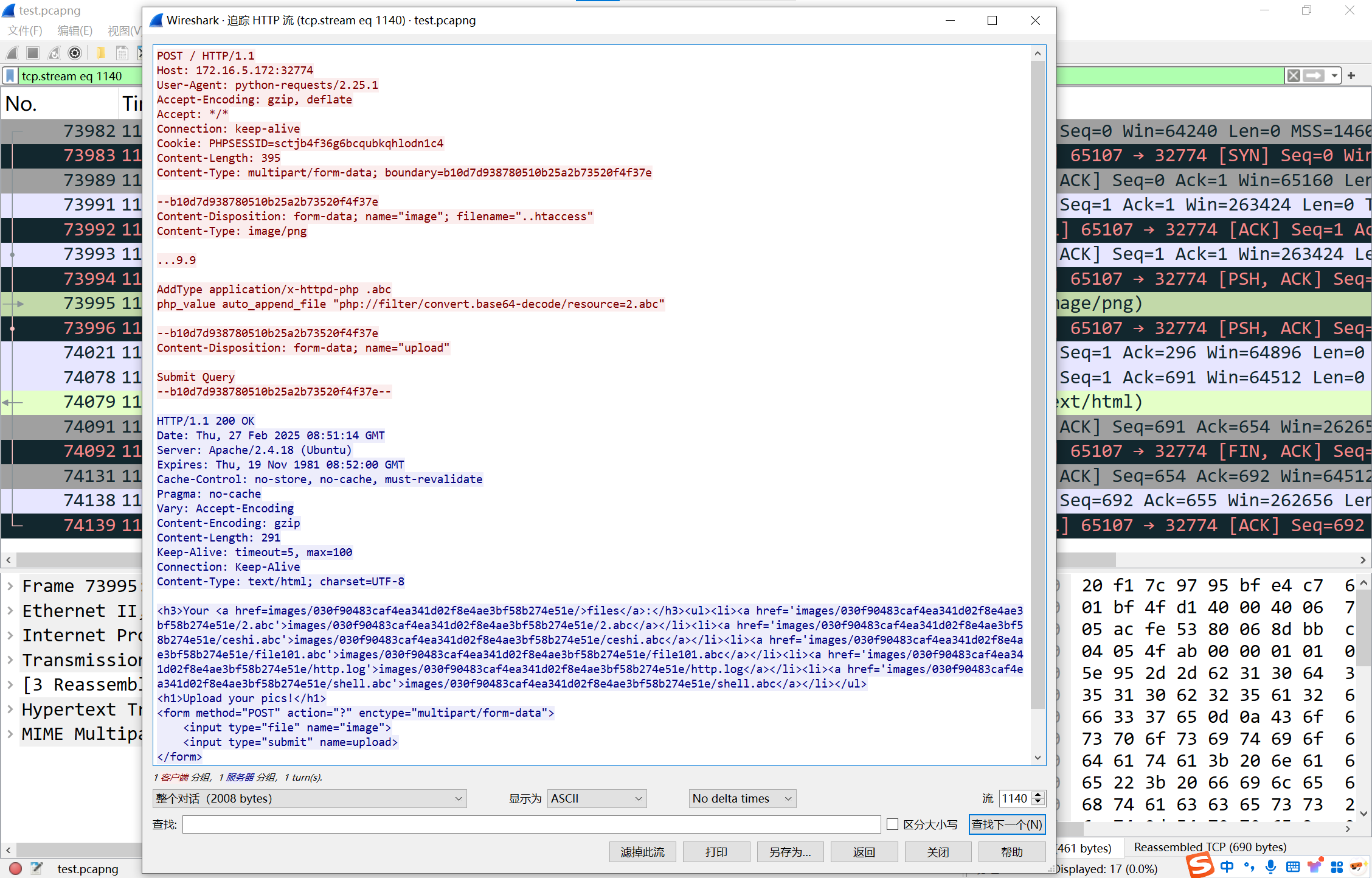
img
可有看到有一条流量是上传了.htaccess文件,调用了一个叫2.abc的文件
img
2.abc
3
可惜了当时没先看这个,占分又多又跟前面没什么关系,关键还能ai一把梭。。。
写脚本计算即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import jsonfrom collections import defaultdictcounts = defaultdict(int ) with open ('http.log' , 'r' , encoding='utf-8' ) as f: for line in f: line = line.strip() if line.startswith('{' ) and line.endswith('}' ): try : data = json.loads(line) name = data.get('name' ) phone = data.get('phone' ) if name and phone: counts[(name, phone)] += 1 except json.JSONDecodeError: continue sorted_counts = sorted (counts.items(), key=lambda x: (-x[1 ], x[0 ])) top3 = sorted_counts[:3 ] result = [f"{name} ,{phone} ,{count} " for (name, phone), count in top3] print (';' .join(result))
img
1ee668548a135dced8dadd510762525a
数据跨境
1
先导出所有的目标地址
img
写个脚本计算一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import jsonfrom collections import Counterwith open ('list.json' , 'r' , encoding='utf-8' ) as f: data = json.load(f) ip_to_domain = {} for category in data['categories' ].values(): for domain, ip in category['domains' ].items(): ip_to_domain[ip] = domain ip_counts = Counter() with open ('ip_dst.txt' , 'r' , encoding='utf-8' ) as f: for line in f: ip = line.strip() if ip: ip_counts[ip] += 1 filtered_counts = {ip: count for ip, count in ip_counts.items() if ip in ip_to_domain} if not filtered_counts: print ("在 ip_dst.txt 中没有找到 list.json 中的任何 IP 地址" ) else : most_common_ip, count = max (filtered_counts.items(), key=lambda x: x[1 ]) domain = ip_to_domain[most_common_ip] print (f"{domain} :{most_common_ip} :{count} " )
img
2
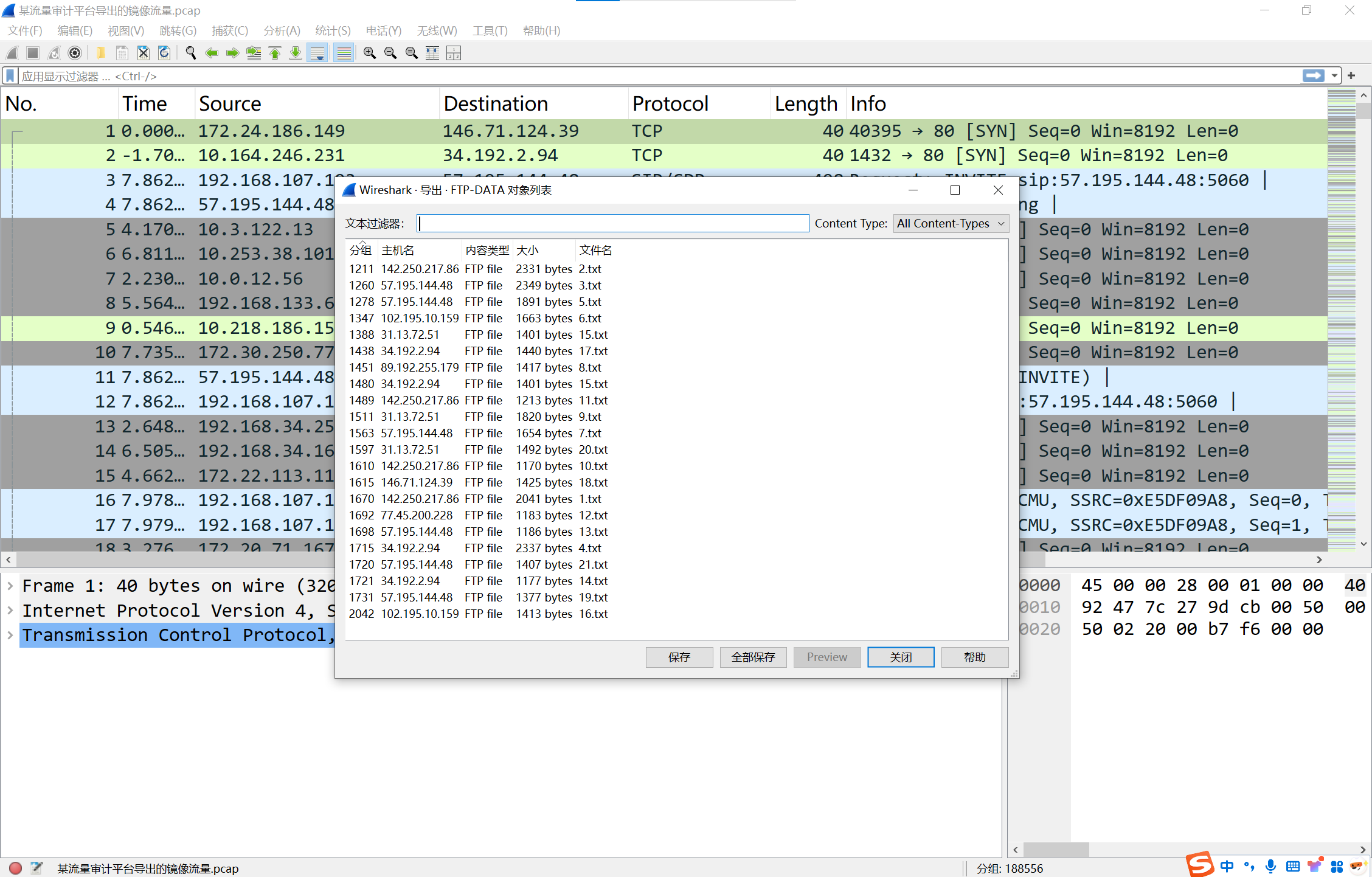
导出所有ftp传输的文件
img
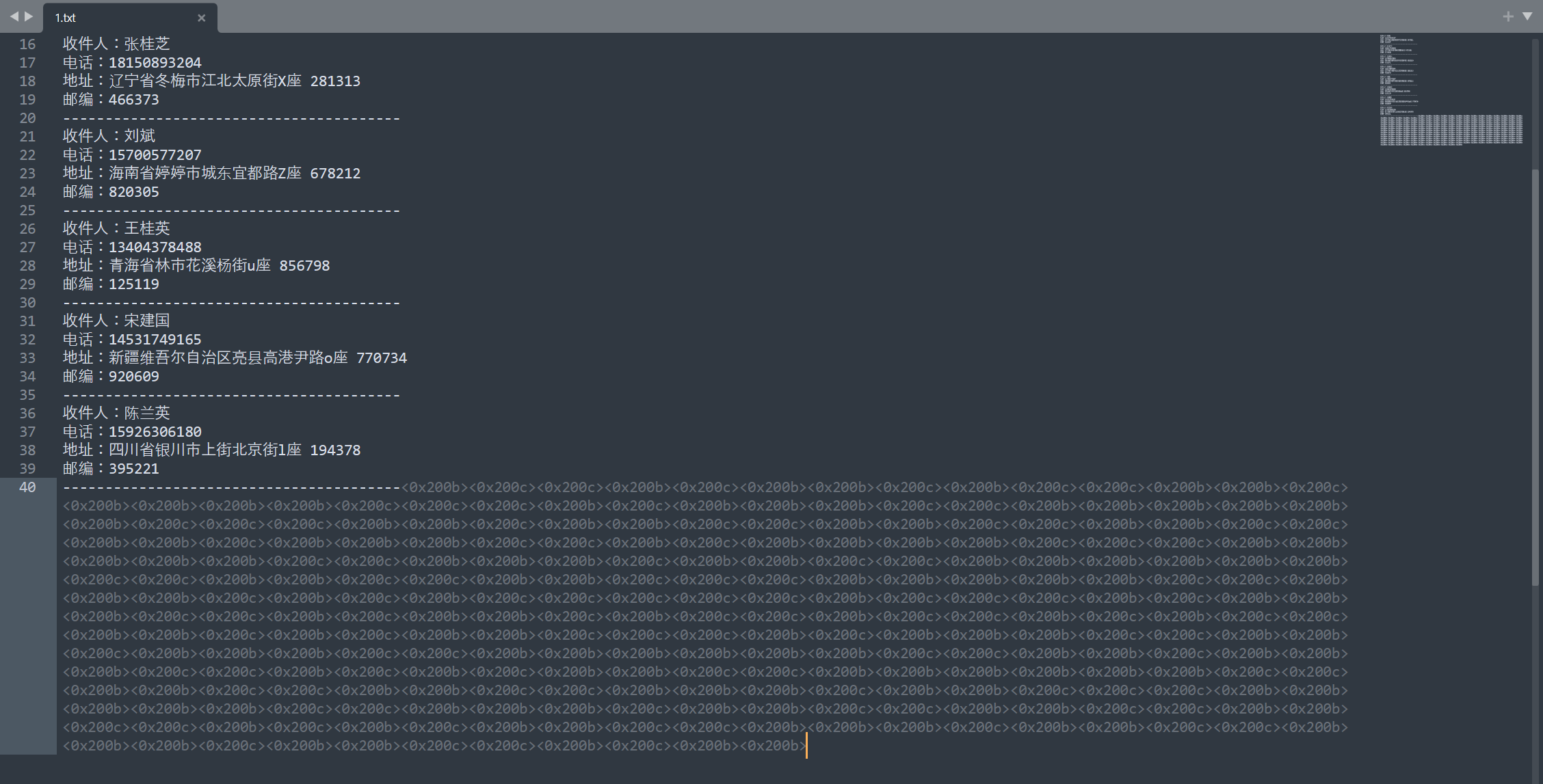
文件中存在零宽字符隐写
img
img
img
3
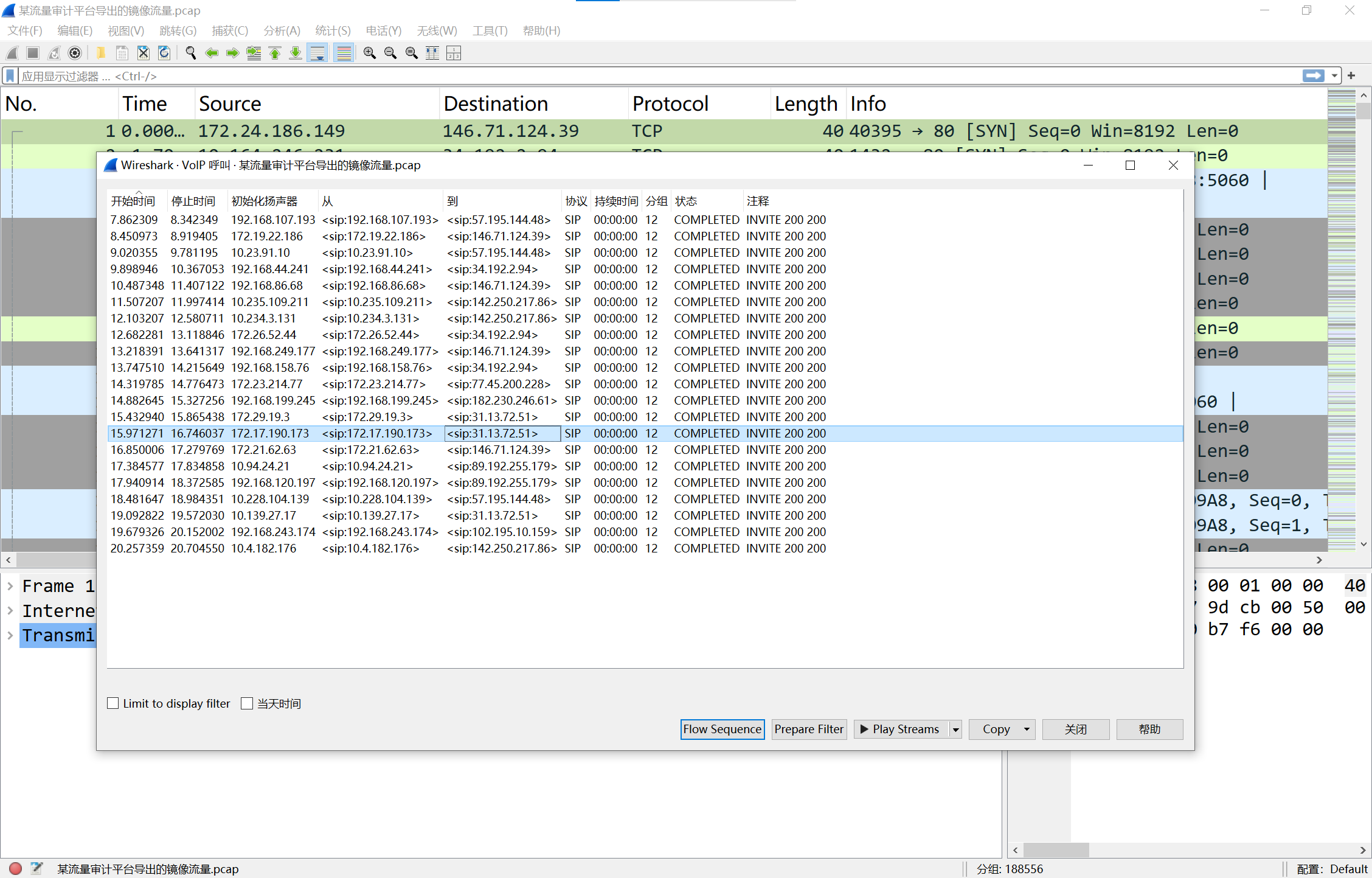
看到一大堆的rtp流,是VoIP通话
img
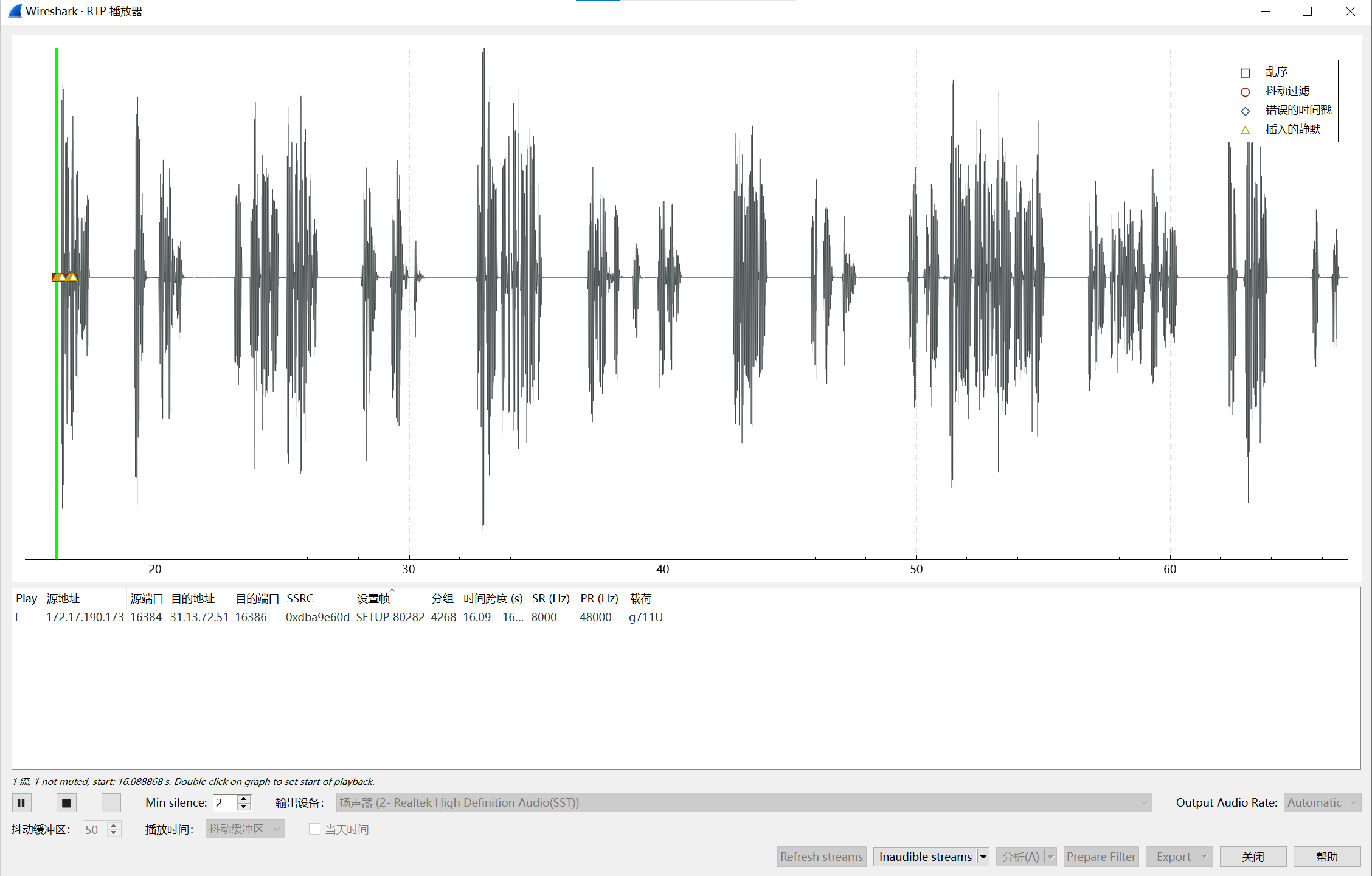
播放就可以听到两人机在那对话,其中有一条的对话中提到了答案
img
江苏工匠学院君立华域
jiangsugongjiangxueyuanjunlihuayu
复现完感觉后悔死,为什么没有先看数据跨境,而先去看了数据攻防。。。
算了还是因为我太菜了。