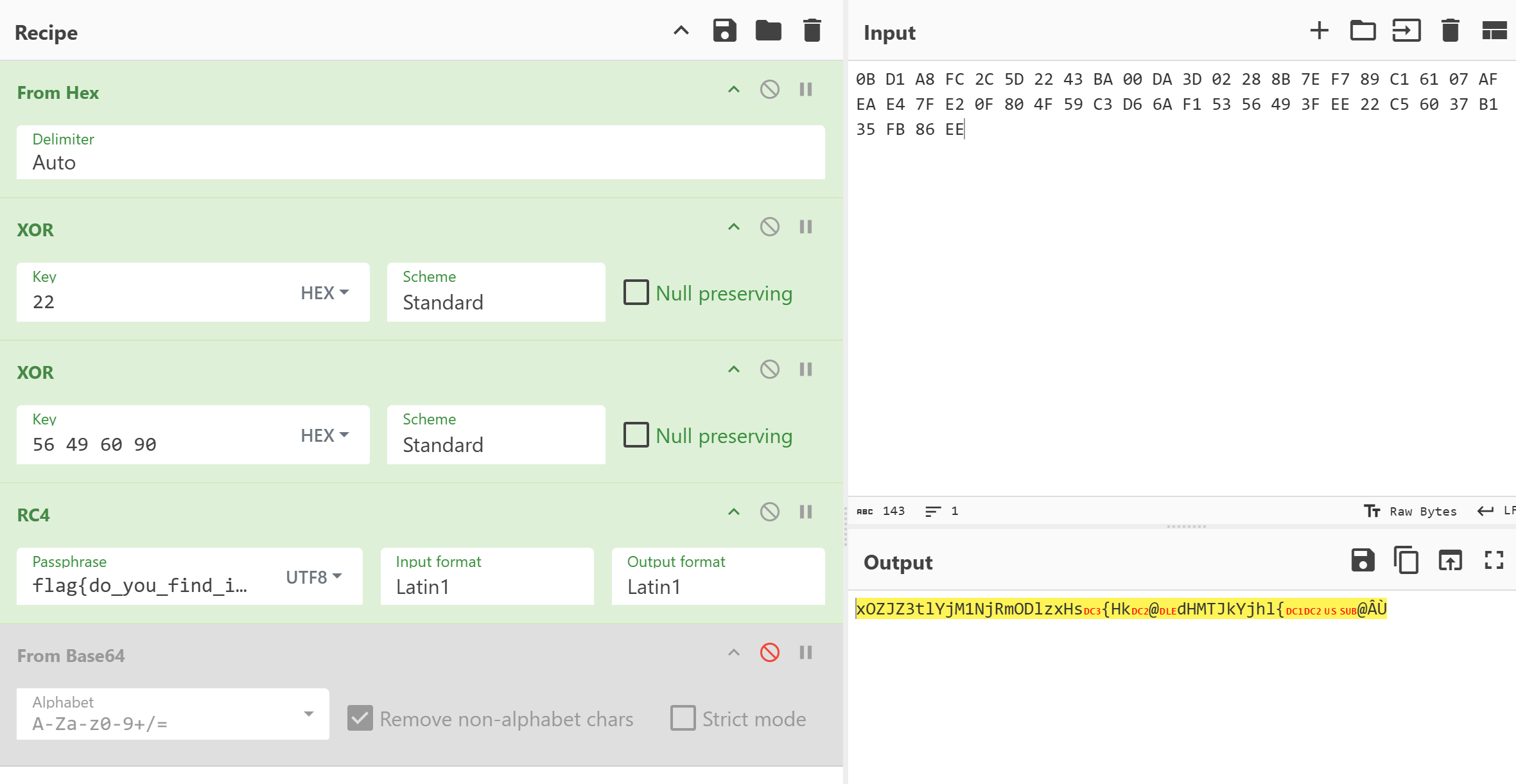
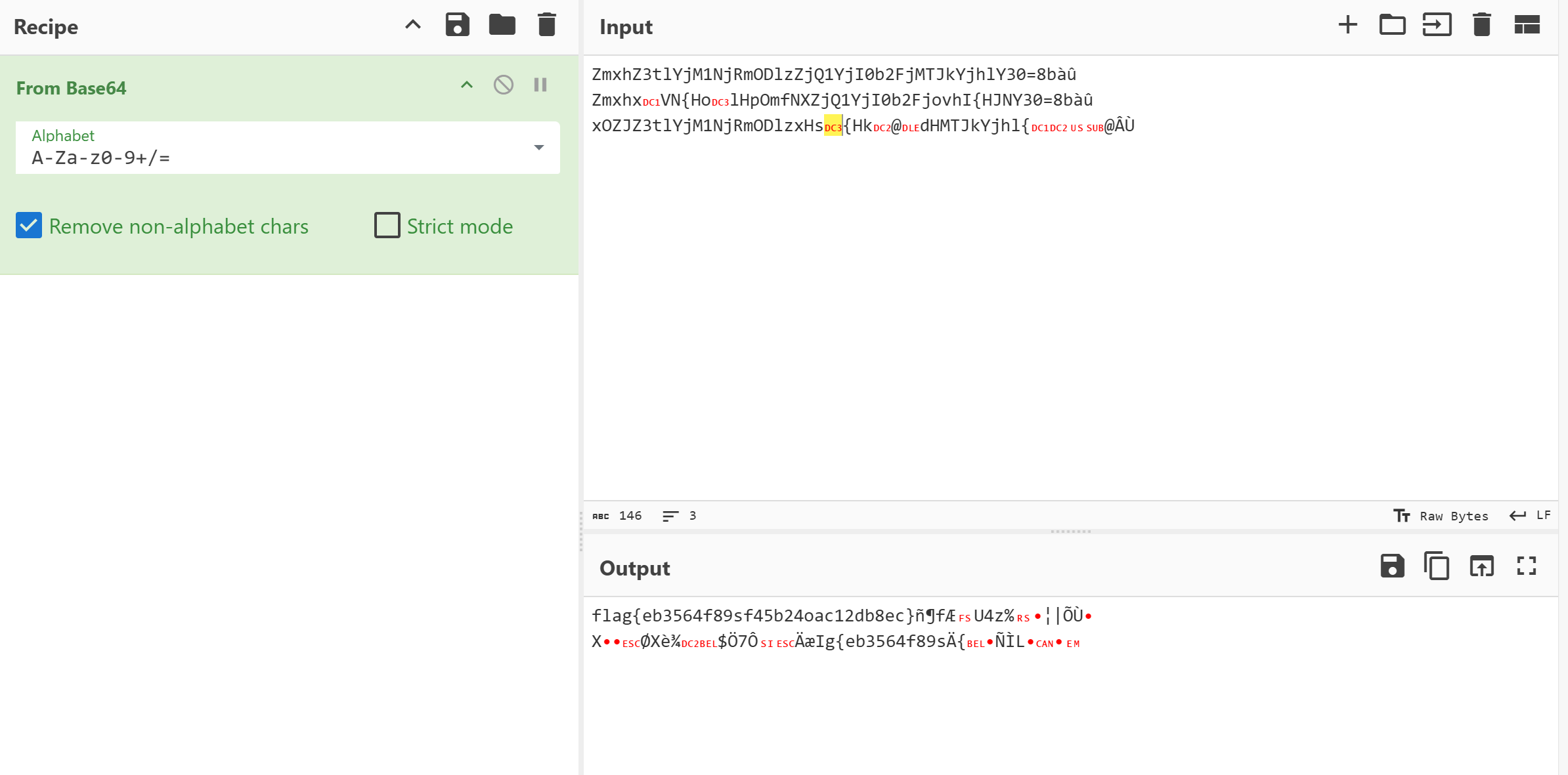
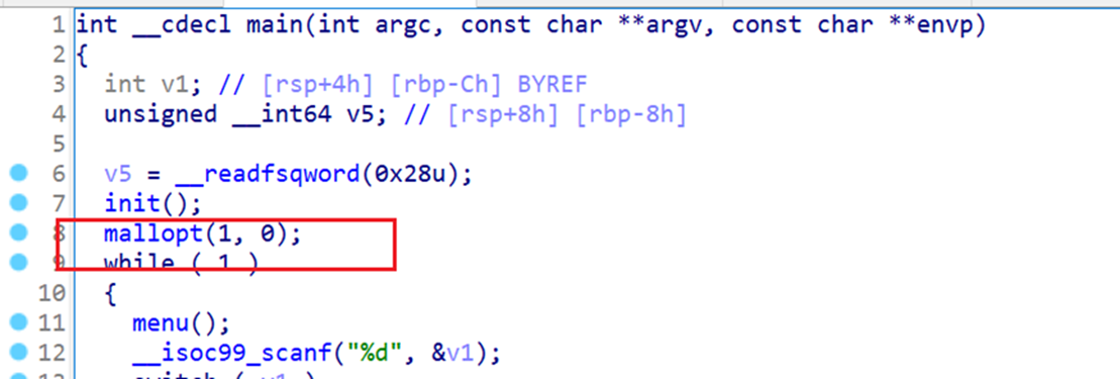
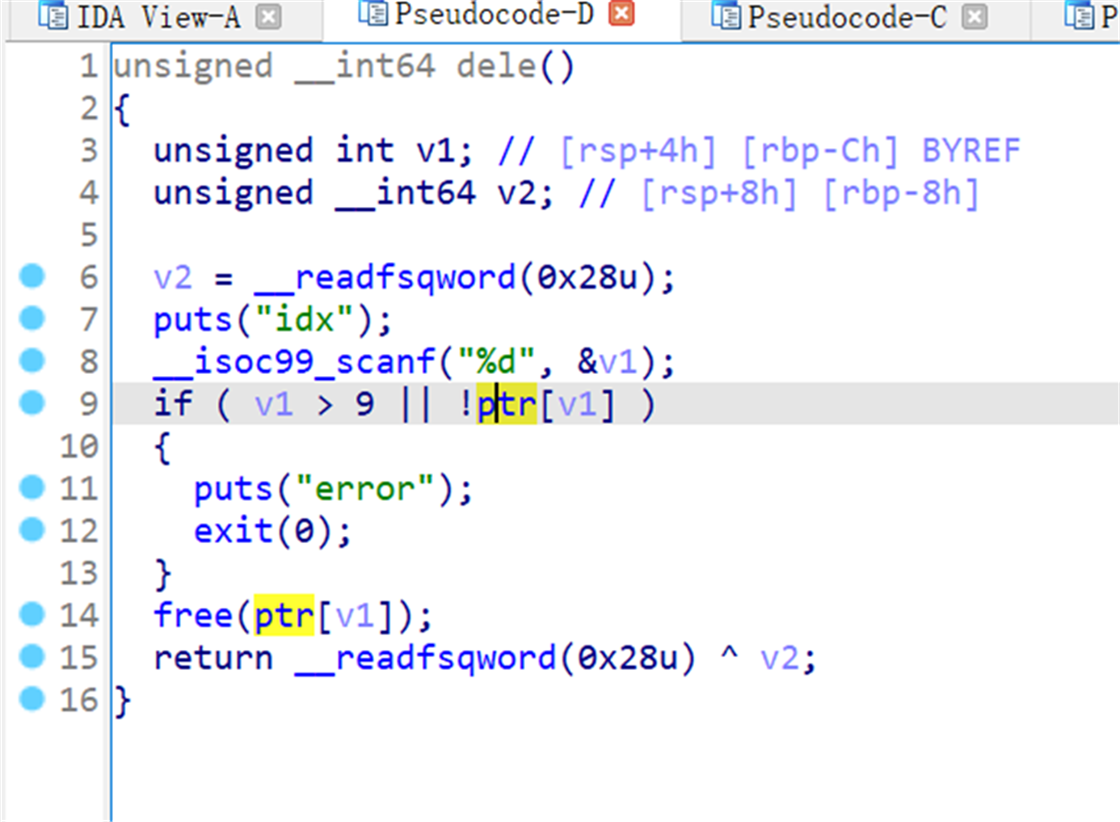
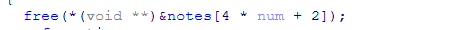1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
| import sys
from typing import List, Dict, Optional, Tuple
class VMEnvironment:
"""模拟 VM 的堆栈和数据内存"""
def __init__(self, data_size=4096):
self.stack: List[int] = []
self.data_memory = bytearray([0] * data_size)
self.data_base_addr = 0x1000
def push(self, val: int):
self.stack.append(val)
def pop(self) -> int:
if not self.stack:
raise IndexError("Stack underflow!")
return self.stack.pop()
def get_data_addr(self, offset: int) -> int:
"""根据栈上的 offset 获得 data_memory 中的实际索引"""
return offset - self.data_base_addr
def puts_terminated(self):
"""模拟 puts_Terminated (功能未知,假设打印一个换行符)"""
print("[puts_Terminated called]")
def gets_sim(self, offset: int):
"""模拟 gets(data + offset) - 注意:gets 不安全"""
try:
user_input = input(f"[gets] Enter string for data[{hex(offset)}]: ")
except EOFError:
user_input = ""
data_index = self.get_data_addr(offset)
encoded_input = user_input.encode("ascii")
for i, byte in enumerate(encoded_input):
if data_index + i < len(self.data_memory):
self.data_memory[data_index + i] = byte
if data_index + len(encoded_input) < len(self.data_memory):
self.data_memory[data_index + len(encoded_input)] = 0
def puts_sim(self, offset: int):
"""模拟 puts(data + offset)"""
data_index = self.get_data_addr(offset)
try:
null_index = self.data_memory.index(0, data_index)
output = self.data_memory[data_index:null_index].decode("ascii")
print(output)
except ValueError:
print(f"[Error] String at {hex(offset)} is not null-terminated.")
except IndexError:
print(f"[Error] Offset {hex(offset)} out of bounds.")
class VM:
OPCODE_MAP: Dict[int, Tuple[str, Optional[int], str]] = {
0x101: ("ADD", 0, "Pop Y, Pop X, Push X + Y"),
0x102: ("AND", 0, "Pop Y, Pop X, Push X & Y"),
0x103: ("PRINTS_TERM", 0, "Call puts_Terminated()"),
0x104: ("PUSH_CONST", 1, "Push next word (Immediate)"),
0x105: ("READ_INT", 0, "Read int from stdin, Push"),
0x201: ("SUB", 0, "Pop Y, Pop X, Push X - Y"),
0x202: ("OR", 0, "Pop Y, Pop X, Push X | Y"),
0x203: ("JMP", 1, "IP = Immediate >> 2 (Unconditional Jump)"),
0x204: ("POP", 0, "Pop and discard value"),
0x205: ("PRINT_INT", 0, "Pop, Print as integer"),
0x301: ("INC", 0, "Pop X, Push X + 1"),
0x302: ("NOT", 0, "Pop X, Push ~X"),
0x303: ("JMPZ", 1, "Pop C, If C == 0, IP = Immediate >> 2"),
0x304: ("LOAD_DWORD", 0, "Pop Offset, Push *(_DWORD *)(data + Offset)"),
0x305: ("READ_STR", 0, "Pop Offset, gets(data + Offset)"),
0x401: ("DEC", 0, "Pop X, Push X - 1"),
0x402: ("XOR", 0, "Pop Y, Pop X, Push X ^ Y"),
0x403: ("JMPNZ", 1, "Pop C, If C != 0, IP = Immediate >> 2"),
0x404: (
"STORE_DWORD",
0,
"Pop Value, Pop Offset, *(_DWORD *)(data + Offset) = Value",
),
0x405: ("PRINTS_MEM", 0, "Pop Offset, puts(data + Offset)"),
0x504: ("LOAD_BYTE", 0, "Pop Offset, Push *(unsigned __int8 *)(data + Offset)"),
0x604: (
"STORE_BYTE",
0,
"Pop Value, Pop Offset, *(_BYTE *)(data + Offset) = Value",
),
}
def __init__(self, bytecode: List[int], data_base_addr: int):
self.text = bytecode
self.env = VMEnvironment()
self.env.data_base_addr = (
data_base_addr
)
def disassemble(self):
"""将字节码转换为汇编指令列表"""
disassembly_output = []
ip = 0
while ip < len(self.text):
opcode = self.text[ip]
info = self.OPCODE_MAP.get(opcode)
if info:
name, operands, _ = info
instruction_addr = ip * 4
if operands == 1:
if ip + 1 < len(self.text):
operand = self.text[ip + 1]
if name in ["JMP", "JMPZ", "JMPNZ"]:
target_ip = operand >> 2
asm = f"{name} {target_ip:X}h (0x{operand:X})"
else:
asm = f"{name} 0x{operand:X}"
disassembly_output.append(
f"0x{instruction_addr:08X} {hex(opcode)}: {asm}"
)
ip += 2
else:
disassembly_output.append(
f"0x{instruction_addr:08X} {hex(opcode)}: {name} [MISSING OPERAND]"
)
ip += 1
else:
asm = name
disassembly_output.append(
f"0x{instruction_addr:08X} {hex(opcode)}: {asm}"
)
ip += 1
else:
disassembly_output.append(
f"0x{ip*4:08X} {hex(opcode)}: DATA/UNKNOWN {hex(opcode)}"
)
ip += 1
return "\n".join(disassembly_output)
def run(self, max_steps=10000):
"""执行虚拟机代码,仅实现部分关键逻辑以供演示"""
ip = 0
steps = 0
while 0 <= ip < len(self.text) and steps < max_steps:
opcode = self.text[ip]
_ip_value = ip + 1
steps += 1
try:
if opcode == 0x104:
v6 = self.text[_ip_value]
ip = _ip_value + 1
self.env.push(v6)
elif opcode == 0x304:
offset = self.env.pop()
data_index = self.env.get_data_addr(offset)
v19 = self.text[
data_index // 4
]
self.env.push(v19)
ip = _ip_value
elif opcode == 0x301:
v19 = self.env.pop() + 1
self.env.push(v19)
ip = _ip_value
elif opcode == 0x404:
v16 = self.env.pop()
value = self.env.pop()
data_index = self.env.get_data_addr(v16)
self.text[data_index // 4] = value
ip = _ip_value
elif opcode == 0x203:
jump_target_word = self.text[_ip_value]
ip = jump_target_word >> 2
elif opcode == 0x403:
jump_target_word = self.text[_ip_value]
ip = _ip_value + 1
if self.env.pop() != 0:
ip = jump_target_word >> 2
else:
info = self.OPCODE_MAP.get(opcode)
if info and info[1] == 1:
ip += 2
else:
ip += 1
except IndexError as e:
print(f"\n[EXECUTION ERROR] {e} at instruction {hex(ip*4)}")
break
print(f"\nExecution finished after {steps} steps.")
vm_bytecode = [
0x104,
0x118,
0x305,
0x104,
0x0,
0x104,
0x0,
0x404,
0x104,
0x2F,
0x104,
0x0,
0x304,
0x201,
0x303,
0xD4,
0x104,
0x18,
0x104,
0x0,
0x304,
0x101,
0x504,
0x104,
0x10,
0x104,
0x0,
0x304,
0x104,
0x7,
0x102,
0x101,
0x504,
0x402,
0x104,
0x118,
0x104,
0x0,
0x304,
0x101,
0x504,
0x201,
0x403,
0xD4,
0x104,
0x0,
0x304,
0x301,
0x104,
0x0,
0x404,
0x203,
0x20,
0x104,
0x2F,
0x104,
0x0,
0x304,
0x201,
0x403,
0x104,
0x104,
0x218,
0x405,
0x103,
0x104,
0x21C,
0x405,
0x103,
]
DATA_BASE_ADDR_SIMULATION = 0x1000
VM_START_ADDR = 0x408254
my_vm = VM(vm_bytecode, DATA_BASE_ADDR_SIMULATION)
print(my_vm.disassemble())
|